 SRE文档
SRE文档POSTGRESQL体系结构数据库的结构理解
1. 概述
PostgreSQL官方介绍称是最先进的开源关系型数据库,支持所有主流的平台,目前已经更新到了最新版本的12.0,在MySQL被Oracle收购后,PostgreSQL开源社区越来越活跃了,同时还有分布式集群的开源方案GreenPlum,目前也非常受欢迎
2. PostgreSQL架构
PostgreSQL的物理结构是非常简单的,主要是由共享内存、后台进程和数据文件组成的。大致的结构可以参考下面的图。 椭圆形的都是进程,方形的都是内存结构,圆柱形的是文件
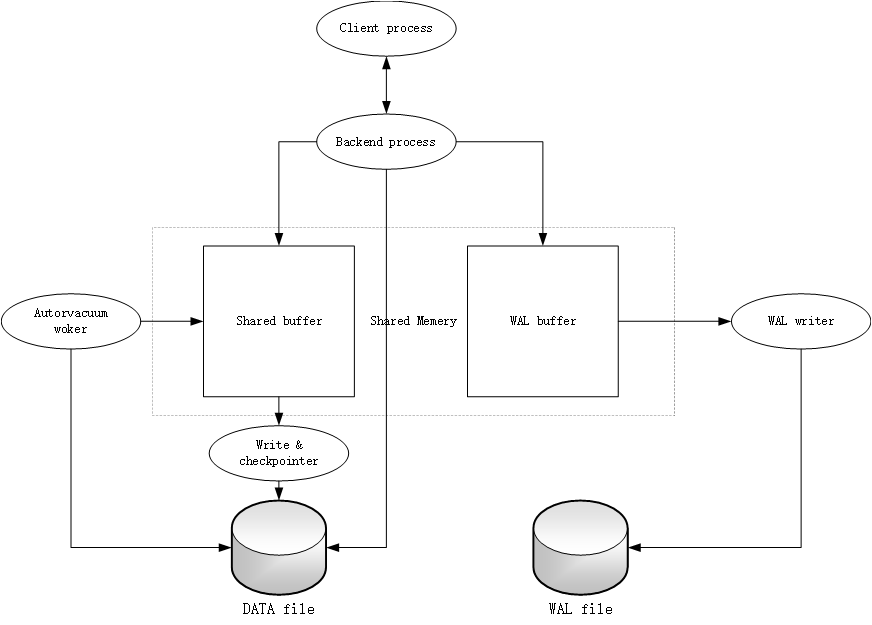
2.1 进程
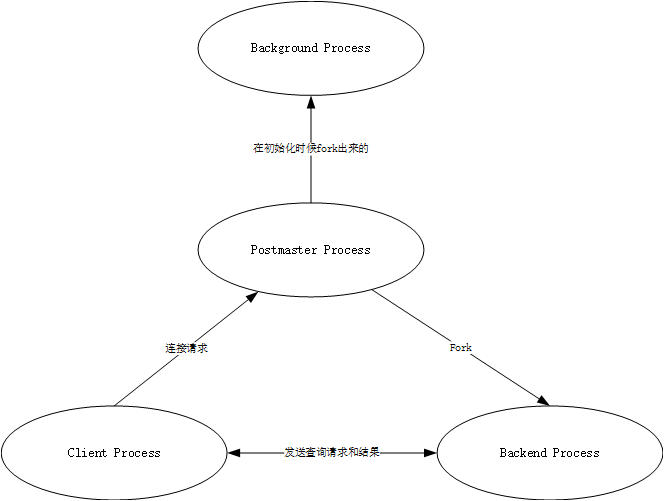
在启动数据库后,Postmaster是第一个启动的进程,在启动过程中,会进行恢复操作(如果有事务未正常提交或者回滚的话),初始化共享内存,启动后台进程等一系列的操作。当客户进程有一个连接请求时,会创建相对应的后台进程处理。过程如下:
ps -ef|grep postgres
postgres 19572 1 0 08:58 ? 00:00:00 /data/apps/pgsql/12/bin/postmaster -D /data/pgdata/data
postgres 19573 19572 0 08:58 ? 00:00:00 postgres: logger
postgres 19575 19572 0 08:58 ? 00:00:00 postgres: checkpointer
postgres 19576 19572 0 08:58 ? 00:00:00 postgres: background writer
postgres 19577 19572 0 08:58 ? 00:00:00 postgres: walwriter
postgres 19578 19572 0 08:58 ? 00:00:00 postgres: autovacuum launcher
postgres 19579 19572 0 08:58 ? 00:00:00 postgres: archiver last was 00000001000000000000001A
postgres 19580 19572 0 08:58 ? 00:00:00 postgres: stats collector
postgres 19581 19572 0 08:58 ? 00:00:00 postgres: logical replication launcherps -ef|grep postgres
postgres 19572 1 0 08:58 ? 00:00:00 /data/apps/pgsql/12/bin/postmaster -D /data/pgdata/data
postgres 19573 19572 0 08:58 ? 00:00:00 postgres: logger
postgres 19575 19572 0 08:58 ? 00:00:00 postgres: checkpointer
postgres 19576 19572 0 08:58 ? 00:00:00 postgres: background writer
postgres 19577 19572 0 08:58 ? 00:00:00 postgres: walwriter
postgres 19578 19572 0 08:58 ? 00:00:00 postgres: autovacuum launcher
postgres 19579 19572 0 08:58 ? 00:00:00 postgres: archiver last was 00000001000000000000001A
postgres 19580 19572 0 08:58 ? 00:00:00 postgres: stats collector
postgres 19581 19572 0 08:58 ? 00:00:00 postgres: logical replication launcher介绍一下各个进程
| 进程 | 详细描述 |
|---|---|
| postmaster | 整个数据库实例的总控进程,负责启动和关闭该数据库实例。 |
| logger process | 将数据库的日志写入到日志文件中 |
| checkpointer process | 当检查点发生时,脏缓存(指的是相对于原数据而言被修改过的)写入到文件中 |
| writer process | 周期性将脏缓存写入到文件中 |
| wal writer process | Write Ahead Log(预写式日志) |
| autovacuum launcher process | 如果autovacuum开启时,这个是一个周期性回收膨胀表标记为已删除数据的一个进程 |
| archiver process | 当开启归档模式,周期性将WAL日志写入到指定的目录 |
| stats collector process | 做数据的统计收集工作。主要用于查询优化时的代价估算,包括一个表和索引进行了多少次的插入、更新、删除操作,磁盘块读写的次数、行的读次数。pg_statistic中存储了该进程收集的各类信息。 |
| wal sender process replica | 在开启流复制的主备模式时,该进程周期性将WAL文件发送到另一台服务器作为数据同步备份 |
BgWriter(Background Writer)进程
BgWriter进程是将共享内存中的脏页写入磁盘的进程。它有两个功能:一个是周期性地从内存缓冲区中清除脏数据到磁盘,以减少在查询期间的阻塞;另一种情况是,PG需要在常规检查点期间将所有脏页写到磁盘。通过BgWriter提前写出一些脏页面,可以减少执行检查点(一种数据库恢复技术)时要执行的IO操作,从而使系统的IO负载趋于稳定。BgWriter是一个在PostgreSQL v8.0之后添加的进程,它在postgresql.conf中有一个专门的部分来配置它的行为
# - Background Writer -
#bgwriter_delay = 200ms # 10-10000ms between rounds
#bgwriter_lru_maxpages = 100 # max buffers written/round, 0 disables
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffers scanned/round
#bgwriter_flush_after = 512kB # measured in pages, 0 disables# - Background Writer -
#bgwriter_delay = 200ms # 10-10000ms between rounds
#bgwriter_lru_maxpages = 100 # max buffers written/round, 0 disables
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffers scanned/round
#bgwriter_flush_after = 512kB # measured in pages, 0 disableslbgwriter_delay:
在两次连续刷新数据之间的时间间隔。默认值是200,单位是毫秒
lbgwriter_lru_maxpages:
BgWriter进程每次写入的最大数据量。以buffers为单位,默认值为100。如果脏数据的量小于这个值,写操作全部由BgWriter进程完成;相反,如果它大于这个值,超过部分将由server process完成。当该值设为0时,表示BgWriter进程被禁用,完全由server process完成;当它被设置为-1时,意味着所有脏数据都由BgWriter进程完成。(这里不包括检查点操作)
lbgwriter_lru_multiplier:
此参数指示了每次写入磁盘的数据块数,当然,该值必须小于bgwriter_lru_maxpages。如果设置过小,需要写入的脏数据量大于每次写入的数据量,剩下的需要写入磁盘的工作,就需要server processes来完成,这将会降低性能。如果值配置太大,此时写入的脏数据量就会超过所需的缓冲区数量,这虽然便于以后再次应用缓冲区工作,但同时可能会出现IO浪费。这个参数的默认值是2.0
lbgwriter_flush_after:
当数据页大小达到bgwriter_flush_after时触发BgWriter,默认值为512KB
WalWriter进程
预写日志(也称为Xlog)的核心思想是,对数据文件的修改必须在这些修改被记录到日志中之后才发生,也就是说,在写入数据之前先写入日志。使用这种机制可以避免频繁地向磁盘写入数据,并可以减少磁盘I/O。数据库可以使用这些WAL日志在数据库重启后恢复数据库。WalWriter进程是一个后端进程,它负责确保WAL文件被正确写入磁盘,并且它的行为可以在postgresql.conf中设置以下参数进行配置
#-----------------------------------------------------------------------------
# WRITE-AHEAD LOG
#-----------------------------------------------------------------------------
# - Settings -
wal_level = logical # minimal, replica, or logical
# (change requires restart)
#fsync = on # flush data to disk for crash safety
# (turning this off can cause
# unrecoverable data corruption)#synchronous_commit = on
# synchronization level; # off, local, remote_write, remote_apply, or on
#wal_sync_method = fsync # the default is the first option
# supported by the operating system:
# open_datasync
# fdatasync (default on Linux)
# fsync
# fsync_writethrough
# open_sync
#full_page_writes = on # recover from partial page writes
#wal_compression = off # enable compression of full-page writes
#wal_log_hints = off # also do full page writes of non-critical updates
# (change requires restart)#wal_init_zero = on # zero-fill new WAL files
#wal_recycle = on # recycle WAL files
#wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers
# (change requires restart)#wal_writer_delay = 200ms # 1-10000 milliseconds
#wal_writer_flush_after = 1MB # measured in pages, 0 disables
#commit_delay = 0 # range 0-100000, in microseconds
#commit_siblings = 5 # range 1-1000#-----------------------------------------------------------------------------
# WRITE-AHEAD LOG
#-----------------------------------------------------------------------------
# - Settings -
wal_level = logical # minimal, replica, or logical
# (change requires restart)
#fsync = on # flush data to disk for crash safety
# (turning this off can cause
# unrecoverable data corruption)#synchronous_commit = on
# synchronization level; # off, local, remote_write, remote_apply, or on
#wal_sync_method = fsync # the default is the first option
# supported by the operating system:
# open_datasync
# fdatasync (default on Linux)
# fsync
# fsync_writethrough
# open_sync
#full_page_writes = on # recover from partial page writes
#wal_compression = off # enable compression of full-page writes
#wal_log_hints = off # also do full page writes of non-critical updates
# (change requires restart)#wal_init_zero = on # zero-fill new WAL files
#wal_recycle = on # recycle WAL files
#wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers
# (change requires restart)#wal_writer_delay = 200ms # 1-10000 milliseconds
#wal_writer_flush_after = 1MB # measured in pages, 0 disables
#commit_delay = 0 # range 0-100000, in microseconds
#commit_siblings = 5 # range 1-1000lwal_level:
控制wal存储的级别。wal_level确定有多少信息被写入到WAL。默认值是replica,它添加了WAL归档信息,包括只读服务器(流复制)所需的信息。还可以将其设置为minimal,即只写入从崩溃或立即关闭中恢复所需的信息。设置为Logical允许在逻辑解码场景中完成WAL流。
lfsync:
这个参数直接控制日志是否先写到磁盘。默认值为ON(先写),这意味着系统应该通过发出wal_sync_method设置的fsync指令,来确保更改确实被刷新到磁盘。虽然关闭fsync通常可以提高性能,但在电源故障或系统崩溃时,这会导致不可恢复的数据损坏。因此,只有当您可以轻松地从外部数据重新创建整个数据库时,才建议关闭fsync。
lsynchronous_commit:
此参数用于配置系统是否等待WAL完全完成后再将状态信息返回给用户事务。默认值为ON,表示必须等待WAL完成后才能返回事务状态信息;配置OFF可以更快地反馈事务状态。
lwal_sync_method:
这个参数控制WAL写入磁盘的fsync方法。默认值是fsync。可用的值包括open_datasync、fdatasync、fsync_writethrough、fsync、以及open_sync.open_datasync和open_sync。
lfull_page_writes:
指示是否将整个页面写入WAL。
lwal_buffers:
指示了用于存储WAL数据的内存空间量。系统默认值为64K。此参数还受wal_writer_delay和commit_delay这两个参数的影响。
lwal_writer_delay:
WalWriter进程的写入间隔。默认值是200毫秒。如果时间过长,可能会导致WAL缓冲区内存不足;如果时间太短,会导致WAL不断写入,增加磁盘I/O负担。
lwal_writer_flush_after:
当脏数据超过这个阈值时,它将被刷新到磁盘。
lcommit_delay:
指示在WAL buffer中存储已提交的数据的时间。默认值为0毫秒,表示没有延迟;
当它被设置为非零值时,在事务提交后,事务将不会被立即写入到WAL中,但它仍然存储在WAL buffer中,等待WalWriter进程定期写入磁盘。
lcommit_siblings:
当事务发出提交请求时,如果数据库中的事务数量大于commit_sibling的值,事务将等待一段时间(commit_delay值);否则,事务将直接写入到WAL。系统默认值是5,这个参数还确定了commit_delay的有效性
PgArch进程
与Oracle数据库中的ARCH归档过程类似,区别在于ARCH对重做日志执行归档,而PgArch对WAL日志执行归档。这是必要的,因为WAL日志是会被回收的。换句话说,过去的WAL日志会被新生成的日志覆盖。PgArch进程负责在覆盖WAL日志之前对其进行备份。从版本8.x开始,这些WAL日志可以用于PITR(基于时间点恢复),PITR将数据库状态恢复到特定时间段的特定状态。PgArch在postgresql.conf中也有专门的部分来配置它的行为
# - Archiving -
#archive_mode = off # enables archiving; off, on, or always
# (change requires restart)
#archive_command = '' # command to use to archive a logfile segment
# placeholders: %p = path of file to archive
# %f = file name only
# e.g. 'test ! -f /mnt/server/archivedir/%f && cp %p
/mnt/server/archivedir/%f'
#archive_timeout = 0 # force a logfile segment switch after this
# number of seconds; 0 disables# - Archiving -
#archive_mode = off # enables archiving; off, on, or always
# (change requires restart)
#archive_command = '' # command to use to archive a logfile segment
# placeholders: %p = path of file to archive
# %f = file name only
# e.g. 'test ! -f /mnt/server/archivedir/%f && cp %p
/mnt/server/archivedir/%f'
#archive_timeout = 0 # force a logfile segment switch after this
# number of seconds; 0 disableslarchive_mode:
指示是否执行存档操作;可以设置为(off), (on)或(always),默认值是off。
larchive_command:
管理员为归档WAL日志而设置的命令。在归档命令中,使用预定义变量%p来引用需要存档的WAL完整路径文件名,而%f表示没有路径的文件名(这里的路径是相对于当前工作目录的)。当归档每个WAL segment file时,将执行由archive_command指定的命令。如果archive命令返回0,PostgreSQL会认为文件已成功归档,然后删除或回收WAL segment file。如果返回一个非零值,PostgreSQL会认为该文件没有成功存档,并会定期重试,直到成功为止。
larchive_timeout:
表示归档周期。当超过此参数设置的时间时,将强制切换WAL段。默认值为0(禁用本功能)
AutoVacuum 进程
在PostgreSQL数据库中,在对数据执行更新或删除操作后,数据库不会立即删除旧版本的数据。相反,数据将被PostgreSQL的多版本机制标记为删除。如果其他事务正在访问这些旧版本的数据,则有必要临时保留它们。在事务被提交后,就不再需要旧版本的数据(死元组),因此数据库需要清理它们以腾出空间。这一任务是通过AutoVacuum 进程来完成的,与AutoVacuum 进程有关的参数也位于postgresql.conf中
#-----------------------------------------------------------------------------
# AUTOVACUUM
#-----------------------------------------------------------------------------
#autovacuum = on # Enable autovacuum subprocess? 'on'
# requires track_counts to also be on.
#log_autovacuum_min_duration = -1 # -1 disables, 0 logs all actions and
# their durations, > 0 logs only
# actions running at least this number
# of milliseconds.
#autovacuum_max_workers = 3 # max number of autovacuum
subprocesses
# (change requires restart)
#autovacuum_naptime = 1min # time between autovacuum runs
#autovacuum_vacuum_threshold = 50 # min number of row updates before
# vacuum
#autovacuum_analyze_threshold = 50 # min number of row updates before
# analyze
#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
#autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
#autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum
# (change requires restart)
#autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age
# before forced vacuum
# (change requires restart)
#autovacuum_vacuum_cost_delay = 2ms # default vacuum cost delay for
# autovacuum, in milliseconds;
# -1 means use vacuum_cost_delay
#autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for
# autovacuum, -1 means use
# vacuum_cost_limi#-----------------------------------------------------------------------------
# AUTOVACUUM
#-----------------------------------------------------------------------------
#autovacuum = on # Enable autovacuum subprocess? 'on'
# requires track_counts to also be on.
#log_autovacuum_min_duration = -1 # -1 disables, 0 logs all actions and
# their durations, > 0 logs only
# actions running at least this number
# of milliseconds.
#autovacuum_max_workers = 3 # max number of autovacuum
subprocesses
# (change requires restart)
#autovacuum_naptime = 1min # time between autovacuum runs
#autovacuum_vacuum_threshold = 50 # min number of row updates before
# vacuum
#autovacuum_analyze_threshold = 50 # min number of row updates before
# analyze
#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
#autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
#autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum
# (change requires restart)
#autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age
# before forced vacuum
# (change requires restart)
#autovacuum_vacuum_cost_delay = 2ms # default vacuum cost delay for
# autovacuum, in milliseconds;
# -1 means use vacuum_cost_delay
#autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for
# autovacuum, -1 means use
# vacuum_cost_limilautovacuum:
是否自动启动autovacuum进程,默认值为on。
llog_autovacuum_min_duration:
此参数记录autovacuum的执行时间。当autovaccum的执行时间超过本参数值时,该事件将记录在日志中。默认值是-1,这意味着没有记录。
lautovacuum_max_workers:
设置autovacuum subprocesses的最大数量。
lautovacuum_naptime:
设置两个autovacuum processes之间的间隔时间。
lautovacuum_vacuum_threshold and autovacuum_analyze_threshold:
设置表中更新元组数量的阈值,如果更新元组数量超过这些值,则需要分别执行vacuum和analyze。
lautovacuum_vacuum_scale_factor and autovacuum_analyze_scale_factor:
设置表大小的scaling factor。
lautovacuum_freeze_max_age:
设置需要被强制清理的数据库的事务ID上限。
lautovacuum_vacuum_cost_delay:
在autovacuum process即将开始执行时,对执行清理成本进行评估。如果autovacuum_vacuum_cost_limit超出了设置的值,那么存在一个由autovacuum_vacuum_cost_delay参数设置的延迟。如果值为-1,则表示改用vacuum_cost_delay的值。默认值为20毫秒。
lautovacuum_vacuum_cost_limit:
此值是autovacuum process的评估阈值。默认值为-1,这意味着使用“vacuum_cost_limit”值。如果在执行自动清理进程期间评估的成本超过了autovacuum_vacuum_cost_limit,autovacuum process将处于休眠状态
Stat Collector
Stat collector是PostgreSQL数据库的统计信息收集器。它收集数据库操作期间的统计信息,如表的添加、删除或更新的数量、数据块的数量、索引的变化等。收集统计信息主要是为了让查询优化器做出正确的判断,选择最佳的执行计划。postgresql.conf文件中与Stat collector相关的参数如下
#------------------------------------------------------------------------------
# STATISTICS
#------------------------------------------------------------------------------
# - Query and Index Statistics Collector -
#track_activities = on
#track_counts = on
#track_io_timing = off
#track_functions = none # none, pl, all
#track_activity_query_size = 1024 # (change requires restart)
#stats_temp_directory = 'pg_stat_tmp'#------------------------------------------------------------------------------
# STATISTICS
#------------------------------------------------------------------------------
# - Query and Index Statistics Collector -
#track_activities = on
#track_counts = on
#track_io_timing = off
#track_functions = none # none, pl, all
#track_activity_query_size = 1024 # (change requires restart)
#stats_temp_directory = 'pg_stat_tmp'ltrack_activities:
指示是否为会话中当前执行的命令启用统计信息收集功能。此参数仅对超级用户和会话所有者可见。默认值是on。
ltrack_counts:
指示是否为数据库活动启用统计信息收集功能。由于在AutoVacuum自动清理进程中选择了要清理的数据库,需要数据库统计信息,因此该参数的默认值为on。
ltrack_io_timing:
对调用数据块I/O进行计时,默认为off,因为设置为on状态将反复调用数据库时间,这会增加数据库的大量开销。只有超级用户可以设置
ltrack_functions:
指示是否启用函数调用数量和耗时统计。
ltrack_activity_query_size:
设置用于跟踪每个活动会话的当前执行命令的字节数。默认值是1024,只能在数据库启动后设置。
lstats_temp_directory:
统计信息的临时存储路径。路径可以是相对路径,也可以是绝对路径。默认参数是pg_stat_tmp。此参数只能在postgresql.conf文件或服务器命令行中修改
Checkpointer 进程
检查点是由系统设置的事务点序列。设置检查点可以确保检查点之前的WAL日志信息被刷新到磁盘。在发生崩溃时,崩溃恢复过程将查看最新的检查点记录,以确定日志中应该从何处开始REDO操作(称为重做记录)。postgresql.conf文件中的相关参数为:
# - Checkpoints -
#checkpoint_timeout = 5min # range 30s-1d
max_wal_size = 1GB
min_wal_size = 80MB#checkpoint_completion_target = 0.5
# checkpoint target duration, 0.0 - 1.0
#checkpoint_flush_after = 256kB # measured in pages, 0 disables
#checkpoint_warning = 30s # 0 disables# - Checkpoints -
#checkpoint_timeout = 5min # range 30s-1d
max_wal_size = 1GB
min_wal_size = 80MB#checkpoint_completion_target = 0.5
# checkpoint target duration, 0.0 - 1.0
#checkpoint_flush_after = 256kB # measured in pages, 0 disables
#checkpoint_warning = 30s # 0 disableslcheckpoint_timeout:
此参数配置检查点的执行周期。默认值是5分钟。这意味着每隔5分钟就会出现一个检查点,或者在即将超过max_wal_size时。默认是1 GB。
lmax_wal_size:
此参数设置检查点发生前的WAL的最大值。
lmin_wal_size:
此参数设置了需要回收的以备将来使用的WAL文件总大小的最小值
lcheckpoint_completion_target:
为了避免大量的页面写入对I/O造成冲击,在检查点期间写入脏缓冲区的过程会分散一段时间。该周期由checkpoint_completion_target控制,它是检查点间隔的一部分。
lcheckpoint_flush_after:
当检查点发生时,检查点写入的页面大小超过本参数值时,将刷新到磁盘。否则,这些页面可能会保存在操作系统的页面缓存中。默认值为256kB。
lcheckpoint_warning:
检查点的操作是非常昂贵的。该参数在检查点之间配置一个阈值,如果由于填充WAL segment files而导致的检查点发生间隔小于本参数值,系统将在服务器日志中输出一个警告,建议用户增加max_wal_size
共享内存和本地内存
当PostgreSQL服务器启动时,将分配一个共享内存作为数据块的缓冲区,以提高读取和写入能力。共享内存中也存在WAL log buffer和CLOG buffer。一些全局信息,如进程信息、锁信息、全局统计信息等都存储在共享内存中。
除了共享内存,后台服务还将分配一些本地内存来临时存储不需要全局存储的数据。这些内存缓冲区主要包括以下类别:
lTemporary buffer:用于访问临时表的本地缓冲区
lwork_mem:在使用临时磁盘文件之前,内存排序操作和哈希表使用的内存缓冲。
lmaintenance_work_mem:维护操作中使用的内存缓冲区(例如,acuum, create index, alter table add foreign key等)
2.2 内存结构
共享内存一般指的是内存中专门为数据库缓存和事务日志缓存分配的区域,而最重要的组件就是共享缓存和WAL缓存。
共享缓存的主要目的是减少磁盘的IO,比如一些经常访问的数据块尽可能长的时间保存在共享缓存中,除此之外还有一些诸如进程、锁、统计信息也是在缓存中。
WAL缓存区是一块临时存储数据变更的临时区域,存储在该缓存区的内容会被周期性写入到WAL文件中,该区域对于数据库的备份和恢复都是非常重要的

2.3 数据库结构
结构是逻辑结构,不讨论物理结构。以下是一些理解数据库结构非常重要的内容。
关于数据库:
- PostgreSQL是由多个数据库组成的,也可以称为数据库群。
- 当执行了init(),系统会默认创建3个库:template0,template1,postgres。
- template0和template1是为用户数据库创建的模板库,初始化后,这两个库是一模一样的。
- template1可以被定制修改,用户创建新的数据库都是克隆该数据库的。
关于表空间:
- 在初始化后,默认创建了两个表空间pg_default和pg_global。
- 如果在创建表时候没有指定表空间,则默认是pg_default。
- 数据库群中表的管理默认都是在pg_global中。
- pg_default表空间的物理位置在$PGDATA\base。
- pg_global表空间的物理位置在$PGDATA\global。
关于表:
- 每张表包含三个文件。
- 一个文件用于存储数据,文件名是表的OID。
- 一个文件用于管理表的空余空间,文件名是OID_fsm。
- 一个文件用于管理表块的可见性,文件名是OID_vm。
- 索引没有_vm文件
二、POSTGRESQL逻辑结构和物理结构
2.1逻辑结构
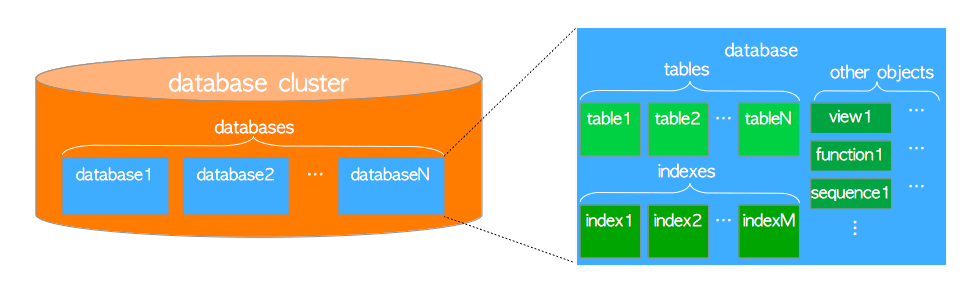
PostgreSQL中的术语不是,他是在单个主机上运行并管理单个数据库的集群。例如图一数据库集群包含了Database 1,Database 2等数据库。而一个数据库是由多个对象构成的。而这些对象包含了表、索引、视图、存储过程、函数、序列等。在PostgreSQL当中,数据库本身也是对象。并且在逻辑上彼此分离。所有其他数据库对象(表、索引)都属于他们各自的数据库
PostgreSQL当中,所有的数据库对象都由相应的对象标识符(OID)进行内部管理。这些标识符是无符号的4字节的整数。数据库对象与相应的OID之间的关系存储在适当的系统目录中。具体取决于对象的类型。例如数据库和表的OID分别存储在PG_DATABASE和PG_CLASS中,我们可以通过下列查询查OID
postgres@han_db=>select datname,oid from pg_database where datname='han_db';
datname | oid
---------+-------
han_db | 16384
(1 row)
-- table
postgres@han_db=>select relname,oid from pg_class where relname='t1';
relname | oid
---------+-------
t1 | 17719
(1 row)postgres@han_db=>select datname,oid from pg_database where datname='han_db';
datname | oid
---------+-------
han_db | 16384
(1 row)
-- table
postgres@han_db=>select relname,oid from pg_class where relname='t1';
relname | oid
---------+-------
t1 | 17719
(1 row)2.2物理结构
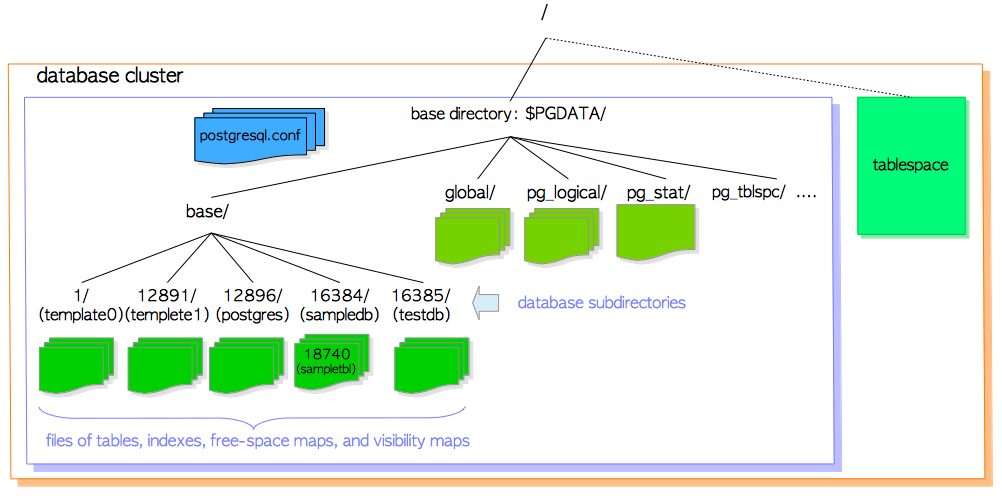
一个数据库集群基本上可以看作是一个基础的目录,它包含了一些子目录和文件。如果执行inittab执行程序初始化,则将在指定目录下创建基本目录,基本目录通常被设置成环境变量PGDATA。
如图所示,数据库集群的基础目录是$PGDATA。而数据库存放在$PGDATA下的Base目录下。这里有好几个数字开头的目录,对应刚刚我们通过查 pg_database找出的oid编号。例如oid为16385的代表着testdb数据库,而该目录下进一步存放了表和索引、free-space maps和visibility maps(我们可以通过pg_class下的oid编号查到对应的表)。另外还有一些程序的文件目录存放在$PGDATA下面。Postgre也支持表空间,Postgre表空间是一个包含基本目录之外的数据的目录