 SRE文档
SRE文档1. PromQL 操作符
Prometheus 的查询语言支持基本的逻辑和算术运算符。对于两个即时向量之间的运算,匹配行为 可以修改
1.1 二元操作符
PromQL 的二元操作符支持基本的逻辑和算术运算,包含算术类、比较类和逻辑类三大类
1.算术类二元操作符
算术类二元操作符有以下几种:
+:加-:减*:乘/:除%:求余^:乘方或者求幂
算术类二元操作符可以使用在标量与标量、向量与标量,以及向量与向量之间。
比如:标量与标量
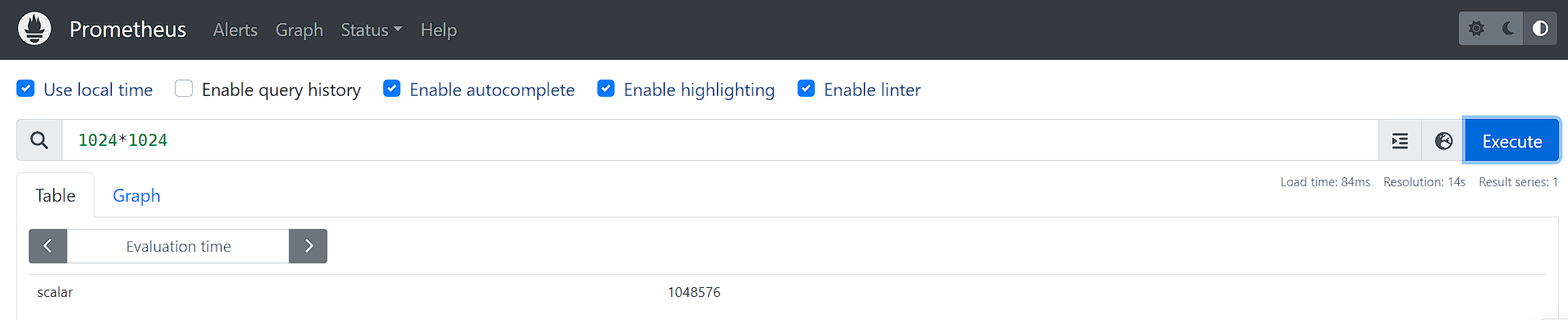
比如:即时向量与标量
计算内存
node_memory_MemTotal_bytes/(1024*1024)node_memory_MemTotal_bytes/(1024*1024)
比如:向量和向量
获取内存使用率
node_memory_Active_bytes / node_memory_MemTotal_bytes * 100node_memory_Active_bytes / node_memory_MemTotal_bytes * 100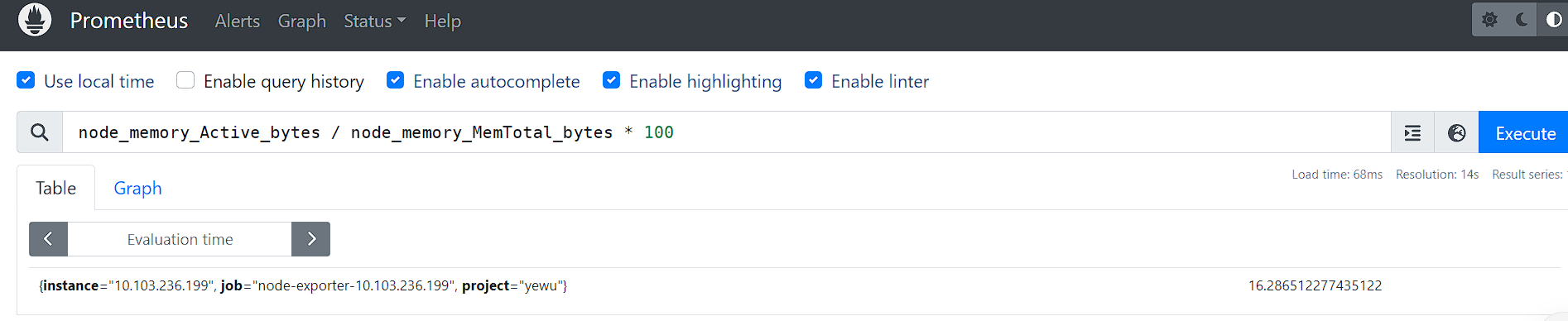
二元操作符上下文里的向量特指瞬时向量,不包括区间向量。
- 标量与标量之间,结果很明显,跟通常的算术运算一致。
- 向量与标量之间,相当于把标量跟向量里的每一个标量进行运算,这些计算结果组成了一个新的向量。
- 向量与向量之间,会稍微麻烦一些。运算的时候首先会为左边向量里的每一个元素在右边向量里去寻找一个匹配元素(匹配规则后面会讲),然后对这两个匹配元素执行计算,这样每对匹配元素的计算结果组成了一个新的向量。如果没有找到匹配元素,则该元素丢弃。
2.比较类二元操作符
比较类二元操作符有以下几种:
==(equal)!=(not-equal)>(greater-than)<(less-than)>=(greater-or-equal)<=(less-or-equal)
比较类二元操作符同样可以使用在标量与标量、向量与标量,以及向量与向量之间。默认执行的是过滤,也就是保留值。
也可以通过在运算符后面跟 bool 修饰符来使得返回值 0 和 1,而不是过滤。
- 标量与标量之间,必须跟 bool 修饰符,因此结果只可能是 0(false) 或 1(true)。
- 向量与标量之间,相当于把向量里的每一个标量跟标量进行比较,结果为真则保留,否则丢弃。如果后面跟了 bool 修饰符,则结果分别为 1 和 0。
- 向量与向量之间,运算过程类似于算术类操作符,只不过如果比较结果为真则保留左边的值(包括度量指标和标签这些属性),否则丢弃,没找到匹配也是丢弃。如果后面跟了 bool 修饰符,则保留和丢弃时结果相应为 1 和 0。
比如:标量与标量
12 > bool 1012 > bool 10比如:即时向量与标量
node_load1 > bool 1node_load1 > bool 1比如:向量与向量
node_memory_MemAvailable_bytes > bool node_memory_MemTotal_bytesnode_memory_MemAvailable_bytes > bool node_memory_MemTotal_bytes3.逻辑类二元操作符
逻辑操作符仅用于向量与向量之间。
and:交集or:合集unless:补集
具体运算规则如下:
vector1 and vector2的结果由在 vector2 里有匹配(标签键值对组合相同)元素的 vector1 里的元素组成。vector1 or vector2的结果由所有 vector1 里的元素加上在 vector1 里没有匹配(标签键值对组合相同)元素的 vector2 里的元素组成。vector1 unless vector2的结果由在 vector2 里没有匹配(标签键值对组合相同)元素的 vector1 里的元素组成。
node_cpu_seconds_total{mode=~"idle|user"} and node_cpu_seconds_total{mode=~"system|user"}node_cpu_seconds_total{mode=~"idle|user"} and node_cpu_seconds_total{mode=~"system|user"}4.二元操作符优先级
PromQL 的各类二元操作符运算优先级如下:
^*, /, %+, -==, !=, <=, <, >=, >and, unless->逻辑运算or->逻辑运算
and
and逻辑运算会产生一个由vector1的元素组成的新的向量。该向量包含vector1中完全匹配vector2中的元素。表达式示例如下:当多个条件被同时满足时进行显示
node_filesystem_size_bytes{fstype!="tmpfs"} and node_filesystem_size_bytes != 0 and node_filesystem_size_bytes{mountpoint="/root-disk"}node_filesystem_size_bytes{fstype!="tmpfs"} and node_filesystem_size_bytes != 0 and node_filesystem_size_bytes{mountpoint="/root-disk"}or
or逻辑运算会产生一个新的向量,该向量包含vector1的所有原始元素(标签集+值)的向量,以及vector2中没有与vector1匹配标签集的所有元素。假设判断node_test_metric指标是否存在,如果指标不存在则返回0。在这种情况下,我们可以使用与每个目标关联的up指标进行表达式操作:
node_filesystem_avail_bytes > 200000 or node_filesystem_avail_bytes < 2500000node_filesystem_avail_bytes > 200000 or node_filesystem_avail_bytes < 2500000unless
#当第一个值的标签和第二个值的标签不匹配的情况下会输出
up{instance="192.168.1.20:9100",job="node"} unless up{instance="192.168.1.21:9100",job="node"}
#当标签相同时则不输出
up{instance="192.168.1.20:9100",job="node"} unless up{instance="192.168.1.20:9100",job="node"}#当第一个值的标签和第二个值的标签不匹配的情况下会输出
up{instance="192.168.1.20:9100",job="node"} unless up{instance="192.168.1.21:9100",job="node"}
#当标签相同时则不输出
up{instance="192.168.1.20:9100",job="node"} unless up{instance="192.168.1.20:9100",job="node"}1.2 向量匹配
算术类和比较类操作符都需要在向量之间进行匹配。共有两种匹配类型,one-to-one 和 many-to-one / one-to-many
1.One-to-one 向量匹配
这种匹配模式下,两边向量里的元素如果其标签键值对组合相同则为匹配,并且只会有一个匹配元素。可以使用 ignoring 关键词来忽略不参与匹配的标签,或者使用 on 关键词来指定要参与匹配的标签。语法如下:
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr><vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr>比如:
process_open_fds{instance="10.103.236.199", job="node-exporter-10.103.236.199"}
/
process_max_fds{instance="10.103.236.199", job="node-exporter-10.103.236.199"}process_open_fds{instance="10.103.236.199", job="node-exporter-10.103.236.199"}
/
process_max_fds{instance="10.103.236.199", job="node-exporter-10.103.236.199"}比如:ignoring
node_disk_read_time_seconds_total{device="nvme0n1"} + ignoring(device) node_disk_read_time_seconds_total{device="dm-0"}node_disk_read_time_seconds_total{device="nvme0n1"} + ignoring(device) node_disk_read_time_seconds_total{device="dm-0"}💡 说明
记住一句话两个向量之间做运算必须两边的标签名和标签值必须匹配才能做计算
比如:
#表达式中使用到了rate()函数,即计算某个时间序列范围内的平均增长率
sum (rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) / sum (rate(node_cpu_seconds_total[5m])) by (instance)#表达式中使用到了rate()函数,即计算某个时间序列范围内的平均增长率
sum (rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) / sum (rate(node_cpu_seconds_total[5m])) by (instance)2.Many-to-one / one-to-many 向量匹配
多对一和一对多的匹配模式,可以理解为如果两个瞬时向量数量不一致时可通过。这时就需要使用 group_left 或 group_right 组修饰符来指明哪边匹配元素较多,左边多则用 group_left,右边多则用 group_right。其语法如下:
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr><vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>比如:
sum by (node) ((kube_pod_status_phase{phase="Running"} == 1) + on(pod) group_left(node) (0 * kube_pod_info{pod_template_hash=""})) / sum by (node) (kube_node_status_allocatable{resource="pods"}) * 100 > 90sum by (node) ((kube_pod_status_phase{phase="Running"} == 1) + on(pod) group_left(node) (0 * kube_pod_info{pod_template_hash=""})) / sum by (node) (kube_node_status_allocatable{resource="pods"}) * 100 > 901.3 聚合操作符
PromQL 的聚合操作符用来将向量里的元素聚合得更少。总共有下面这些聚合操作符:
| 操作符 | 描述 |
|---|---|
| sum | 求和 |
| min | 最小值 |
| max | 最大值 |
| avg | 平均值 |
| stddev | 标准差 |
| stdvar | 方差 |
| count | 元素个数 |
count_values,支持parameter | 等于某值的元素个数 |
bottomk,支持parameter | 最小的 k 个元素 |
topk,支持parameter | 最大的 k 个元素 |
quantile,支持parameter | 分位数 |
| limitk(使用limit的开启 --enable-feature=promql-experimental-functions功能) | |
| limit_ratio |
聚合操作符语法如下:
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]其中 without 用来指定不需要保留的标签(也就是这些标签的多个值会被聚合),而 by 正好相反,用来指定需要保留的标签(也就是按这些标签来聚合)
1.sum
sum和without是同时存在的
sum(node_timex_sync_status) without (job,mode)
等价于
sum(node_timex_sync_status) by (instance) sum(node_timex_sync_status) without (job,mode)
等价于
sum(node_timex_sync_status) by (instance)2.max
返回所有记录的最大值
max(node_cpu_seconds_total) by (mode)max(node_cpu_seconds_total) by (mode)3.avg
avg 函数返回所有记录的平均值。
avg(node_cpu_seconds_total) by (mode)avg(node_cpu_seconds_total) by (mode)cpu大于80%
100 -(avg by(instance)(rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100)> 80100 -(avg by(instance)(rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100)> 804.count
count 函数返回所有记录的计数。
例如:count(prometheus_http_requests_total) 表示统计所有 HTTP 请求的次数。
count(prometheus_http_requests_total)count(prometheus_http_requests_total)5.bottomk(后几条)
统计最小的几个值。从最小往下依次增大进行排序
bottomk(3,sum(node_cpu_seconds_total)by (mode))
3--->代表是展示几个bottomk(3,sum(node_cpu_seconds_total)by (mode))
3--->代表是展示几个6.topk(前几条)
统计最大的几个值
topk(3,sum(node_cpu_seconds_total)by (mode))topk(3,sum(node_cpu_seconds_total)by (mode))