 SRE文档
SRE文档1. 说说看Nginx是如何处理请求的?
当客户端发起一个请求时,Nginx的工作进程会监听网络端口,接收客户端的连接请求。以下是Nginx处理请求的具体流程:
接收连接请求:Nginx接收到客户端的连接请求后,会为该连接分配一个连接对象(ngx_connection_t)。连接对象包含连接的状态信息、读写事件处理器等。
读取请求头信息:Nginx从客户端读取请求头信息。请求头包含HTTP方法(如GET、POST)、URL、HTTP版本以及各种请求头字段(如Host、User-Agent、Content-Length等)。
解析请求头信息:Nginx解析请求头信息,提取必要的参数,如请求方法、URI、Host等。解析后的请求头信息存储在ngx_http_request_t结构体中。
查找匹配的虚拟主机和location块:
- Nginx根据请求头中的Host字段查找匹配的虚拟主机(server块)。每个虚拟主机可以配置不同的域名和监听端口。
- 在找到匹配的虚拟主机后,Nginx继续查找与请求URI匹配的location块。location块定义了如何处理特定路径的请求。
执行处理阶段:Nginx的请求处理分为多个阶段,每个阶段可以由多个模块处理。这些阶段包括:
rewrite phase
执行重写规则,如URL重写。
post rewrite phase
处理重写后的请求。
preaccess phase
执行访问控制前的检查,如IP地址过滤。
access phase
执行访问控制,如身份验证。
postaccess phase
访问权限控制后的处理。
try-files
尝试访问文件或目录。
content phase
生成响应内容,如静态文件服务、反向代理、FastCGI等。在这个阶段,Nginx根据配置生成响应内容,这可能涉及读取静态文件、调用后端服务(如反向代理、FastCGI、uWSGI等)、生成动态内容等。
生成并发送响应:
- Nginx将生成的响应头发送回客户端。响应头包含HTTP状态码、响应头字段(如Content-Type、Content-Length等)。
- Nginx将生成的响应体发送回客户端。响应体可以是静态文件内容、后端服务返回的数据等。
关闭连接:一旦响应发送完毕,Nginx会关闭连接。如果启用了keep-alive连接,则连接可以保持打开状态,用于后续请求。
2.说说看Nginx的进程架构是怎样的?为什么Nginx不使用多线程模型?
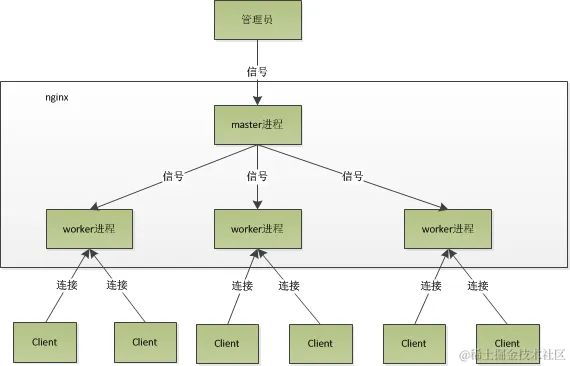
进程模型
Nginx采用Master-Worker多进程架构,这种架构的设计可以确保责任分离,以便更好地管理系统资源、并发请求处理与故障恢复。
- Master-Worker架构:
- 主进程(Master Process)
- Nginx的核心组件,负责初始化Nginx、加载配置文件、创建Worker进程等。
- 监听配置文件的变更,并在不重启的情况下重新加载配置。
- 管理Worker进程的生命周期,包括启动、停止和管理Worker进程。
- 不直接处理客户端的请求,而是用于控制和管理Worker进程。
- 工作进程(Worker Process)
- Nginx的工作进程,负责处理客户端的请求。
- 每个Worker进程都是一个完整的Nginx服务器,多个Worker进程之间是对等的。
- 每个Worker进程可以处理成千上万的并发连接,Nginx的事件模型可以根据系统负载自动选择合适的事件通知机制(如epoll)。
- 主进程(Master Process)
- 进程间协作:
- Master进程和Worker进程之间通过信号和共享内存进行通信。Master进程会向Worker进程发送信号以管理它们的生命周期(如启动、停止、重启等)。
- Worker进程之间通过共享内存和进程间通信(IPC)机制进行必要的数据共享和同步。
- 负载均衡:
- Nginx通过多进程模型实现了负载均衡。当有新的客户端连接请求到达时,这些连接会被平均分配给各个Worker进程,从而实现负载均衡。这种设计确保了Nginx能够高效地处理大量并发连接,避免了单个进程成为瓶颈。
- 高可用性:
- Nginx的多进程模型还提供了高可用性。当一个Worker进程出现故障时,Master进程会自动重新启动一个新的Worker进程来替代原来的进程,从而保证服务器的高可用性。这种设计使得Nginx能够在高负载和复杂环境下稳定运行。
为什么Nginx不使用多线程模型?
Nginx选择不使用多线程模型,而是采用多进程加异步非阻塞I/O的事件驱动模型,主要基于以下几个原因:
- 资源隔离与稳定性
- 多进程模型下,每个工作进程都是独立的,它们之间不会共享内存空间(除了通过共享内存等特定机制进行通信)。这种隔离性使得一个工作进程的崩溃不会影响到其他进程,从而提高了整个系统的稳定性。
- 在多线程模型中,线程之间共享进程的内存空间,这可能导致线程间的数据竞争、死锁等问题,增加了系统的复杂性和调试难度。
- 利用多核CPU
- Nginx的多进程模型可以很好地利用现代操作系统提供的进程调度机制,将工作进程分配到不同的CPU核心上运行,从而实现并行处理。
- 虽然多线程模型也可以利用多核CPU,但线程的创建、切换和同步开销通常比进程更高,尤其是在高并发场景下。
- 避免线程竞争和死锁
- 在多线程模型中,多个线程可能同时访问共享资源(如内存、文件等),这需要使用锁机制来确保数据的一致性和安全性。然而,锁的使用往往会导致线程竞争和死锁问题,降低系统的性能。
- Nginx通过采用异步非阻塞I/O和事件驱动模型,避免了锁的使用,从而减少了线程竞争和死锁的风险。
- 简化编程模型
- Nginx的多进程加异步非阻塞I/O模型相对简单明了,开发者可以更容易地理解和维护代码。
- 多线程编程往往涉及复杂的线程同步和通信机制,增加了编程的复杂性和出错的可能性。
- 设计初衷
- Nginx的设计初衷就是为了提供一个高性能、低资源消耗的Web服务器和反向代理服务器。在设计之初,Nginx的开发者就选择了多进程加异步非阻塞I/O的模型,并一直沿用至今。
- Nginx的社区和开发者群体也倾向于保持这种设计哲学,以确保Nginx的稳定性和性能优势。
3.什么是正向代理和反向代理?Nginx如何实现正向代理和反向代理功能?
反向代理功能是指代理服务器接受互联网上的连接请求,然后将这些请求转发给内部网络上的服务器,并将从内部服务器上得到的响应返回给互联网上请求连接的客户端。在这个过程中,代理服务器在外部世界中显示为服务器。
一般来说反向代理中代理服务器和后台服务是一伙儿的,绑定在一起。客户端不知道自己实际请求的到底是谁。

现实中的反向代理例子有:负载均衡服务器、网络安全防护(防DDoS攻击) 和内容分发网络 CDN等
Nginx实现反向代理功能主要通过配置Nginx服务器,使其成为客户端和目标服务器之间的中介。以下是Nginx实现反向代理功能的具体步骤和要点:
- 配置Nginx:
- Nginx的反向代理配置主要在nginx.conf文件中进行,或者在包含的子配置文件中进行。
- 监听端口:设置Nginx监听的端口,默认为80端口,用于接收HTTP请求。
- 服务器名称:定义Nginx服务器响应的域名。
- location块:根据请求的URI进行匹配,并定义相应的操作,如反向代理。
- 反向代理指令(proxy_pass):指定请求应被转发到的后端服务器的URL。
http {
server {
listen 80; # 监听80端口
server_name example.com; # 服务器名称
location / {
proxy_pass http://backend-server:8080; # 后端服务器地址与端口
proxy_set_header Host $host; # 保留原始Host头
proxy_set_header X-Real-IP $remote_addr; # 传递真实客户端IP
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme; # 传递请求协议(http/https)
# 其他可选配置,如缓存、超时、重试等
}
}
}
http {
server {
listen 80; # 监听80端口
server_name example.com; # 服务器名称
location / {
proxy_pass http://backend-server:8080; # 后端服务器地址与端口
proxy_set_header Host $host; # 保留原始Host头
proxy_set_header X-Real-IP $remote_addr; # 传递真实客户端IP
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme; # 传递请求协议(http/https)
# 其他可选配置,如缓存、超时、重试等
}
}
}正向代理用于将客户端的请求转发到目标服务器,并将服务器的响应返回给客户端。在这种方式下,客户端将请求发送给代理服务器,由代理服务器代替客户端向目标服务器发出请求,并将目标服务器的响应返回给客户端。通过正向代理,客户端可以直接访问外部网络,而无需直接与目标服务器建立连接。

现实中的正向代理例子有:VPN
方式:
server {
listen 3128; # 监听端口
resolver 114.114.114.114; # DNS解析器
proxy_connect; # 允许CONNECT请求
proxy_connect_allow 443 563; # 允许连接的端口
proxy_connect_connect_timeout 10s; # 连接超时时间
proxy_connect_data_timeout 10s; # 数据传输超时时间
location / {
proxy_pass http://$host; # 转发请求到目标服务器
proxy_set_header Host $host; # 设置请求头
}
}server {
listen 3128; # 监听端口
resolver 114.114.114.114; # DNS解析器
proxy_connect; # 允许CONNECT请求
proxy_connect_allow 443 563; # 允许连接的端口
proxy_connect_connect_timeout 10s; # 连接超时时间
proxy_connect_data_timeout 10s; # 数据传输超时时间
location / {
proxy_pass http://$host; # 转发请求到目标服务器
proxy_set_header Host $host; # 设置请求头
}
}4.什么是动态资源、静态资源分离?为什么要做动、静分离?Nginx怎么做的动静分离?
动态资源与静态资源分离(简称动、静分离)是一种常见的Web应用架构模式
动态资源与静态资源
静态资源
当用户多次访问某个资源时,如果资源的源代码不会发生改变,那么该资源就被称为静态资源。常见的静态资源包括图片(img)、样式表(css)、脚本文件(js)、视频(mp4)等。这些资源通常可以被浏览器和CDN(内容分发网络)缓存,以减少对服务器的重复请求。
动态资源
当用户多次访问某个资源时,如果资源的源代码可能会发生变化,那么该资源就被称为动态资源。常见的动态资源包括JSP、FTL等服务器端脚本或模板文件。这些资源通常需要根据用户的请求动态生成响应内容。
动、静分离的原因
性能优化
动态内容和静态内容在处理和分发上存在差异。将它们分离可以分别进行优化,从而提高整体性能。例如,静态资源可以由专门的静态资源服务器(如Nginx)直接处理和提供,而动态资源则由应用服务器处理。这样可以显著减少对动态资源服务器的请求量,降低其负载。
缓存管理
静态资源易于被缓存,而动态资源通常不适宜缓存或需要更精细的缓存控制。通过动、静分离,可以更好地管理缓存策略,提高缓存命中率,减少服务器响应时间和带宽消耗。
负载均衡
分离后,可以根据内容类型对资源进行优化分配,实现更有效的负载均衡。例如,可以根据动态资源的访问量和特点,针对性地增加动态资源服务器的数量和规模,以应对高并发的访问需求。
安全性增强
静态内容服务器通常不需要执行复杂的程序代码,因此攻击面较小,可以降低安全风险。将其与执行动态代码的服务器分离可以降低潜在的安全威胁。
静态配置方式:
server {
listen 80;
server_name www.example.com;
# 静态资源处理
location /static/ {
root /var/www/example;
}
location /images/ {
root /var/www/example;
}
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
root /var/www/example;
expires 30d; # 设置静态资源的缓存过期时间
add_header Cache-Control "public"; # 添加Cache-Control头部,强化浏览器缓存行为
}
}server {
listen 80;
server_name www.example.com;
# 静态资源处理
location /static/ {
root /var/www/example;
}
location /images/ {
root /var/www/example;
}
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
root /var/www/example;
expires 30d; # 设置静态资源的缓存过期时间
add_header Cache-Control "public"; # 添加Cache-Control头部,强化浏览器缓存行为
}
}注意事项
Nginx的location匹配优先级
Nginx的
location匹配遵循特定的优先级规则,包括精确匹配(使用=符号)、正则表达式匹配(使用~或~*)、前缀匹配(普通location)。在配置多个location块时,需要谨慎考虑它们之间的优先级关系,以确保正确的请求路由。缓存策略
通过合理配置缓存,可以显著提高网站性能。Nginx提供了强大而灵活的缓存功能,可以通过
proxy_cache_path和proxy_cache指令来实现。对于静态资源,可以设置较长的缓存过期时间,以减少对服务器的重复请求。安全性
通过动静分离,可以将静态内容服务器与执行动态代码的服务器分离,从而降低安全风险。静态内容服务器通常不需要执行复杂的程序代码,因此攻击面较小。
5.Nginx负载均衡的算法策略有哪些?
1. 轮询(Round Robin)
- 原理:轮询算法按照服务器列表的顺序依次分发请求。当一个新的请求到达时,Nginx会将其分配给列表中的下一个服务器,如果到达列表末尾,则重新开始循环。
- 特点:
- 简单易用,无需额外配置。
- 适用于后端服务器性能相近的情况,因为每个服务器都会轮流接收到请求。
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}2. 加权轮询(Weighted Round Robin)
- 原理:在轮询的基础上,为每个服务器分配一个权重值。权重值越高的服务器,接收到的请求越多。Nginx会根据权重值来计算每个服务器接收请求的比例。
- 特点:
- 考虑了服务器性能的差异,可以灵活分配请求。
- 需要手动配置权重值,以反映服务器的实际性能。
- 适用于后端服务器性能不均衡的情况,可以更好地利用服务器资源。
http {
upstream backend {
server backend1.example.com weight=3;
server backend2.example.com weight=2;
server backend3.example.com weight=1;
}
server {
location / {
proxy_pass http://backend;
}
}
}http {
upstream backend {
server backend1.example.com weight=3;
server backend2.example.com weight=2;
server backend3.example.com weight=1;
}
server {
location / {
proxy_pass http://backend;
}
}
}3. IP哈希(IP Hash)
- 原理:根据客户端IP地址的哈希值来分配请求。Nginx会计算每个客户端IP地址的哈希值,并使用该哈希值来选择后端服务器。由于相同IP地址的哈希值相同,因此来自同一IP地址的请求总是被分配到同一台后端服务器。
- 特点:
- 实现了会话粘性(Session Persistence),即同一个客户端的请求总是被分配到同一台后端服务器。
- 适用于需要保持会话一致性的场景,如购物车、用户会话等。
- 但可能导致负载分布不均衡,因为某些IP地址范围内的客户端可能会频繁访问同一台服务器。
http {
upstream backend {
ip_hash;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}http {
upstream backend {
ip_hash;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}4. 最少连接(Least Connections)
- 原理:将请求分发到当前连接数最少的服务器上。Nginx会监控每台后端服务器的当前连接数,并将新请求分配给连接数最少的服务器。
- 特点:
- 考虑了服务器的当前负载情况,可以更有效地平衡负载。
- 适用于长连接场景,如WebSocket、数据库连接等。
- 但需要Nginx维护连接状态,可能会增加一些开销。
- Nginx本身不直接支持此策略,通常需要借助第三方模块或自定义脚本实现。
http {
upstream backend {
least_conn;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}http {
upstream backend {
least_conn;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}5. Fair(第三方)
- 原理:根据后端服务器的响应时间来分配请求。Nginx会监控每台后端服务器的响应时间,并将新请求分配给响应时间最短的服务器。
- 特点:
- 实现了更智能的负载均衡,可以根据服务器的实际性能来分配请求。
- 适用于对响应时间要求较高的场景。
- 但需要安装第三方模块(如nginx-module-vts)来实现。
6. URL哈希(URL Hash,第三方)
- 原理:根据请求URL的哈希值来分配请求。Nginx会计算每个请求URL的哈希值,并使用该哈希值来选择后端服务器。由于相同URL的哈希值相同,因此相同URL的请求总是被分配到同一台后端服务器。
- 特点:
- 提高了缓存的命中率,因为相同URL的请求总是被分配到同一台后端服务器。
- 适用于缓存服务器集群。
- 但同样可能导致负载分布不均衡。
- Nginx本身不支持此策略,需要安装Nginx的hash软件包来实现。
http {
upstream backend {
hash $request_uri consistent; # 假设有一个支持URL哈希的第三方模块
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}
http {
upstream backend {
hash $request_uri consistent; # 假设有一个支持URL哈希的第三方模块
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
location / {
proxy_pass http://backend;
}
}
}6.Nginx和Apache(在性能上)的区别是什么?
Nginx和Apache在性能上的区别主要体现在以下几个方面:
一、并发连接处理能力
- Nginx
- Nginx采用了事件驱动的异步非阻塞架构,这种设计使得Nginx能够高效地处理大量并发连接。
- Nginx在处理并发连接时,资源消耗较低,能够保持较高的性能和稳定性。
- Apache
- Apache使用基于进程或线程的模型来处理请求,每个请求通常会创建一个独立的进程或线程。
- 在处理大量并发连接时,Apache可能会因为创建过多的进程或线程而导致资源消耗增加,进而影响性能。
二、内存消耗
- Nginx
- Nginx的架构更为轻量化,代码量较少,因此通常比Apache消耗更少的内存。
- 这种低内存消耗的特性使得Nginx在处理大量请求时更为高效。
- Apache
- 相较于Nginx,Apache的内存消耗可能会更高,尤其是在处理大量并发连接时。
- 不过,Apache的内存消耗也取决于其配置和加载的模块数量。
三、静态文件处理
- Nginx
- Nginx在处理静态文件时表现非常出色,能够高效地提供静态内容。
- Nginx的静态文件处理能力得益于其高效的I/O处理机制和优化的内存管理。
- Apache
- 虽然Apache也能处理静态文件,但相比之下,其性能可能稍逊于Nginx。
- Apache在处理静态文件时可能需要更多的资源,尤其是在高并发场景下。
四、动态内容处理
- Nginx
- Nginx本身并不擅长处理动态内容,但可以通过配置反向代理和负载均衡等功能,将动态内容处理的请求转发给后端的应用服务器。
- Nginx也支持一些模块来处理简单的动态内容,但功能相对有限。
- Apache
- Apache在处理动态内容方面更具优势,因为它支持多种编程语言和模块扩展。
- Apache可以通过加载不同的模块来支持不同的动态内容处理需求,如PHP、Python等。
7.如何用Nginx解决前端跨域问题?
前端跨域问题是指浏览器出于安全考虑,限制从一个域的网页直接访问另一个域中的资源,从而导致AJAX请求失败。Nginx可以通过配置HTTP响应头来解决前端跨域问题。
以下是用Nginx解决前端跨域问题的详细步骤:
一、理解CORS和同源策略
CORS(Cross-Origin Resource Sharing,跨源资源共享)和同源策略是Web安全领域中两个重要的概念,它们在处理跨域请求时起着至关重要的作用。以下是对这两个概念的详细解释:
同源策略(Same-Origin Policy)
定义: 同源策略是一种安全机制,用于防止不同来源的文档或脚本相互干扰。它基于域名、协议和端口来定义一个“源”,只有当两个URL具有相同的协议、主机名和端口号时,它们才被认为是同源的。
限制:
DOM访问限制
一个页面中的脚本不能读取或操作另一个页面的内容。
Cookie限制
一个页面中的脚本不能访问另一个页面的Cookie。
AJAX请求限制
一个页面中的脚本不能向另一个域名发送AJAX请求。
目的: 这种策略的目的是防止恶意网站窃取数据,例如,防止一个网站通过JavaScript访问另一个网站的用户数据。
CORS(跨源资源共享)
定义: CORS是一种机制,它使用额外的HTTP头来告诉浏览器允许来自不同源的Web应用访问该资源。通过配置CORS,服务器可以指定哪些源可以访问其资源,以及允许哪些类型的请求方法(如GET、POST等)。
工作原理:
预检请求(Preflight Request)
对于某些类型的请求(如PUT、DELETE等),浏览器会先发送一个OPTIONS请求到服务器,询问服务器是否允许实际的请求。这个过程称为预检请求。
响应头
服务器通过设置特定的HTTP响应头来表明是否允许跨域请求。这些响应头包括Access-Control-Allow-Origin、Access-Control-Allow-Methods、Access-Control-Allow-Headers等。
实际请求
如果预检请求被批准,浏览器将发送实际的请求。
二、Nginx配置CORS
Nginx可以通过配置HTTP响应头来支持CORS。这些头信息包括Access-Control-Allow-Origin、Access-Control-Allow-Methods、Access-Control-Allow-Headers和Access-Control-Allow-Credentials等。
找到或创建Nginx的配置文件
:通常位于
/etc/nginx/nginx.conf或/etc/nginx/conf.d/目录中。在需要跨域的server块或location块中添加CORS相关的头部配置
以下是一个配置示例:
bashserver { listen 80; server_name api.example.com; location / { # 设置允许跨域的域名,可以使用通配符'*'允许所有域访问 add_header 'Access-Control-Allow-Origin' 'http://www.example.com'; # 设置允许的HTTP方法 add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, DELETE, PUT'; # 设置允许的请求头 add_header 'Access-Control-Allow-Headers' 'Authorization, Content-Type, Accept, Origin, X-Requested-With'; # 如果需要支持cookie,可以设置以下header add_header 'Access-Control-Allow-Credentials' 'true'; # 如果是预检请求(OPTIONS请求),则直接返回204状态码 if ($request_method = 'OPTIONS') { return 204; } # 其他正常请求的处理逻辑 proxy_pass http://backend_server; } }server { listen 80; server_name api.example.com; location / { # 设置允许跨域的域名,可以使用通配符'*'允许所有域访问 add_header 'Access-Control-Allow-Origin' 'http://www.example.com'; # 设置允许的HTTP方法 add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, DELETE, PUT'; # 设置允许的请求头 add_header 'Access-Control-Allow-Headers' 'Authorization, Content-Type, Accept, Origin, X-Requested-With'; # 如果需要支持cookie,可以设置以下header add_header 'Access-Control-Allow-Credentials' 'true'; # 如果是预检请求(OPTIONS请求),则直接返回204状态码 if ($request_method = 'OPTIONS') { return 204; } # 其他正常请求的处理逻辑 proxy_pass http://backend_server; } }在上述配置中:
Access-Control-Allow-OriginAccess-Control-Allow-Origin指定允许跨域请求的来源。可以设置为具体的域名(如
http://www.example.com),或使用通配符*允许所有来源。但需要注意,使用通配符时,不允许设置Access-Control-Allow-Credentials为true。Access-Control-Allow-MethodsAccess-Control-Allow-Methods指定允许的HTTP请求方法,如GET、POST、OPTIONS、PUT、DELETE等。
Access-Control-Allow-HeadersAccess-Control-Allow-Headers指定允许客户端发送的自定义HTTP头部,如Authorization、Content-Type等。
Access-Control-Allow-CredentialsAccess-Control-Allow-Credentials如果客户端请求包括凭据(如Cookies),则该选项必须设置为
true。此时Access-Control-Allow-Origin不能为*,必须为具体的域名。
三、处理预检请求
预检请求是CORS规范中定义的一种机制,用于在实际请求之前探测服务器是否允许某个跨域请求。浏览器在发送某些复杂请求之前,会发送一个OPTIONS请求进行预检,询问服务器是否允许该请求。Nginx可以通过简单的配置处理这种预检请求,例如:
location / {
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, PUT, DELETE';
add_header 'Access-Control-Allow-Headers' 'Content-Type, Authorization';
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Max-Age' 3600;
return 204;
}
# 其余配置...
}
location / {
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, PUT, DELETE';
add_header 'Access-Control-Allow-Headers' 'Content-Type, Authorization';
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Max-Age' 3600;
return 204;
}
# 其余配置...
}四、配置通配符和动态设置
配置通配符
:在某些场景中,如果需要允许所有域访问(即不限制跨域请求的来源),可以将
Access-Control-Allow-Origin设置为*。但如前所述,此时不能同时启用Access-Control-Allow-Credentials。动态设置
:如果需要根据请求动态设置
Access-Control-Allow-Origin,可以使用$http_origin变量来匹配请求来源。例如:bashlocation / { if ($http_origin ~* 'https?://(www\.)?(example1\.com|example2\.com)') { add_header 'Access-Control-Allow-Origin' "$http_origin"; add_header 'Access-Control-Allow-Credentials' 'true'; add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'Authorization, Content-Type, Accept'; } if ($request_method = 'OPTIONS') { return 204; } proxy_pass http://backend_server; }location / { if ($http_origin ~* 'https?://(www\.)?(example1\.com|example2\.com)') { add_header 'Access-Control-Allow-Origin' "$http_origin"; add_header 'Access-Control-Allow-Credentials' 'true'; add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'Authorization, Content-Type, Accept'; } if ($request_method = 'OPTIONS') { return 204; } proxy_pass http://backend_server; }
8.漏桶流算法和令牌桶算法知道吗?如何使用Nginx限流?
在限流中,有两个关键概念需要了解:阈值(一个单位时间内允许的请求量)和拒绝策略(超过阈值的请求的拒绝策略,常见的拒绝策略有直接拒绝、排队等待等)。
漏桶流算法和令牌桶算法是两种常见的限流算法,以下是这两种算法的具体介绍:
一、漏桶流算法(Leaky Bucket Algorithm)
工作原理:
- 漏桶算法可以看作是一个带有常量服务时间的单服务器队列。如果漏桶(包缓存)溢出,那么数据包会被丢弃。
- 漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。漏桶强制一个常量的输出速率,而不管输入数据流的突发性。
- 当数据包到达漏桶时,它们被放置在桶的底部。然后,数据包以固定的速率(漏出速率)从桶中漏出,注入网络。如果到达速率超过漏出速率,并且桶已满,则新的数据包将被丢弃。

- 优点:
- 保证严格的延迟界限,避免一切由缓冲区溢出引起的丢失。
- 网络可以容易地验证通信量是否符合规范。
- 应用场景:
- 漏桶算法适用于需要严格控制输出速率的场景,如网络流量整形。
二、令牌桶算法(Token Bucket Algorithm)
- 工作原理:
- 令牌桶算法使用一个虚拟的桶来存放令牌,每个令牌代表一个数据包的发送权限。
- 系统以固定的速率向桶中添加令牌,每当一个数据包发送时,就从桶中移除一个令牌。
- 如果桶中没有令牌,数据包则需要等待,直到有令牌可用。如果桶中的令牌数量超过其容量,则新生成的令牌会被丢弃。

- 优点:
- 允许一定程度的突发传输,同时限制长时间内的传输速率。
- 更灵活地处理流量,能够更好地利用网络资源。
- 应用场景:
- 令牌桶算法广泛应用于网络流量管理、API请求限流等场景。
三、漏桶流算法与令牌桶算法的比较
| 漏桶流算法 | 令牌桶算法 | |
|---|---|---|
| 工作原理 | 突发流量被整形为稳定流量,输出速率恒定 | 令牌生成速率恒定,数据包发送需消耗令牌 |
| 流量特性 | 强制限制数据传输速率,对突发流量缺乏效率 | 允许突发传输,同时限制平均传输速率 |
| 资源利用 | 在无拥塞时不能有效利用网络资源 | 能够更有效地利用网络资源 |
| 适用场景 | 网络流量整形 | 网络流量管理、API请求限流 |
在实际应用中,选择哪种限流算法取决于具体的需求和场景。例如,如果系统需要严格控制输出速率并避免突发流量,则漏桶算法可能更合适。而如果系统需要允许一定程度的突发传输,并希望更灵活地处理流量,则令牌桶算法可能更合适。
在Nginx中配置限流,主要通过limit_req和limit_conn两个模块来实现。以下是具体的配置方法:
limit_req模块基于令牌桶算法来限制每秒的请求次数。配置步骤如下:
定义限流区域:
在
http块中,使用limit_req_zone指令来定义一个限流区域。这个区域会存储在共享内存中,并用于跟踪请求的速率。
http {
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=1r/s;
...
}
http {
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=1r/s;
...
}这里,$binary_remote_addr是客户端IP地址的二进制表示,zone=mylimit:10m定义了一个名为mylimit的共享内存区域,大小为10MB,rate=1r/s设置了每秒的请求速率限制为1个请求。
应用限速规则:
server {
...
location / {
limit_req zone=mylimit burst=5 nodelay;
...
}
...
}
server {
...
location / {
limit_req zone=mylimit burst=5 nodelay;
...
}
...
}zone=mylimit指定了使用前面定义的mylimit区域,burst=5允许在超过速率限制后,突发处理最多5个请求,nodelay表示这些突发请求将立即处理,而不会等待新的令牌生成
二、使用limit_conn模块限制并发连接数
limit_conn模块用于限制同时连接数。配置步骤如下:
定义连接限制区域:
在
http块中,使用limit_conn_zone指令来定义一个连接限制区域。
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
...
}
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
...
}这里,$binary_remote_addr是客户端IP地址的二进制表示,zone=addr:10m定义了一个名为addr的共享内存区域,大小为10MB。
应用连接限制规则:
server {
...
location / {
limit_conn addr 10;
...
}
...
}
server {
...
location / {
limit_conn addr 10;
...
}
...
}三、其他限流配置
除了上述基本的限流配置外,Nginx还支持其他限流策略,如:
设置黑白名单
通过
ngx_http_geo_module和ngx_http_map_module模块,可以设置黑白名单来控制哪些客户端IP地址可以访问或禁止访问特定的资源或整个服务器。限制数据传输速度
使用
limit_rate和limit_rate_after指令,可以限制对特定位置(location)的响应速度。
9.Nginx怎么判断别的IP不可访问?
Nginx判断别的IP不可访问的功能,通常是通过其内置的ngx_http_access_module模块来实现的。该模块允许基于客户端的IP地址来允许或拒绝对网站资源的访问。
1. 基本配置指令
allow
允许指定的IP地址或IP地址段访问服务器。
deny
拒绝指定的IP地址或IP地址段访问服务器。
2. 配置位置
这些指令可以配置在http、server、location、limit_except等上下文中,从而对整个服务器、特定虚拟主机或特定资源进行访问控制。
3. 配置示例
拒绝单个IP地址
假设要拒绝IP地址为192.168.1.100的所有访问请求,可以在Nginx配置文件中使用以下配置:
server {
listen 80;
server_name example.com;
location / {
deny 192.168.1.100;
allow all;
}
}
server {
listen 80;
server_name example.com;
location / {
deny 192.168.1.100;
allow all;
}
}在这个配置中,所有来自192.168.1.100的请求将被拒绝,而其他IP地址的请求将被允许。
允许和拒绝的优先级
在Nginx中,allow和deny指令具有优先级。Nginx从上到下依次读取配置,当有多个allow和deny指令时,首先匹配到的规则会生效。通常情况下,deny指令在allow指令之前时,拒绝的优先级更高。例如:
server {
listen 80;
server_name example.com;
location / {
allow 192.168.1.0/24;
deny all;
}
}
server {
listen 80;
server_name example.com;
location / {
allow 192.168.1.0/24;
deny all;
}
}4. 基于HTTP头部的IP信息
在某些情况下,客户端的真实IP地址可能被隐藏在HTTP头部中,如通过反向代理服务器时。在这种情况下,需要基于HTTP头部中的IP信息来进行访问控制。常见的HTTP头部字段包括X-Forwarded-For和X-Real-IP。可以通过$http_x_forwarded_for变量来获取该IP信息,并结合if语句进行访问控制。例如:
server {
listen 80;
server_name example.com;
location / {
if ($http_x_forwarded_for = "192.168.1.100") {
return 403;
}
proxy_pass http://backend;
}
}
server {
listen 80;
server_name example.com;
location / {
if ($http_x_forwarded_for = "192.168.1.100") {
return 403;
}
proxy_pass http://backend;
}
}在这个配置中,如果请求的X-Forwarded-For头部中包含192.168.1.100,则Nginx会返回403禁止访问的状态码。
10.Nginx如何实现后端服务的健康检查?
Nginx本身不直接提供内置的后端服务健康检查功能,但可以通过一些模块和配置实现类似的效果。以下是一些常见的方法:
1. 使用 ngx_http_upstream_check_module 模块
ngx_http_upstream_check_module 是一个第三方模块,用于对后端服务进行健康检查。它需要在编译 Nginx 时包含这个模块。
安装和配置示例:
编译 Nginx 并包含
ngx_http_upstream_check_module:下载 Nginx 源代码并编译:
wget http://nginx.org/download/nginx-<version>.tar.gz tar -zxvf nginx-<version>.tar.gz cd nginx-<version>/ # 添加 --add-module 参数来包含第三方模块 ./configure --add-module=/path/to/ngx_http_upstream_check_module --prefix=/usr/local/nginx make sudo make installwget http://nginx.org/download/nginx-<version>.tar.gz tar -zxvf nginx-<version>.tar.gz cd nginx-<version>/ # 添加 --add-module 参数来包含第三方模块 ./configure --add-module=/path/to/ngx_http_upstream_check_module --prefix=/usr/local/nginx make sudo make install配置 Nginx:
在 Nginx 配置文件中(通常是
/usr/local/nginx/conf/nginx.conf),添加健康检查配置:upstream backend { server backend1.example.com; server backend2.example.com; } server { listen 80; location / { proxy_pass http://backend; } # 健康检查配置 location /check { check interval=3000 rise=2 fall=3 timeout=2000 type=http; check_http_send "HEAD / HTTP/1.0\r\n\r\n"; check_http_expect_status 200-299; } }upstream backend { server backend1.example.com; server backend2.example.com; } server { listen 80; location / { proxy_pass http://backend; } # 健康检查配置 location /check { check interval=3000 rise=2 fall=3 timeout=2000 type=http; check_http_send "HEAD / HTTP/1.0\r\n\r\n"; check_http_expect_status 200-299; } }
Nginx会根据
/checklocation块中的配置,定期(每3000毫秒)向backend1.example.com和backend2.example.com发送HTTP HEAD请求进行健康检查。如果
backend1.example.com连续失败3次(fall=3)健康检查(每次检查超时时间为2000毫秒,且期望的HTTP状态码为200-299),则Nginx会将backend1.example.com标记为不健康。相反,如果
backend1.example.com在标记为不健康后连续成功2次(rise=2)健康检查,则它会被重新标记为健康。如果
backend1.example.com被标记为不健康,Nginx将只会将请求代理到backend2.example.com(假设它是健康的)。如果
backend2.example.com也变为不健康,那么Nginx将无法代理任何新的请求到该上游组,除非有服务器恢复健康或您添加了更多的服务器到上游组中。
11.什么是惊群效应,惊群效应消耗了什么,Nginx的惊群效应是如何发生的,又是如何应对的惊群效应?
惊群效应是一个在操作系统多线程或多进程环境中常见的现象。当多个线程或进程同时阻塞等待同一个事件(例如新连接的到来)时,如果该事件触发,系统可能会唤醒所有等待的线程或进程。然而,实际上只有一个线程或进程能够成功获取资源或处理事件,而其他被唤醒的线程或进程则会重新进入休眠状态。这种现象导致了资源的浪费,包括无效的上下文切换和调度,以及可能导致的缓存失效等问题。
对于 Nginx 的惊群问题,我们首先需要理解的是,在 Nginx 启动过程中,master 进程会监听配置文件中指定的各个端口,然后 master 进程就会调用 fork() 方法创建各个子进程,根据进程的工作原理,子进程是会继承父进程的全部内存数据以及监听的端口的,所以 worker 进程在启动之后也是会监听各个端口的。
当客户端有新建连接的请求到来时,就会触发各个 worker 进程的连接建立事件,但是只有一个 worker 进程能够正常处理该事件,而其他的 worker 进程会发现事件已经失效,从而重新循环进入等待状态。这种由于一个连接事件的到来而 “惊” 起了所有 worker 进程的现象就是Nginx的惊群问题。
Nginx的解决方案是:每个 worker 进程被创建的时候,都会调用 ngx_worker_process_init() 方法初始化当前 worker 进程,每个 worker 进程都会调用 epoll_create() 方法为自己创建一个独有的 epoll 句柄。
对于每一个需要监听的端口,都有一个文件描述符与之对应,而 worker 进程只有将该文件描述符通过 epoll_ctl() 方法添加到当前进程的 epoll 句柄中,并且监听 accept 事件,此时才会被客户端的连接建立事件触发。
基于这个原理,nginx 就使用了一个共享锁来控制当前进程是否有权限将需要监听的端口添加到当前进程的 epoll 句柄中。通过这种方式,就保证了每次事件发生时,只有一个 worker 进程会被触发。如下图所示为 worker 进程工作循环的一个示意图:
