 SRE文档
SRE文档1.集群规划
| 名称 | IP | 端口 | 用途 | RabbitMQ 节点名称 |
|---|---|---|---|---|
| 节点一 | 192.168.1.109 | 15672 | 磁盘节点 | rabbit@rabbitmq1 |
| 节点二 | 192.168.1.201 | 15672 | 内存节点 | rabbit@rabbitmq2 |
| 节点三 | 192.168.1.200 | 15672 | 内存节点 | rabbit@rabbitmq3 |
集群中,每一个RabbitMQ实例都是一个节点,而节点分为磁盘节点和内存节点
- 内存节点:将Rabbit中的元数据(Queue, Exchange, binding, vhost等)存储在内存中,持久化的 Message 依旧保存在磁盘中,内存节点的性能只能体现在资源管理上,消息的发送和接收和磁盘节点没有区别
- 磁盘节点:元数据存储在磁盘中,一个Rabbit集群要求至少有一个磁盘节点,因为内存节点中不存储元数据,所以每次内存节点启动,都会从其他节点中同步元数据
另外如果唯一磁盘的磁盘节点崩溃了,不能进行如下操作:
- 不能创建队列
- 不能创建交换器
- 不能创建绑定
- 不能添加用户
- 不能更改权限
- 不能添加和删除集群几点
RabbitMQ集群的几种类型
- 单一模式:仅有一个rabbit实例
- 普通模式:默认集群模式,每个节点各自维护自己的数据,两个节点仅存有相同的元数据。例如RabbitA 和 RabbitB,A中存在 QueueA,消费者可以从RabbitB实例中,读取QueueA的消息,这时RabbitB会从A中读取消息,返回给消费者。但是如果RabbitA 宕机,这时就无法获取QueueA的数据了
- 镜像模式:Rabbit 会将数据同步到其他节点中,这固然提高了可用性,但是随之而来的问题是,系统的性能会降低。节点之间消息的传递会占用带宽,而每个节点存储的数据量会变大
1.0Rabbit主要的端口说明:
| 端口 | 说明 |
|---|---|
| 4369 | erlang发现口 |
| 5672 | client端通信口 |
| 15672 | 管理界面ui端口 |
| 25672 | server间内部通信口 |
注意,在生产环境搭建 RabbitMQ 集群时,所有集群节点要求都可以连接上互联网,另外 RabbitMQ 集群节点建议都在同一网段里,如果是跨广域网(外网),效果会变差
1.1配置路径
| 位置 | 说明 |
|---|---|
| /usr/local/rabbitmq | 安装目录 |
| /usr/local/rabbitmq/var/log/rabbitmq | 日志目录 |
| /usr/local/rabbitmq/var/lib/rabbitmq/mnesia | 数据目录 |
| /usr/local/rabbitmq/etc/rabbitmq/rabbitmq.config | 配置文件 |
| /usr/local/rabbitmq/etc/rabbitmq/rabbitmq-env.conf | 环境变量配置文件 |
| /etc/init.d/rabbitmq-cluster-15672 | 服务自启动脚本 |
1.2系统初始化
临时更改最大打开文件描述符数
# 查看限制
# ulimit -n
# 临时更改限制(系统重启失效)
# ulimit -n 1048576# 查看限制
# ulimit -n
# 临时更改限制(系统重启失效)
# ulimit -n 1048576永久更改最大打开文件描述符数
# 第一步
# vim /etc/security/limits.conf
* soft nofile 1048576
* hard nofile 1048576 #星号表示对所有用户生效
# 第二步
# vim /etc/sysctl.conf
fs.file-max = 1048576 #可执行"sysctl -p"使fs.file-max生效
# 第三步
# vim /etc/pam.d/login
session required pam_limits.so #查看配置文件有没有这行,没有就加上
# 第四步
# reboot #重启系统
# 第五步(查看是否生效)
# ulimit -n
# sysctl fs.file-max
# cat /proc/PID/limits #PID是应用的进程ID,在输出结果中查看"Max open files"的显示值# 第一步
# vim /etc/security/limits.conf
* soft nofile 1048576
* hard nofile 1048576 #星号表示对所有用户生效
# 第二步
# vim /etc/sysctl.conf
fs.file-max = 1048576 #可执行"sysctl -p"使fs.file-max生效
# 第三步
# vim /etc/pam.d/login
session required pam_limits.so #查看配置文件有没有这行,没有就加上
# 第四步
# reboot #重启系统
# 第五步(查看是否生效)
# ulimit -n
# sysctl fs.file-max
# cat /proc/PID/limits #PID是应用的进程ID,在输出结果中查看"Max open files"的显示值1.3创建用户和用户组
# 创建rabbitmq用户组
# groupadd rabbitmq
# 创建rabbitmq用户(不允许远程登录)
# useradd -g rabbitmq rabbitmq -s /bin/false# 创建rabbitmq用户组
# groupadd rabbitmq
# 创建rabbitmq用户(不允许远程登录)
# useradd -g rabbitmq rabbitmq -s /bin/false1.4集群同步那些东西
RabbitMQ集群会始终同步四种类型的内部元数据:
- 队列元数据:队列名称和它的属性
- 交换器元数据:交换器名称、类型和属性
- 绑定元数据:一张简单的表格展示了如何将消息路由到队列
- vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性
2.RabbitMQ 集群安装
资源下载
Erlang 下载1:http://packages.erlang-solutions.com/erlang/rpm/centos/7/x86_64/
Erlang 下载2(GitHub):https://github.com/rabbitmq/erlang-rpm/releases/tag/v23.2.5
RabbitMQ 下载:https://github.com/rabbitmq/rabbitmq-server/releases/tag/v3.9.7
2.1Erlang 安装
在每个集群节点上分别编译安装 Erlang,这里使用的版本是 23.2,其他版本的 Erlang 可以从 Erlang 官网 下载
# 安装依赖
# yum install -y make autoconf gcc gcc-c++ glibc-devel kernel-devel m4 ncurses-devel openssl-devel unixODBC unixODBC-devel libtool libtool-ltdl-devel unzip
# 创建安装目录
# mkdir -p /usr/local/erlang-23.2
# 下载
# wget https://erlang.org/download/otp_src_23.2.tar.gz
# 解压
# tar -xvf otp_src_23.2.tar.gz
# 进入解压目录
# cd otp_src_23.2
# 配置
# ./otp_build autoconf
# ./configure --prefix=/usr/local/erlang-23.2 --without-javac --enable-smp-support \
--enable-threads \
--enable-sctp \
--enable-kernel-poll \
--enable-hipe \
--with-ssl
--prefix 指定安装目录
--enable-smp-support启用对称多处理支持
--enable-threads启用异步线程支持
--enable-sctp启用流控制协议支持(Stream Control Transmission Protocol,流控制传输协议)
--enable-kernel-poll启用Linux内核poll
--enable-hipe启用高性能Erlang
--with-ssl使用SSL包
# 编译安装
# make && make install
# 创建软链接
# ln -sf /usr/local/erlang-23.2/bin/erl /usr/bin/erl
# 配置环境变量
# vim /etc/profile
export ERLANG_HOME=/usr/local/erlang-23.2
export PATH=$PATH:$ERLANG_HOME/bin
# 使环境变量生效
# source /etc/profile# 安装依赖
# yum install -y make autoconf gcc gcc-c++ glibc-devel kernel-devel m4 ncurses-devel openssl-devel unixODBC unixODBC-devel libtool libtool-ltdl-devel unzip
# 创建安装目录
# mkdir -p /usr/local/erlang-23.2
# 下载
# wget https://erlang.org/download/otp_src_23.2.tar.gz
# 解压
# tar -xvf otp_src_23.2.tar.gz
# 进入解压目录
# cd otp_src_23.2
# 配置
# ./otp_build autoconf
# ./configure --prefix=/usr/local/erlang-23.2 --without-javac --enable-smp-support \
--enable-threads \
--enable-sctp \
--enable-kernel-poll \
--enable-hipe \
--with-ssl
--prefix 指定安装目录
--enable-smp-support启用对称多处理支持
--enable-threads启用异步线程支持
--enable-sctp启用流控制协议支持(Stream Control Transmission Protocol,流控制传输协议)
--enable-kernel-poll启用Linux内核poll
--enable-hipe启用高性能Erlang
--with-ssl使用SSL包
# 编译安装
# make && make install
# 创建软链接
# ln -sf /usr/local/erlang-23.2/bin/erl /usr/bin/erl
# 配置环境变量
# vim /etc/profile
export ERLANG_HOME=/usr/local/erlang-23.2
export PATH=$PATH:$ERLANG_HOME/bin
# 使环境变量生效
# source /etc/profile3.RabbitMQ 安装
在==每个集群节点上==分别使用二进制包的方式安装 RabbitMQ,使用的版本是 3.8.6,其他版本的 RabbitMQ 可以从 RabbitMQ Github 下载
# 安装依赖
# yum install -y xmlto python-simplejson
# 下载
# wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.6/rabbitmq-server-generic-unix-3.8.6.tar.xz
# 解压
# xz -d rabbitmq-server-generic-unix-3.8.6.tar.xz
# tar -xvf rabbitmq-server-generic-unix-3.8.6.tar
# 拷贝安装文件
# cp -r rabbitmq_server-3.8.6 /usr/local/rabbitmq
# 文件授权
# chown -R rabbitmq:rabbitmq /usr/local/rabbitmq# 安装依赖
# yum install -y xmlto python-simplejson
# 下载
# wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.6/rabbitmq-server-generic-unix-3.8.6.tar.xz
# 解压
# xz -d rabbitmq-server-generic-unix-3.8.6.tar.xz
# tar -xvf rabbitmq-server-generic-unix-3.8.6.tar
# 拷贝安装文件
# cp -r rabbitmq_server-3.8.6 /usr/local/rabbitmq
# 文件授权
# chown -R rabbitmq:rabbitmq /usr/local/rabbitmq4.RabbitMQ 配置
在每个集群节点上分别配置 RabbitMQ,包括创建默认的日志目录与数据目录、启用 Web 控制台管理插件
# 创建默认的日志目录与数据目录
# mkdir -p /usr/local/rabbitmq/var/log/rabbitmq
# mkdir -p /usr/local/rabbitmq/var/lib/rabbitmq/mnesia
# 创建默认的配置文件
# touch /usr/local/rabbitmq/etc/rabbitmq/rabbitmq.config
# echo "[]." > /usr/local/rabbitmq/etc/rabbitmq/rabbitmq.config
# 创建默认的环境变量文件
# touch /usr/local/rabbitmq/etc/rabbitmq/rabbitmq-env.conf
# echo "CONF_ENV_FILE=/usr/local/rabbitmq/etc/rabbitmq/rabbitmq-env.conf" >> /usr/local/rabbitmq/sbin/rabbitmq-defaults
# 启用Web控制台管理插件
# cd /usr/local/rabbitmq/sbin
# ./rabbitmq-plugins enable rabbitmq_management
# 查看所有插件的安装信息
# ./rabbitmq-plugins list
# 文件授权
# chown -R rabbitmq:rabbitmq /usr/local/rabbitmq# 创建默认的日志目录与数据目录
# mkdir -p /usr/local/rabbitmq/var/log/rabbitmq
# mkdir -p /usr/local/rabbitmq/var/lib/rabbitmq/mnesia
# 创建默认的配置文件
# touch /usr/local/rabbitmq/etc/rabbitmq/rabbitmq.config
# echo "[]." > /usr/local/rabbitmq/etc/rabbitmq/rabbitmq.config
# 创建默认的环境变量文件
# touch /usr/local/rabbitmq/etc/rabbitmq/rabbitmq-env.conf
# echo "CONF_ENV_FILE=/usr/local/rabbitmq/etc/rabbitmq/rabbitmq-env.conf" >> /usr/local/rabbitmq/sbin/rabbitmq-defaults
# 启用Web控制台管理插件
# cd /usr/local/rabbitmq/sbin
# ./rabbitmq-plugins enable rabbitmq_management
# 查看所有插件的安装信息
# ./rabbitmq-plugins list
# 文件授权
# chown -R rabbitmq:rabbitmq /usr/local/rabbitmq在每个集群节点上分别配置 RabbitMQ,包括创建虚拟主机、超级管理员用户、设置角色权限。由于出于系统安全考虑,RabbitMQ 默认限制了 guest 用户只能通过 localhost 登录使用,因此需要手动创建管理员帐号,并更改 guest 用户默认的密码
# 进入安装目录
# cd /usr/local/rabbitmq/sbin
# 前台启动RabbitMQ服务(默认会打印出日志文件和配置文件的路径)
# ./rabbitmq-server
# 或者后台启动RabbitMQ服务
# ./rabbitmq-server -detached
# 创建虚拟主机(相当于MySQL的数据库概念)
# ./rabbitmqctl add_vhost /
# 更改guest用户默认的密码
# ./rabbitmqctl change_password guest yourPassword
# 创建超级管理员用户
# ./rabbitmqctl add_user admin yourPassword
# 赋予administrator角色给超级管理员用户
# ./rabbitmqctl set_user_tags admin administrator
# 赋予超级管理员用户权限
# ./rabbitmqctl set_permissions -p / admin '.*' '.*' '.*'
# 彻底关闭后台启动的RabbitMQ服务
# ./rabbitmqctl stop# 进入安装目录
# cd /usr/local/rabbitmq/sbin
# 前台启动RabbitMQ服务(默认会打印出日志文件和配置文件的路径)
# ./rabbitmq-server
# 或者后台启动RabbitMQ服务
# ./rabbitmq-server -detached
# 创建虚拟主机(相当于MySQL的数据库概念)
# ./rabbitmqctl add_vhost /
# 更改guest用户默认的密码
# ./rabbitmqctl change_password guest yourPassword
# 创建超级管理员用户
# ./rabbitmqctl add_user admin yourPassword
# 赋予administrator角色给超级管理员用户
# ./rabbitmqctl set_user_tags admin administrator
# 赋予超级管理员用户权限
# ./rabbitmqctl set_permissions -p / admin '.*' '.*' '.*'
# 彻底关闭后台启动的RabbitMQ服务
# ./rabbitmqctl stop配置systemd
# 创建服务自启动脚本
# touch /etc/init.d/rabbitmq-cluster-15672
# 更改服务自启动脚本,写入后面给出的脚本内容
# vim /etc/init.d/rabbitmq-cluster-15672
# 服务自启动脚本授权
# chmod u+x /etc/init.d/rabbitmq-cluster-15672
# 开机自启动
# chkconfig rabbitmq-cluster-15672 on
# 查看开机自启动列表
# chkconfig --list
# 关闭开机自启动
# chkconfig rabbitmq-cluster-15672 off# 创建服务自启动脚本
# touch /etc/init.d/rabbitmq-cluster-15672
# 更改服务自启动脚本,写入后面给出的脚本内容
# vim /etc/init.d/rabbitmq-cluster-15672
# 服务自启动脚本授权
# chmod u+x /etc/init.d/rabbitmq-cluster-15672
# 开机自启动
# chkconfig rabbitmq-cluster-15672 on
# 查看开机自启动列表
# chkconfig --list
# 关闭开机自启动
# chkconfig rabbitmq-cluster-15672 off# 关闭服务
# systemctl stop rabbitmq-cluster-15672
# 启动服务
# systemctl start rabbitmq-cluster-15672
# 查看服务状态
# systemctl status rabbitmq-cluster-15672
# 重启服务
# systemctl restart rabbitmq-cluster-15672# 关闭服务
# systemctl stop rabbitmq-cluster-15672
# 启动服务
# systemctl start rabbitmq-cluster-15672
# 查看服务状态
# systemctl status rabbitmq-cluster-15672
# 重启服务
# systemctl restart rabbitmq-cluster-15672配置防火墙
firewall-cmd --permanent --add-port={4369/tcp,25672/tcp}
firewall-cmd --reload
firewall-cmd --add-port=4369/tcp --permanent
firewall-cmd --add-port=25672/tcp --permanent
firewall-cmd --add-port=5671-5672/tcp --permanent
firewall-cmd --add-port=15672/tcp --permanent
firewall-cmd --add-port=61613-61614/tcp --permanent
firewall-cmd --add-port=1883/tcp --permanent
firewall-cmd --add-port=8883/tcp --permanent
firewall-cmd --reload # 重载配置firewall-cmd --permanent --add-port={4369/tcp,25672/tcp}
firewall-cmd --reload
firewall-cmd --add-port=4369/tcp --permanent
firewall-cmd --add-port=25672/tcp --permanent
firewall-cmd --add-port=5671-5672/tcp --permanent
firewall-cmd --add-port=15672/tcp --permanent
firewall-cmd --add-port=61613-61614/tcp --permanent
firewall-cmd --add-port=1883/tcp --permanent
firewall-cmd --add-port=8883/tcp --permanent
firewall-cmd --reload # 重载配置5.RabbitMQ 普通集群搭建
5.1添加节点主机名
在每个集群节点上分别编辑 /etc/hosts 配置文件,指定各个节点的主机名
# vim /etc/hosts
192.168.1.109 rabbitmq1
192.168.1.201 rabbitmq2
192.168.1.200 rabbitmq3
#或者
sed -i '$a\192.168.1.109 rabbitmq1' /etc/hosts# vim /etc/hosts
192.168.1.109 rabbitmq1
192.168.1.201 rabbitmq2
192.168.1.200 rabbitmq3
#或者
sed -i '$a\192.168.1.109 rabbitmq1' /etc/hosts5.2配置节点名称
RabbitMQ 节点由节点名称(RABBITMQ_NODENAME)标识,节点名称由两部分组成,前缀(默认是 rabbit)和主机名,例如:rabbit@rabbit1 是一个包含前缀 rabbit 和主机名 rabbit1 的节点名称。
可以在同一台主机上运行多个 RabbitMQ 节点,但集群中每个节点必须有一个唯一的 RABBITMQ_NODENAME。若在同一台主机上运行多个节点(开发和 QA 环境中通常是这种情况),每个节点还必须使用不同的前缀,例如:rabbit1@hostname1 和 rabbit2@hostname2。
在集群中,节点使用节点名称标识和联系彼此,这意味着必须解析每个节点名的主机名部分。当节点启动时,它会检查是否已为其分配了节点名,这是通过配置文件 rabbitmq-env.conf 里的 RABBITMQ_NODENAME 环境变量指定,如果环境变量没有配置,则节点将解析其主机名并在其前面添加 rabbit 来计算其节点名
在每个集群节点上分别配置节点名称,只需将下面 rabbit@xxx 中的 xxx 替换为该节点的主机名即可,例如节点一的节点名称为: rabbit@rabbitmq1
# 配置节点名称
# echo "NODENAME=rabbit@xxx" >> /usr/local/rabbitmq/etc/rabbitmq/rabbitmq-env.conf# 配置节点名称
# echo "NODENAME=rabbit@xxx" >> /usr/local/rabbitmq/etc/rabbitmq/rabbitmq-env.conf如果两个节点都是 rabbit@localhost,这是无法建立集群
5.3拷贝 Erlang Cookie
RabbitMQ 的集群是依附于 Erlang 的集群来工作的,所以必须先构建起 Erlang 的集群。Erlang 的集群中各节点是经由过程一个 cookie 来实现的,当使用解压缩的方式来安装 RabbitMQ 时,那么这个 cookie 存放在 ${home}/.erlang.cookie 中,文件是 400 的权限。必须保证集群各节点的 cookie 一致,不然节点之间就无法通信
注意事项
cookie 在所有节点上必须完全一样,同步时一定要注意。 erlang 是通过主机名来连接服务,必须保证各个主机名之间可以 ping 通。可以通过编辑 / etc/hosts 来手工添加主机名和 IP 对应关系。如果主机名 ping 不通,rabbitmq 服务启动会失败
# 拷贝节点一的Cookie到其他节点
# scp /root/.erlang.cookie root@rabbitmq2:/root/
# scp /root/.erlang.cookie root@rabbitmq3:/root/# 拷贝节点一的Cookie到其他节点
# scp /root/.erlang.cookie root@rabbitmq2:/root/
# scp /root/.erlang.cookie root@rabbitmq3:/root/5.4构建集群节点
在每个集群节点上分别启动 RabbitMQ 的服务,这里默认使用的用户为 root。当使用解压缩的方式来安装 RabbitMQ 时,cookie 是存放在 ${home}/.erlang.cookie,因此这里必须注意各个节点的 RabbitMQ 是使用哪个用户启动,否则后续很可能由于各节点的 .erlang.cookie 不一致而导致节点无法加入集群
# 进入安装目录
# cd /usr/local/rabbitmq/sbin
# 后台启动RabbitMQ服务
# ./rabbitmq-server -detached# 进入安装目录
# cd /usr/local/rabbitmq/sbin
# 后台启动RabbitMQ服务
# ./rabbitmq-server -detached在节点二执行以下操作,将节点二(rabbit@rabbitmq2)加入到 RabbitMQ 集群
# 进入节点二的安装目录
# cd /usr/local/rabbitmq/sbin
# 停止节点二的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq2 stop_app
# 将节点二加入到集群中,"--ram" 表示节点二为内存节点,#默认磁盘节点类型disc
# ./rabbitmqctl -n rabbit@rabbitmq2 join_cluster rabbit@rabbitmq1 --ram
# 启动节点二的RabbitMQ服务
# ./rabbitmqctl -n rabbit@rabbitmq2 start_app# 进入节点二的安装目录
# cd /usr/local/rabbitmq/sbin
# 停止节点二的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq2 stop_app
# 将节点二加入到集群中,"--ram" 表示节点二为内存节点,#默认磁盘节点类型disc
# ./rabbitmqctl -n rabbit@rabbitmq2 join_cluster rabbit@rabbitmq1 --ram
# 启动节点二的RabbitMQ服务
# ./rabbitmqctl -n rabbit@rabbitmq2 start_app在节点三执行以下操作,将节点三(rabbit@rabbitmq3)加入到 RabbitMQ 集群
# 进入节点三的安装目录
# cd /usr/local/rabbitmq/sbin
# 清空节点状态
rabbitmqctl reset
# 停止节点三的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq3 stop_app
# 将节点三加入到集群中,"--ram" 表示节点三为内存节点
# ./rabbitmqctl -n rabbit@rabbitmq3 join_cluster rabbit@rabbitmq1 --ram
# 启动节点三的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq3 start_app# 进入节点三的安装目录
# cd /usr/local/rabbitmq/sbin
# 清空节点状态
rabbitmqctl reset
# 停止节点三的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq3 stop_app
# 将节点三加入到集群中,"--ram" 表示节点三为内存节点
# ./rabbitmqctl -n rabbit@rabbitmq3 join_cluster rabbit@rabbitmq1 --ram
# 启动节点三的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq3 start_app在任意节点上查看集群的状态
# 进入安装目录
# cd /usr/local/rabbitmq/sbin
# 查看集群状态
# ./rabbitmqctl cluster_status# 进入安装目录
# cd /usr/local/rabbitmq/sbin
# 查看集群状态
# ./rabbitmqctl cluster_status
- 搭建集群时,停止 RabbitMQ 服务必须使用
stop_app命令,而不是stop命令,否则无法将节点加入到集群中- 默认情况下,RabbitMQ 启动后是磁盘节点,在上面的
join_cluster命令下,rabbitmq2和rabbitmq3是内存节点,rabbitmq1是磁盘节点- 若要使
rabbitmq2和rabbitmq3都成为磁盘节点,去掉--ram参数即可,或者使用--disc参数替代- 如果想要更改节点类型,可以使用命令
rabbitmqctl change_cluster_node_type disc(ram),前提是必须停掉 RabbitMQ 服务
设置集群名字
rabbitmqctl set_cluster_name zz-rmqsrabbitmqctl set_cluster_name zz-rmqs5.5测试集群节点
若集群节点构建成功,通过浏览器访问任意节点的 Web 控制台,例如 http://192.168.1.109:15672,会看到如下的内容。最后可以在节点一创建队列 test,如果在节点二、节点三的 Web 控制台,也可以看到对应的 test 队列,则说明各集群节点的元数据(队列的结构)同步正常。至此,RabbitMQ 的普通集群搭建完成
6.RabbitMQ 镜像集群搭建
官方文档,https://www.rabbitmq.com/ha.html
上面已经完成 RabbitMQ 普通集群的搭建,但并不能保证队列的高可用性,尽管交换机、队列、绑定这些可以复制到集群里的任何一个节点,但是队列内容(消息)不会复制。虽然普通集群解决可以一项目组的节点压力,但队列节点(磁盘节点)宕机会直接导致其他节点的队列(内存节点)无法使用,只能等待队列节点(磁盘节点)重启,所以要想在队列节点(磁盘节点)宕机或故障也能正常应用,就要复制队列内容(消息)到集群里的每个节点,因此必须要创建镜像队列。镜像队列是基于普通的集群模式的,然后再添加一些策略,所以还是得先配置普通集群,然后才能设置镜像队列。设置镜像队列可以在 RabbitMQ 的 Web 控制台进行,也可以通过命令,这里介绍是其中的 Web 控制台设置方式
6.0镜像机制
镜像队列机制是基于Master-Slave主从模式的,镜像队列所有操作都是只能在Master节点进行操作,生产者发布消息到队列,分发消息给消费者,跟踪消费者的消费确认ACK,消费者不管连接的哪个节点最终都会转发到Master节点,然后将这些操作对应的消息由Master节点广播同步给其他节点
6.0创建策略
在节点一的 Web 控制台上创建策略:
- 点击
Admin菜单 –> 右侧的Policies选项
- 点击
- 2.按照图中的内容根据自己的需求填写
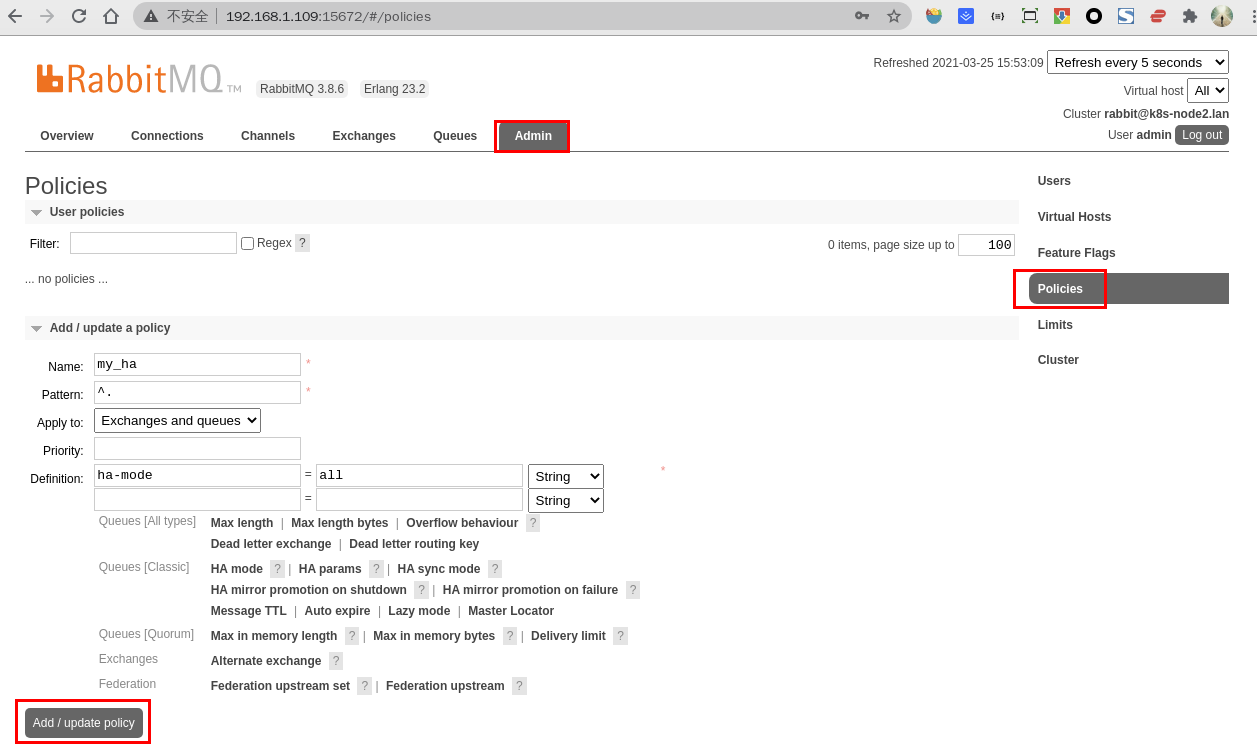
- Name:策略名称
- Pattern:匹配的规则,
^a表示匹配a开头的队列,如果是匹配所有的队列,那就是^.- Definition:使用
ha-mode模式中的all,也就是同步所有匹配的队列
- 命令行模式
任意rabbit节点输入命令,将所有队列,同步到所有节点中
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
^:为匹配符,只有一个^代表匹配所有,^zlh为匹配名称为zlh的exchanges或者queue
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
priority:可选参数,policy的优先级rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
^:为匹配符,只有一个^代表匹配所有,^zlh为匹配名称为zlh的exchanges或者queue
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
priority:可选参数,policy的优先级- 或者
rabbitmqctl set_policy fzb-ha "^" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'rabbitmqctl set_policy fzb-ha "^" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'- 目的
要设置Exchanges或者queue的数据需要复制
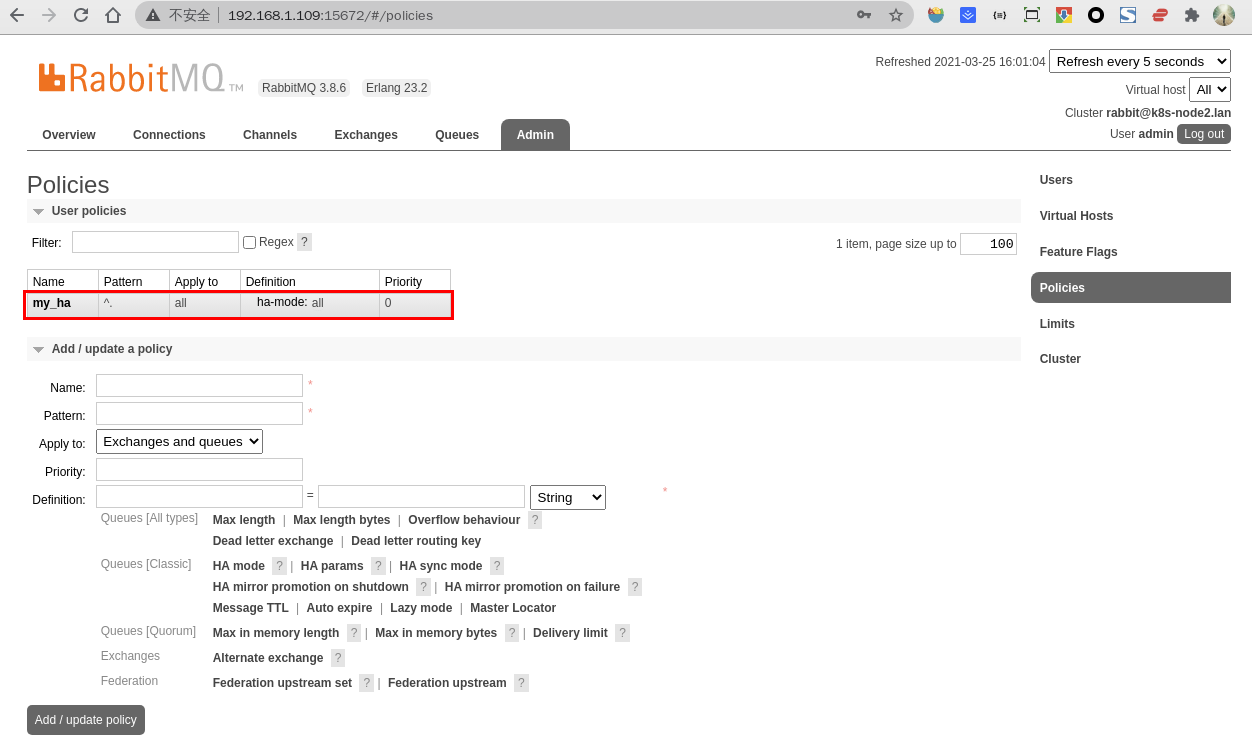
- 3.点击左侧最下边的
Add/update a policy按钮新增策略
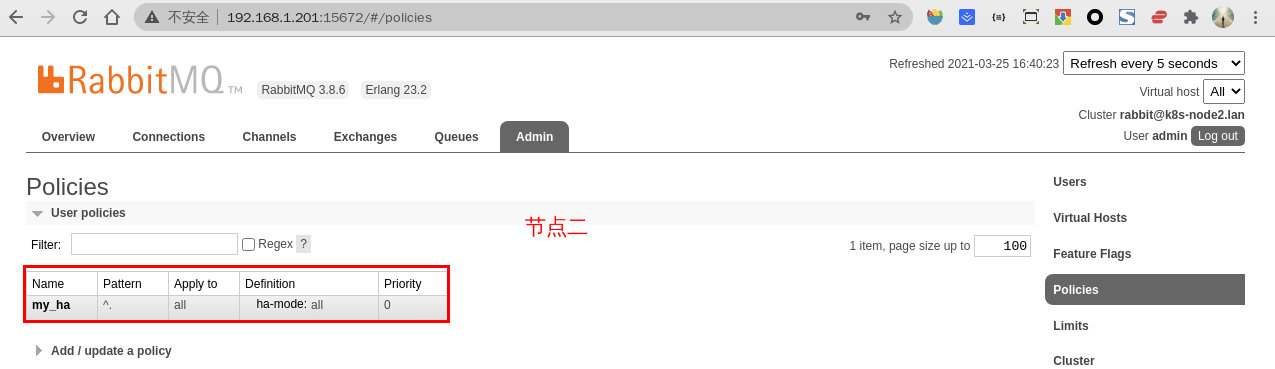
- 4.此时分别登录节点二、节点三的 Web 控制台,同样可以看到刚添加的这个策略
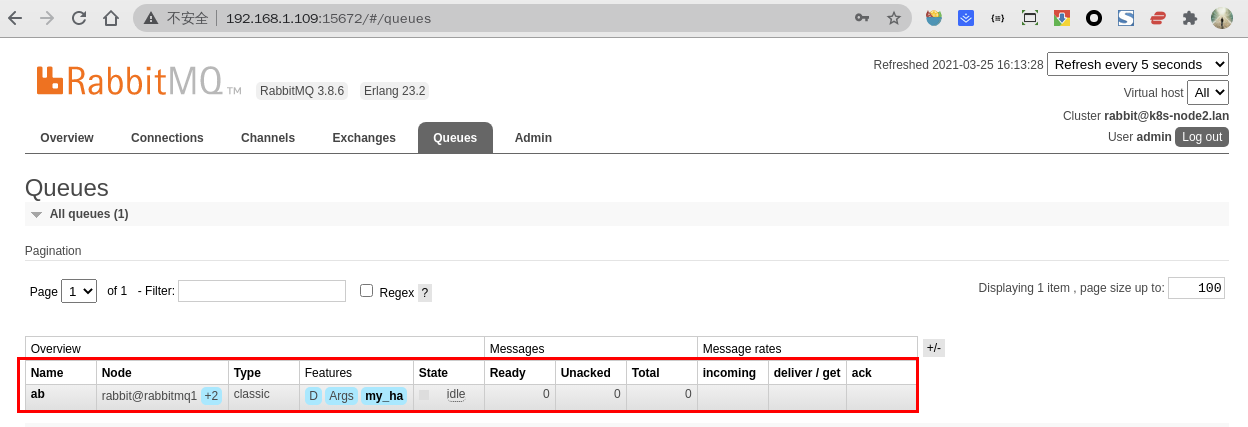
6.1创建队列
在节点一的 Web 控制台上创建队列:
- 点击
Queues菜单 - 输入
Name 和Arguments参数的值,别的参数默认即可
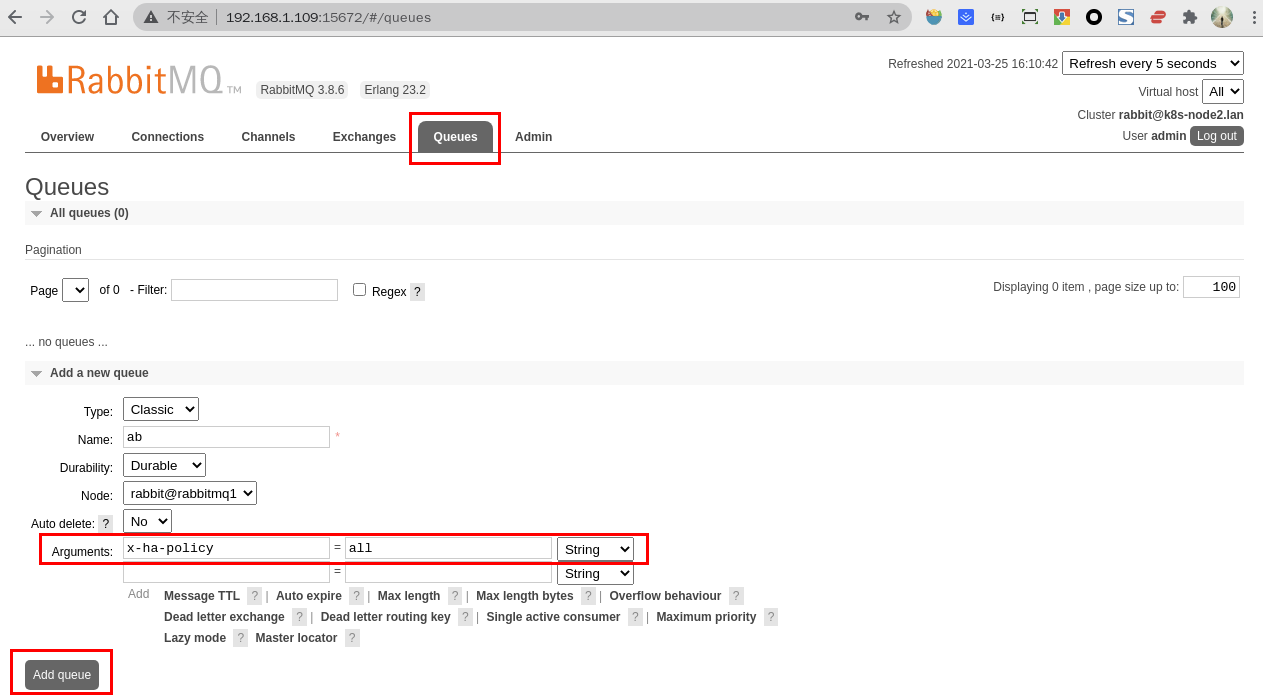
Name:队列名称 Durability:队列是否持久化 Node:消息队列的节点 Auto delete:是否自动删除 Arguments:使用的策略类型
- 点击左侧下边的
Add a new queue按钮新增队列,将鼠标指向+2可以显示出另外两台节点
6.2创建消息
- 点击
ab队列按钮,拖动滚动条 - 填写相关内容
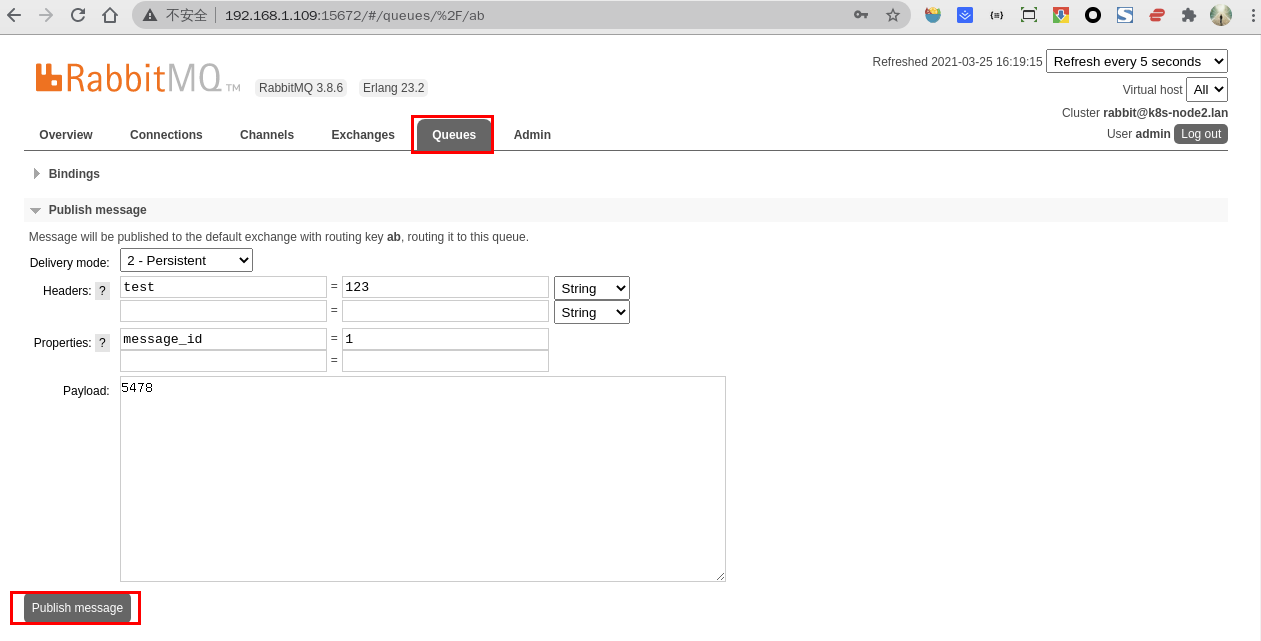
2-Persistent:表示持久化 Headers:随便填写即可 Properties:点击问号,选择一个消息 ID 号 Payload:消息内容
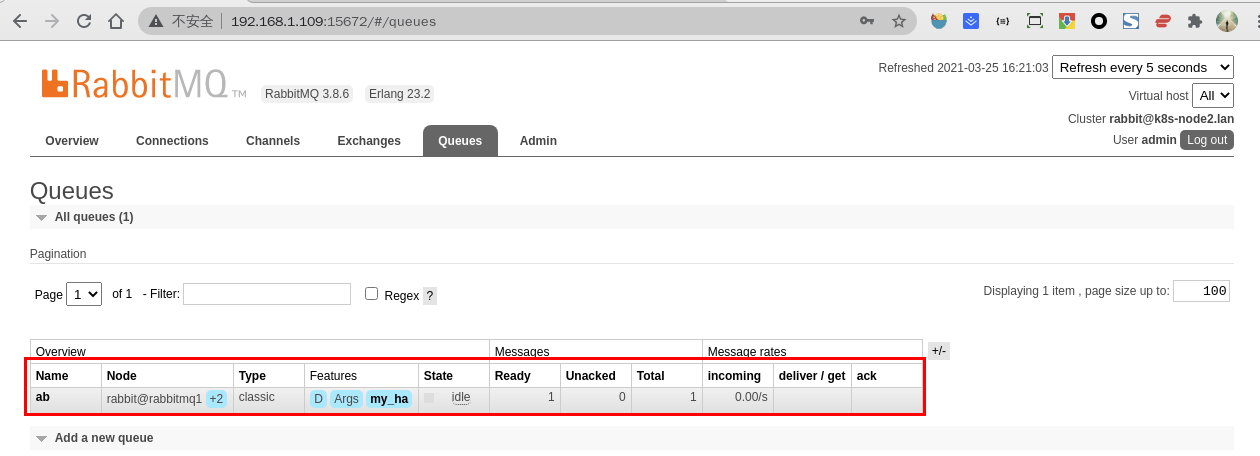
- 点击
Publish message按钮新增消息,可发现ab队列的Ready和Total中多了一条消息记录
验证高可用性
- 将节点一的 RabbitMQ 服务关闭,再通过节点一和节点二,查看消息记录是否还存在,结果可以看到在其他节点的消息记录是存在的
- 再将节点二的 RabbitMQ 服务关闭,通过节点三查看消息记录是否还存在,结果可以看到
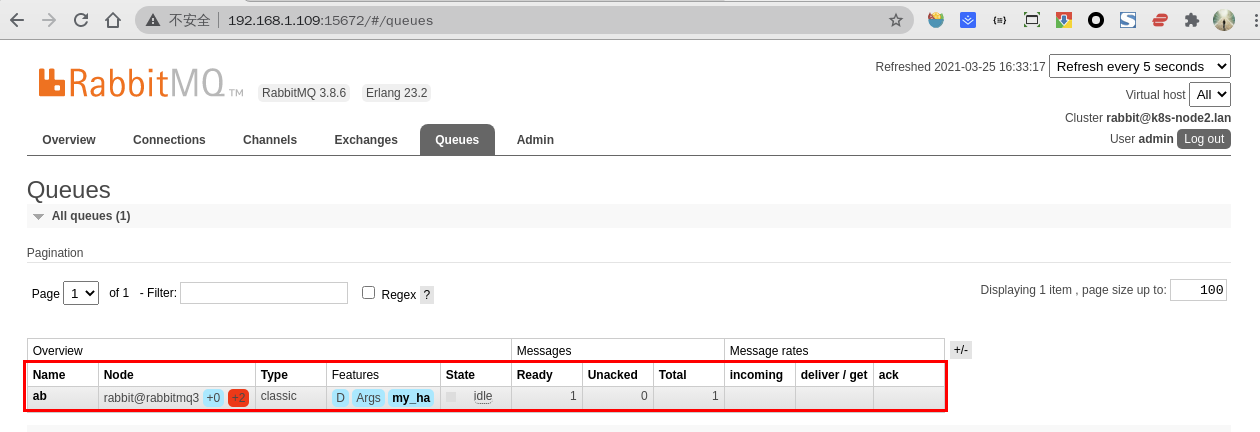
ab队列和消息记录还是存在的,只是变成了只有一个节点 - 将节点一和节点二的 RabbitMQ 服务重启,从中可以看到
ab队列后面+2变成了红色,鼠标指上去显示镜像无法同步
- 采取的解决办法是选择在节点二上执行同步命令
# 进入节点一的安装目录
# cd /usr/local/rabbitmq/sbin
# 同步特定的队列
# ./rabbitmqctl sync_queue ab# 进入节点一的安装目录
# cd /usr/local/rabbitmq/sbin
# 同步特定的队列
# ./rabbitmqctl sync_queue ab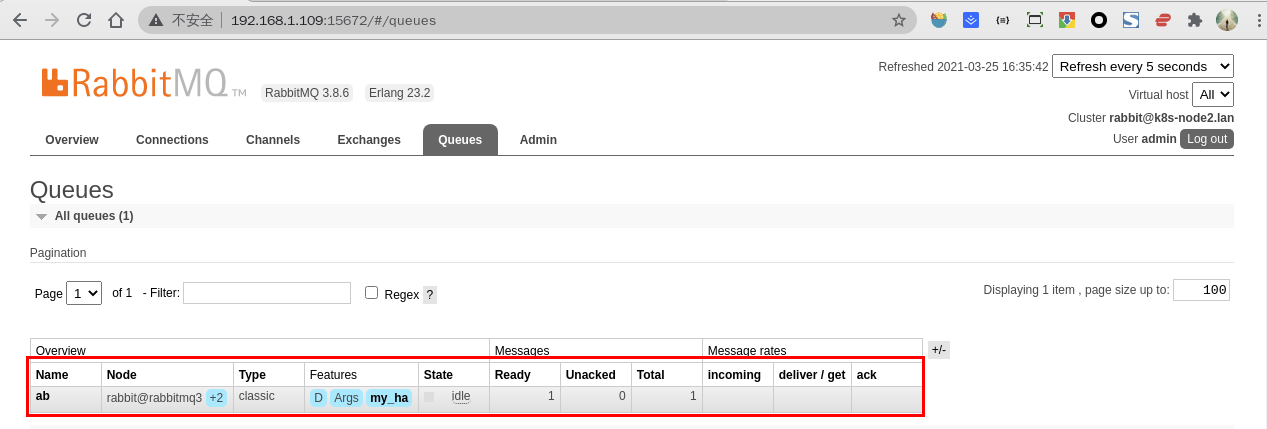
同步完成后,+2 标识又变成了蓝色,这样就测试了 RabbitMQ 集群的高可用性,说明镜像集群配置成功
7.集群开机自启动
7.1Supervior
严格来说 RabbitMQ 并不适用使用 Supervior 来管理服务,因为当手动 Kill 掉 RabbitMQ 的进程时,Supervior 无法正常重启 RabbitMQ 的进程,具体原因可以看这里,但若只是简单实现 RabbitMQ 开机自启动,Supervior 无疑是可以胜任的
使用 Supervior 托管管理 RabbitMQ 的服务,以节点一为例给出下述配置示例,其他节点只需更改对应的端口号即可。值得一提的是,这里必须指定 environment=HOME=/home/rabbitmq,否则 RabbitMQ 会找不到 .erlang.cookie 而导致启动失败
[program:rabbitmq]
environment=HOME=/home/rabbitmq
directory=/usr/local/rabbitmq
command=/usr/local/rabbitmq/sbin/rabbitmq-server
user=rabbitmq
numprocs=1
autostart=true
autorestart=true
startretries=10
process_name=%(program_name)s
stdout_logfile_backups=5
stdout_logfile_maxbytes=10MB
stdout_logfile=/var/log/supervisor/rabbitmq.log
stderr_logfile_backups=5
stderr_logfile_maxbytes=10MB
stderr_logfile=/var/log/supervisor/rabbitmq-error.log[program:rabbitmq]
environment=HOME=/home/rabbitmq
directory=/usr/local/rabbitmq
command=/usr/local/rabbitmq/sbin/rabbitmq-server
user=rabbitmq
numprocs=1
autostart=true
autorestart=true
startretries=10
process_name=%(program_name)s
stdout_logfile_backups=5
stdout_logfile_maxbytes=10MB
stdout_logfile=/var/log/supervisor/rabbitmq.log
stderr_logfile_backups=5
stderr_logfile_maxbytes=10MB
stderr_logfile=/var/log/supervisor/rabbitmq-error.log以节点一为例通过 Supervisor 管理 RabbitMQ 服务,其他节点不再累述
# 关闭服务
# supervisorctl stop rabbitmq
# 启动服务
# supervisorctl start rabbitmq
# 查看服务状态
# supervisorctl status rabbitmq
# 重启服务
# supervisorctl restart rabbitmq# 关闭服务
# supervisorctl stop rabbitmq
# 启动服务
# supervisorctl start rabbitmq
# 查看服务状态
# supervisorctl status rabbitmq
# 重启服务
# supervisorctl restart rabbitmq7.2systemd
7.3修改端口
RabbitMQ 默认占用 4369、5672、15672、25672 默认端口号,更改默认端口的方法如下:
- 更改 15672 端口,配置文件路径:
/usr/local/rabbitmq/etc/rabbitmq/rabbitmq.config
[
{rabbitmq_management,
[
{listener,
[
{port, 15672},
{ip, "0.0.0.0"},
{ssl, false}
]
}
]
}
][
{rabbitmq_management,
[
{listener,
[
{port, 15672},
{ip, "0.0.0.0"},
{ssl, false}
]
}
]
}
]- 更改 5672、25672 端口,配置文件路径:
/usr/local/rabbitmq/etc/rabbitmq/rabbitmq-env.conf
NODE_PORT=5673
DIST_PORT=25673NODE_PORT=5673
DIST_PORT=25673- 更改 4369 端口,配置文件路径:
/etc/profile,单机可以多个 RabbitMQ 节点共用同一个ERL_EPMD_PORT端口
export ERL_EPMD_PORT=4363export ERL_EPMD_PORT=4363echo "listeners.tcp.default = 5672
management.listener.port = 15672
vm_memory_high_watermark.relative = 0.2
vm_memory_high_watermark_paging_ratio = 0.2
disk_free_limit.absolute = 1GB
cluster_partition_handling = autoheal
default_vhost = /">>rabbitmq2.confecho "listeners.tcp.default = 5672
management.listener.port = 15672
vm_memory_high_watermark.relative = 0.2
vm_memory_high_watermark_paging_ratio = 0.2
disk_free_limit.absolute = 1GB
cluster_partition_handling = autoheal
default_vhost = /">>rabbitmq2.conf8.集群操作
重新将节点加入集群
这里假设由于各种原因(例如断电重启、节点宕机重启),节点二无法成功加入到集群,那么可以执行以下操作来解决。特别注意,以下操作会删除节点二的元数据(虚拟机、用户、角色、权限、已持久化的消息等),因此当节点二成功加入集群后,必须重新配置节点二的虚拟机、用户、角色、权限等,否则 RabbitMQ 客户端将无法连接节点二
移出集群
首先在节点一里,将节点二移出集群
# 进入节点一的安装目录
# cd /usr/local/rabbitmq/sbin
# 将节点二移出集群
# ./rabbitmqctl -n rabbit@rabbitmq1 forget_cluster_node rabbit@rabbitmq2# 进入节点一的安装目录
# cd /usr/local/rabbitmq/sbin
# 将节点二移出集群
# ./rabbitmqctl -n rabbit@rabbitmq1 forget_cluster_node rabbit@rabbitmq2然后重置节点二的元数据、集群配置等信息,其中会删除虚拟机、用户、角色、权限、已持久化的消息等元数据
# 进入节点二的安装目录
# cd /usr/local/rabbitmq/sbin
# 后台启动节点二的RabbitMQ服务
# ./rabbitmq-server -detached
# 停止节点二的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq2 stop_app
# 重置节点二的元数据、集群配置等信息
# ./rabbitmqctl -n rabbit@rabbitmq2 reset
# 重新将节点二加入到集群
# ./rabbitmqctl -n rabbit@rabbitmq2 join_cluster rabbit@rabbitmq1 --ram
# 启动节点二的RabbitMQ服务
# ./rabbitmqctl -n rabbit@rabbitmq2 start_app# 进入节点二的安装目录
# cd /usr/local/rabbitmq/sbin
# 后台启动节点二的RabbitMQ服务
# ./rabbitmq-server -detached
# 停止节点二的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq2 stop_app
# 重置节点二的元数据、集群配置等信息
# ./rabbitmqctl -n rabbit@rabbitmq2 reset
# 重新将节点二加入到集群
# ./rabbitmqctl -n rabbit@rabbitmq2 join_cluster rabbit@rabbitmq1 --ram
# 启动节点二的RabbitMQ服务
# ./rabbitmqctl -n rabbit@rabbitmq2 start_app如果节点二仍然无法加入集群,可以直接删除节点二的所有数据库文件,然后重启节点二的 RabbitMQ 服务,最后重新将节点二加入到集群
# 进入节点二的安装目录
# cd /usr/local/rabbitmq/sbin
# 彻底关闭节点二的RabbitMQ服务
# ./rabbitmqctl -n rabbit@rabbitmq2 stop
# 删除节点二的数据文件
# rm -rf /usr/local/rabbitmq/var/lib/rabbitmq/mnesia/*
# 后台启动节点二的RabbitMQ服务
# ./rabbitmq-server -detached
# 停止节点二的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq2 stop_app
# 重置节点二的元数据、集群配置等信息
# ./rabbitmqctl -n rabbit@rabbitmq2 reset
# 重新将节点二加入到集群
# ./rabbitmqctl -n rabbit@rabbitmq2 join_cluster rabbit@rabbitmq1 --ram
# 启动节点二的RabbitMQ服务
# ./rabbitmqctl -n rabbit@rabbitmq2 start_app# 进入节点二的安装目录
# cd /usr/local/rabbitmq/sbin
# 彻底关闭节点二的RabbitMQ服务
# ./rabbitmqctl -n rabbit@rabbitmq2 stop
# 删除节点二的数据文件
# rm -rf /usr/local/rabbitmq/var/lib/rabbitmq/mnesia/*
# 后台启动节点二的RabbitMQ服务
# ./rabbitmq-server -detached
# 停止节点二的RabbitMQ的服务
# ./rabbitmqctl -n rabbit@rabbitmq2 stop_app
# 重置节点二的元数据、集群配置等信息
# ./rabbitmqctl -n rabbit@rabbitmq2 reset
# 重新将节点二加入到集群
# ./rabbitmqctl -n rabbit@rabbitmq2 join_cluster rabbit@rabbitmq1 --ram
# 启动节点二的RabbitMQ服务
# ./rabbitmqctl -n rabbit@rabbitmq2 start_app强制重置节点,force_reset 命令和 reset 的区别是无条件重置节点,不管当前管理数据库状态以及集群的配置,如果数据库或者集群配置发生错误才使用这个最后的手段
# ./rabbitmqctl force_reset# ./rabbitmqctl force_reset加入集群
$ rabbitmqctl -n rabbit2 stop_app
$ rabbitmqctl -n rabbit2 reset
$ rabbitmqctl -n rabbit2 join_cluster rabbit1
$ rabbitmqctl -n rabbit2 start_app$ rabbitmqctl -n rabbit2 stop_app
$ rabbitmqctl -n rabbit2 reset
$ rabbitmqctl -n rabbit2 join_cluster rabbit1
$ rabbitmqctl -n rabbit2 start_app8.2RabbitMQ 无法操作集群节点
若执行以下命令出现下述的错误,一般是当前执行操作的用户的家目录下的 .erlang.cookie 与 集群节点的 .erlang.cookie 不一致导致。解决办法是集群节点是以哪个用户启动的,就切换到对应的用户,例如 su rabbitmq ,然后再执行集群操作命令
# 查看集群状态
# ./rabbitmqctl cluster_status# 查看集群状态
# ./rabbitmqctl cluster_status执行集群状态查看命令,出现以下错误信息
Error: unable to perform an operation on node 'rabbit2@rabbitmq2'. Please see diagnostics information and suggestions below.
Most common reasons for this are:
* Target node is unreachable (e.g. due to hostname resolution, TCP connection or firewall issues)
* CLI tool fails to authenticate with the server (e.g. due to CLI tool's Erlang cookie not matching that of the server)
* Target node is not running
In addition to the diagnostics info below:
* See the CLI, clustering and networking guides on https://rabbitmq.com/documentation.html to learn more
* Consult server logs on node rabbit2@rabbitmq2
* If target node is configured to use long node names, don't forget to use --longnames with CLI tools
DIAGNOSTICS
===========
attempted to contact: [rabbit2@rabbitmq2]
rabbit2@rabbitmq2:
* connected to epmd (port 4369) on rabbitmq2
* epmd reports node 'rabbit2' uses port 25674 for inter-node and CLI tool traffic
* TCP connection succeeded but Erlang distribution failed
* Authentication failed (rejected by the remote node), please check the Erlang cookie
Current node details:
* node name: 'rabbitmqcli-7936-rabbit2@rabbitmq2'
* effective user's home directory: /home/centos
* Erlang cookie hash: 5hmDFFQNoU5sdfrafENxAg==Error: unable to perform an operation on node 'rabbit2@rabbitmq2'. Please see diagnostics information and suggestions below.
Most common reasons for this are:
* Target node is unreachable (e.g. due to hostname resolution, TCP connection or firewall issues)
* CLI tool fails to authenticate with the server (e.g. due to CLI tool's Erlang cookie not matching that of the server)
* Target node is not running
In addition to the diagnostics info below:
* See the CLI, clustering and networking guides on https://rabbitmq.com/documentation.html to learn more
* Consult server logs on node rabbit2@rabbitmq2
* If target node is configured to use long node names, don't forget to use --longnames with CLI tools
DIAGNOSTICS
===========
attempted to contact: [rabbit2@rabbitmq2]
rabbit2@rabbitmq2:
* connected to epmd (port 4369) on rabbitmq2
* epmd reports node 'rabbit2' uses port 25674 for inter-node and CLI tool traffic
* TCP connection succeeded but Erlang distribution failed
* Authentication failed (rejected by the remote node), please check the Erlang cookie
Current node details:
* node name: 'rabbitmqcli-7936-rabbit2@rabbitmq2'
* effective user's home directory: /home/centos
* Erlang cookie hash: 5hmDFFQNoU5sdfrafENxAg==8.3重置节点
rabbitmqctl resetrabbitmqctl reset8.4移除节点
- 集群删除节点,就在哪个节点上操作
# on rabbit3
rabbitmqctl stop_app
# => Stopping node rabbit@rabbit3 ...done.
rabbitmqctl reset
# => Resetting node rabbit@rabbit3 ...done.
rabbitmqctl forget_cluster_node rabbit@rabbit3 #此时会报错,忽略即可
rabbitmqctl start_app
# => Starting node rabbit@rabbit3 ...done.
在节点上运行cluster_status
rabbitmqctl cluster_status
命令可确认rabbit@rabbit3# on rabbit3
rabbitmqctl stop_app
# => Stopping node rabbit@rabbit3 ...done.
rabbitmqctl reset
# => Resetting node rabbit@rabbit3 ...done.
rabbitmqctl forget_cluster_node rabbit@rabbit3 #此时会报错,忽略即可
rabbitmqctl start_app
# => Starting node rabbit@rabbit3 ...done.
在节点上运行cluster_status
rabbitmqctl cluster_status
命令可确认rabbit@rabbit38.5修改节点类型
修改集群节点类型disc为ram类型
- 查看集群状态
rabbitmqctl cluster_statusrabbitmqctl cluster_status- 停止
rabbitmqctl stop_apprabbitmqctl stop_app- 修改ram类型,在需要改变类型节点上操作
rabbitmqctl change_cluster_node_type ram
#disc
rabbitmqctl change_cluster_node_type discrabbitmqctl change_cluster_node_type ram
#disc
rabbitmqctl change_cluster_node_type disc- 启动
rabbitmqctl start_apprabbitmqctl start_app8.6修改集群名字
#rabbitmqctl cluster_status
#设置集群名字
#rabbitmqctl set_cluster_name ha_rmq_cluster#rabbitmqctl cluster_status
#设置集群名字
#rabbitmqctl set_cluster_name ha_rmq_cluster9.RabbitMQ集群恢复与故障转移
前提 : A, B两个节点组成一个镜像队列, B是Master节点
场景一:A先停, B后停
解决方案 : 该场景下B是Master, 只要先启动B, 在启动A即可。或者先启动A, 30秒之内启动B即可恢复镜像队列
场景二:A, B同时停机
解决方案 : 只需要在30秒内连续启动A和B即可恢复镜像
场景三:A先停, B后停, 且A无法恢复
解决场景 : 因为B是Master, 所以等B启起来以后, 在B节点上调用控制台命令 : rabbitmqctl forget_cluster_node A解除与A的Cluster关系, 再将新的Slave节点加入B即可重新恢复镜像队列
场景四:A先停, B后停, 且B无法恢复
解决方案 :
因为Master节点无法恢复, 所以较难处理, 在3.4.2之前没有什么好的解决方案, 但是现在已经有解决方案了, 在3.4.2以后的版本。
因为B是主节点, 所以直接启动A是不行的, 当A无法启动时, 也就没有办法在A节点上调用rabbitmqctl forget_cluster_node B 命令了。但是在新版本中forget_cluster_node支持–offline参数, 支持线下移除节点。
这就意味着运行rabbitmqctl在理想节点上执行命令, 迫使RabbitMQ在未启动Slave节点中选择一个节点作为Master。
当在A节点执行**rabbitmqctl forget_cluster_node --offline B **时, RabbitMQ会mock一个节点代表A, 执行 forget_cluster_node命令将B移除cluster, 然后A就可以正常启动了, 最后将新的Slave节点加入A即可重新恢复镜像队列
场景五:A先停, B后停, 且A, B均无法恢复, 但是能得到A或B的磁盘文件
解决方案 : 这种场景更加难以处理, 只能通过恢复数据的方式去尝试恢复, 将A或B的数据库文件默认在$RABBIT_HOME/var/lib目录中, 把它拷贝到新节点对应的目录下, 再将新节点的hostname改成A或B的hostname, 如果是A节点(Slave)的磁盘文件, 按照场景四处理即可, 如果是B节点(Master)的磁盘文件, 则按照场景三处理, 最后将新的Slave加入到新节点后完成恢复 这种场景很极端, 只能尝试恢复