 SRE文档
SRE文档官方文档,https://docs.microsoft.com/zh-cn/sql/t-sql/statements/statements?view=sql-server-2017
一、查询
1.1 查看单表大小
- 使用sp_spaceused 存储过程
统计单个表的使用空间
exec sp_spaceused 'dbo.t1'
统计每个表的使用空间
exec sp_MSforeachtable "exec sp_spaceused '?'"统计单个表的使用空间
exec sp_spaceused 'dbo.t1'
统计每个表的使用空间
exec sp_MSforeachtable "exec sp_spaceused '?'"1.2 列出每个表所占用空间大小
SELECT
t.NAME AS TableName,
s.Name AS SchemaName,
p.rows AS RowCounts,
SUM(a.total_pages) * 8 AS TotalSpaceKB,
CAST(ROUND(((SUM(a.total_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS TotalSpaceMB,
SUM(a.used_pages) * 8 AS UsedSpaceKB,
CAST(ROUND(((SUM(a.used_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS UsedSpaceMB,
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS UnusedSpaceKB,
CAST(ROUND(((SUM(a.total_pages) - SUM(a.used_pages)) * 8) / 1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
LEFT OUTER JOIN
sys.schemas s ON t.schema_id = s.schema_id
WHERE
t.NAME NOT LIKE 'dt%'
AND t.is_ms_shipped = 0
AND i.OBJECT_ID > 255
GROUP BY
t.Name, s.Name, p.Rows
ORDER BY
t.NameSELECT
t.NAME AS TableName,
s.Name AS SchemaName,
p.rows AS RowCounts,
SUM(a.total_pages) * 8 AS TotalSpaceKB,
CAST(ROUND(((SUM(a.total_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS TotalSpaceMB,
SUM(a.used_pages) * 8 AS UsedSpaceKB,
CAST(ROUND(((SUM(a.used_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS UsedSpaceMB,
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS UnusedSpaceKB,
CAST(ROUND(((SUM(a.total_pages) - SUM(a.used_pages)) * 8) / 1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
LEFT OUTER JOIN
sys.schemas s ON t.schema_id = s.schema_id
WHERE
t.NAME NOT LIKE 'dt%'
AND t.is_ms_shipped = 0
AND i.OBJECT_ID > 255
GROUP BY
t.Name, s.Name, p.Rows
ORDER BY
t.Name1.3 查询当前数据库的磁盘使用情况
Exec sp_spaceused

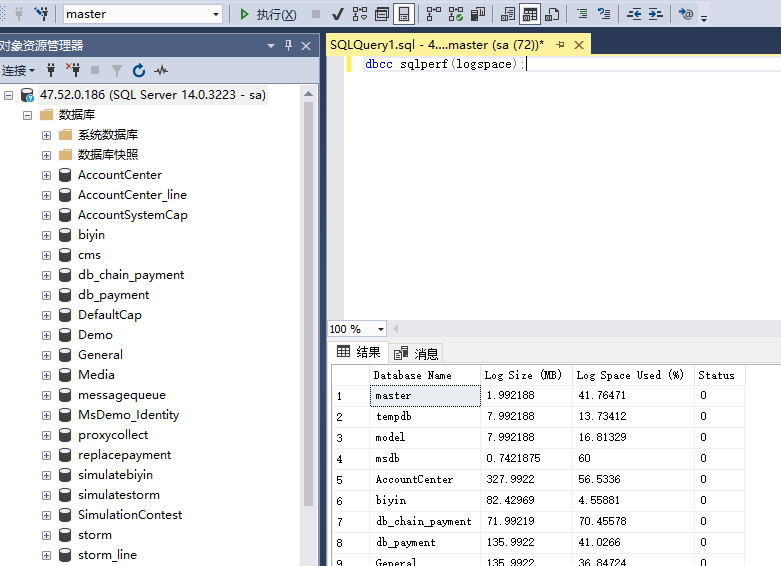
查询数据库服务器各数据库日志文件的大小及利用率
DBCC SQLPERF(LOGSPACE)
1.4 查看单个数据库大小
exec sp_helpdb db_nameexec sp_helpdb db_name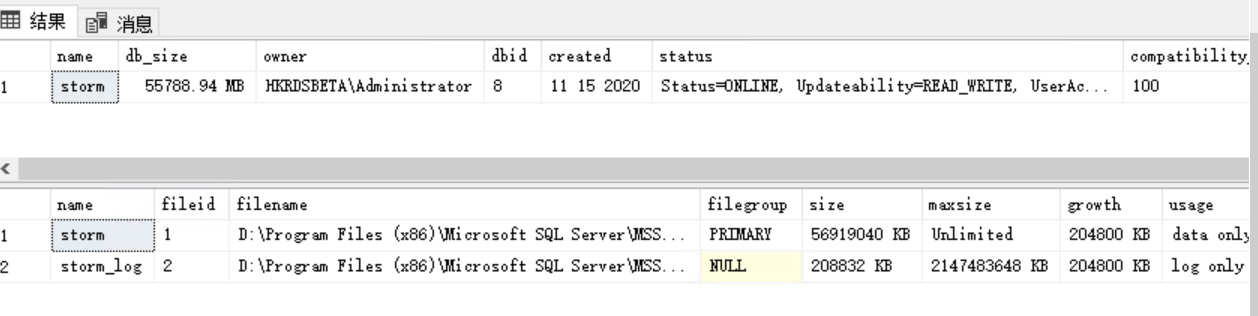
但是注意:该命令显示的数据库大小**"db_size"并不是指现存有效数据的大小**,而是指:数据库物理文件 “数据文件大小 + 日志文件大小”的总和
查看所有数据库大小
SELECT DB_NAME(database_id) AS [Database Name],
[Name] AS [Logical Name],
[Physical_Name] AS [Physical Name],
((size * 8) / 1024) AS [Size(MB)],
[differential_base_time] AS [Differential Base Time]
FROM sys.master_files
order by 4 descSELECT DB_NAME(database_id) AS [Database Name],
[Name] AS [Logical Name],
[Physical_Name] AS [Physical Name],
((size * 8) / 1024) AS [Size(MB)],
[differential_base_time] AS [Differential Base Time]
FROM sys.master_files
order by 4 desc或者
SELECT
name AS DatabaseName,
size * 8 / 1024 AS SizeMB,
size * 8 / 1024 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT) * 8 / 1024 AS UnusedSpaceMB
FROM
sys.master_files
WHERE type = 0 -- 数据文件类型(不包括日志文件)
ORDER BY SizeMB DESC;SELECT
name AS DatabaseName,
size * 8 / 1024 AS SizeMB,
size * 8 / 1024 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT) * 8 / 1024 AS UnusedSpaceMB
FROM
sys.master_files
WHERE type = 0 -- 数据文件类型(不包括日志文件)
ORDER BY SizeMB DESC;1.5查看所有表大小
USE tempdb
IF OBJECT_ID('tempdb..#db', 'U') <> 0
DROP TABLE #db
IF OBJECT_ID('tempdb..#tb', 'U') <> 0
DROP TABLE #tb
IF OBJECT_ID('tempdb..#dbtable', 'U') <> 0
DROP TABLE #dbtable
CREATE TABLE #tb(name varchar(200),rows bigint,reserved varchar(200),data varchar(200),index_size varchar(200),unused varchar(200));
CREATE TABLE #dbtable(db varchar(100),name varchar(200),rows bigint,reserved varchar(200),data varchar(200),index_size varchar(200),unused varchar(200))
SELECT name, px = ROW_NUMBER() OVER(ORDER BY(SELECT 1)) INTO #db FROM sys.databases WITH(NOLOCK) WHERE state = 0 AND database_id > 4
-- and name = 'hantest'
DECLARE @sql varchar(max)
DECLARE @px int
DECLARE @dbname sysname
DECLARE @tdbname sysname
DECLARE @px2 int
SELECT @dbname = name, @px = px FROM #db WHERE px = 1;
WHILE @@rowcount > 0
BEGIN
SET @sql = 'use ' +QUOTENAME(@dbname)+ CHAR(10)
+ 'exec sp_msforeachtable ''
insert into #tb execute sp_spaceused ''''?'''';''
insert into #dbtable select '''+@dbname+''',* from #tb
truncate table #tb'
EXECUTE(@sql)
SELECT TOP(1) @dbname = name, @px = px FROM #db WHERE px > @px;
END
SELECT
db AS [database_name]
,name AS [table_name]
,rows
,CONVERT(NUMERIC(18,2),CONVERT(NUMERIC(18,2),SUBSTRING(reserved,1,LEN(reserved)-2))/1024) AS reserved_size_MB
,CONVERT(NUMERIC(18,2),CONVERT(NUMERIC(18,2),SUBSTRING(data,1,LEN(data)-2))/1024) AS data_size_MB
,CONVERT(NUMERIC(18,2),CONVERT(NUMERIC(18,2),SUBSTRING(index_size,1,LEN(index_size)-2))/1024) AS index_size_MB
,CONVERT(NUMERIC(18,2),CONVERT(NUMERIC(18,2),SUBSTRING(unused,1,LEN(unused)-2))/1024) AS unused_size_MB
FROM #dbtable
--WHERE rows <> '0'
ORDER BY CONVERT(BIGINT,LEFT(reserved,LEN(reserved)-2)) DESCUSE tempdb
IF OBJECT_ID('tempdb..#db', 'U') <> 0
DROP TABLE #db
IF OBJECT_ID('tempdb..#tb', 'U') <> 0
DROP TABLE #tb
IF OBJECT_ID('tempdb..#dbtable', 'U') <> 0
DROP TABLE #dbtable
CREATE TABLE #tb(name varchar(200),rows bigint,reserved varchar(200),data varchar(200),index_size varchar(200),unused varchar(200));
CREATE TABLE #dbtable(db varchar(100),name varchar(200),rows bigint,reserved varchar(200),data varchar(200),index_size varchar(200),unused varchar(200))
SELECT name, px = ROW_NUMBER() OVER(ORDER BY(SELECT 1)) INTO #db FROM sys.databases WITH(NOLOCK) WHERE state = 0 AND database_id > 4
-- and name = 'hantest'
DECLARE @sql varchar(max)
DECLARE @px int
DECLARE @dbname sysname
DECLARE @tdbname sysname
DECLARE @px2 int
SELECT @dbname = name, @px = px FROM #db WHERE px = 1;
WHILE @@rowcount > 0
BEGIN
SET @sql = 'use ' +QUOTENAME(@dbname)+ CHAR(10)
+ 'exec sp_msforeachtable ''
insert into #tb execute sp_spaceused ''''?'''';''
insert into #dbtable select '''+@dbname+''',* from #tb
truncate table #tb'
EXECUTE(@sql)
SELECT TOP(1) @dbname = name, @px = px FROM #db WHERE px > @px;
END
SELECT
db AS [database_name]
,name AS [table_name]
,rows
,CONVERT(NUMERIC(18,2),CONVERT(NUMERIC(18,2),SUBSTRING(reserved,1,LEN(reserved)-2))/1024) AS reserved_size_MB
,CONVERT(NUMERIC(18,2),CONVERT(NUMERIC(18,2),SUBSTRING(data,1,LEN(data)-2))/1024) AS data_size_MB
,CONVERT(NUMERIC(18,2),CONVERT(NUMERIC(18,2),SUBSTRING(index_size,1,LEN(index_size)-2))/1024) AS index_size_MB
,CONVERT(NUMERIC(18,2),CONVERT(NUMERIC(18,2),SUBSTRING(unused,1,LEN(unused)-2))/1024) AS unused_size_MB
FROM #dbtable
--WHERE rows <> '0'
ORDER BY CONVERT(BIGINT,LEFT(reserved,LEN(reserved)-2)) DESC
1.6查看特定库所有表
use db_name
go
select * from sys.tablesuse db_name
go
select * from sys.tablesSELECT
t.NAME AS TableName,
s.Name AS SchemaName,
p.rows AS RowCounts,
SUM(a.total_pages) * 8 AS TotalSpaceKB,
CAST(ROUND(((SUM(a.total_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS TotalSpaceMB,
SUM(a.used_pages) * 8 AS UsedSpaceKB,
CAST(ROUND(((SUM(a.used_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS UsedSpaceMB,
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS UnusedSpaceKB,
CAST(ROUND(((SUM(a.total_pages) - SUM(a.used_pages)) * 8) / 1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
LEFT OUTER JOIN
sys.schemas s ON t.schema_id = s.schema_id
WHERE
t.NAME NOT LIKE 'dt%'
AND t.is_ms_shipped = 0
AND i.OBJECT_ID > 255
GROUP BY
t.Name, s.Name, p.Rows
ORDER BY
UsedSpaceMB desc,
t.NameSELECT
t.NAME AS TableName,
s.Name AS SchemaName,
p.rows AS RowCounts,
SUM(a.total_pages) * 8 AS TotalSpaceKB,
CAST(ROUND(((SUM(a.total_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS TotalSpaceMB,
SUM(a.used_pages) * 8 AS UsedSpaceKB,
CAST(ROUND(((SUM(a.used_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS UsedSpaceMB,
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS UnusedSpaceKB,
CAST(ROUND(((SUM(a.total_pages) - SUM(a.used_pages)) * 8) / 1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
LEFT OUTER JOIN
sys.schemas s ON t.schema_id = s.schema_id
WHERE
t.NAME NOT LIKE 'dt%'
AND t.is_ms_shipped = 0
AND i.OBJECT_ID > 255
GROUP BY
t.Name, s.Name, p.Rows
ORDER BY
UsedSpaceMB desc,
t.Name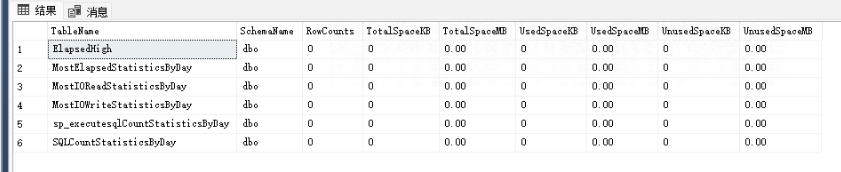
或者
USE master;
SELECT
t.name AS TableName,
p.rows AS RowCounts,
SUM(a.total_pages) * 8 / 1024 AS TotalSpaceMB,
SUM(a.used_pages) * 8 / 1024 AS UsedSpaceMB,
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 / 1024 AS UnusedSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.object_id = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
GROUP BY
t.name, p.rows
ORDER BY
TotalSpaceMB DESC;USE master;
SELECT
t.name AS TableName,
p.rows AS RowCounts,
SUM(a.total_pages) * 8 / 1024 AS TotalSpaceMB,
SUM(a.used_pages) * 8 / 1024 AS UsedSpaceMB,
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 / 1024 AS UnusedSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.object_id = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
GROUP BY
t.name, p.rows
ORDER BY
TotalSpaceMB DESC;查看当前库中有多少表
SELECT
CASE
WHEN
xtype = 'U' THEN
'表'
WHEN xtype = 'P' THEN
'存储过程'
WHEN xtype = 'FN' THEN
'标量值函数'
WHEN xtype = 'IF' THEN
'表值函数'
WHEN xtype = 'V' THEN
'视图'
WHEN xtype = 'TR' THEN
'触发器'
WHEN xtype = 'SN' THEN
'同义词'
END AS xtype,
COUNT ( * ) cnt
FROM
sysobjects
WHERE
xtype IN ( 'P', 'FN', 'IF', 'TR', 'TR', 'U', 'V' )
AND uid = 1
AND category = 0
GROUP BY
xtype
ORDER BY
xtype;SELECT
CASE
WHEN
xtype = 'U' THEN
'表'
WHEN xtype = 'P' THEN
'存储过程'
WHEN xtype = 'FN' THEN
'标量值函数'
WHEN xtype = 'IF' THEN
'表值函数'
WHEN xtype = 'V' THEN
'视图'
WHEN xtype = 'TR' THEN
'触发器'
WHEN xtype = 'SN' THEN
'同义词'
END AS xtype,
COUNT ( * ) cnt
FROM
sysobjects
WHERE
xtype IN ( 'P', 'FN', 'IF', 'TR', 'TR', 'U', 'V' )
AND uid = 1
AND category = 0
GROUP BY
xtype
ORDER BY
xtype;1.7检查数据文件空间使用率
use DB_NAME
-- 检查数据库文件空间使用率
SELECT a.name [文件名称] ,cast(a.[size]*1.0/128 as decimal(12,1)) AS [文件设置大小(MB)] ,
CAST( fileproperty(s.name,'SpaceUsed')/(8*16.0) AS DECIMAL(12,1)) AS [文件所占空间(MB)] ,
CAST( (fileproperty(s.name,'SpaceUsed')/(8*16.0))/(s.size/(8*16.0))*100.0 AS DECIMAL(12,1)) AS [所占空间率%] ,
CASE WHEN A.growth =0 THEN '文件大小固定,不会增长' ELSE '文件将自动增长' end [增长模式] ,CASE WHEN A.growth > 0 AND is_percent_growth = 0
THEN '增量为固定大小' WHEN A.growth > 0 AND is_percent_growth = 1 THEN '增量将用整数百分比表示' ELSE '文件大小固定,不会增长' END AS [增量模式] ,
CASE WHEN A.growth > 0 AND is_percent_growth = 0 THEN cast(cast(a.growth*1.0/128as decimal(12,0)) AS VARCHAR)+'MB'
WHEN A.growth > 0 AND is_percent_growth = 1 THEN cast(cast(a.growth AS decimal(12,0)) AS VARCHAR)+'%' ELSE '文件大小固定,不会增长' end AS [增长值(%或MB)] ,
a.physical_name AS [文件所在目录] ,a.type_desc AS [文件类型]
FROM sys.database_files a
INNER JOIN sys.sysfiles AS s ON a.[file_id]=s.fileid
LEFT JOIN sys.dm_db_file_space_usage b ON a.[file_id]=b.[file_id] ORDER BY a.[type]use DB_NAME
-- 检查数据库文件空间使用率
SELECT a.name [文件名称] ,cast(a.[size]*1.0/128 as decimal(12,1)) AS [文件设置大小(MB)] ,
CAST( fileproperty(s.name,'SpaceUsed')/(8*16.0) AS DECIMAL(12,1)) AS [文件所占空间(MB)] ,
CAST( (fileproperty(s.name,'SpaceUsed')/(8*16.0))/(s.size/(8*16.0))*100.0 AS DECIMAL(12,1)) AS [所占空间率%] ,
CASE WHEN A.growth =0 THEN '文件大小固定,不会增长' ELSE '文件将自动增长' end [增长模式] ,CASE WHEN A.growth > 0 AND is_percent_growth = 0
THEN '增量为固定大小' WHEN A.growth > 0 AND is_percent_growth = 1 THEN '增量将用整数百分比表示' ELSE '文件大小固定,不会增长' END AS [增量模式] ,
CASE WHEN A.growth > 0 AND is_percent_growth = 0 THEN cast(cast(a.growth*1.0/128as decimal(12,0)) AS VARCHAR)+'MB'
WHEN A.growth > 0 AND is_percent_growth = 1 THEN cast(cast(a.growth AS decimal(12,0)) AS VARCHAR)+'%' ELSE '文件大小固定,不会增长' end AS [增长值(%或MB)] ,
a.physical_name AS [文件所在目录] ,a.type_desc AS [文件类型]
FROM sys.database_files a
INNER JOIN sys.sysfiles AS s ON a.[file_id]=s.fileid
LEFT JOIN sys.dm_db_file_space_usage b ON a.[file_id]=b.[file_id] ORDER BY a.[type]1.8kill用户连接数据库
查询数据库ID
Select * from master..sysdatabases where name = 'db_name';Select * from master..sysdatabases where name = 'db_name';获取该数据库的进程
Select * from sys.sysprocesses a where a.dbid = '';Select * from sys.sysprocesses a where a.dbid = '';kill连接在上面的进程
kill spid;kill spid;二、查看物理信息
2.1获取数据库文件物理地址
select * from sys.database_files;select * from sys.database_files;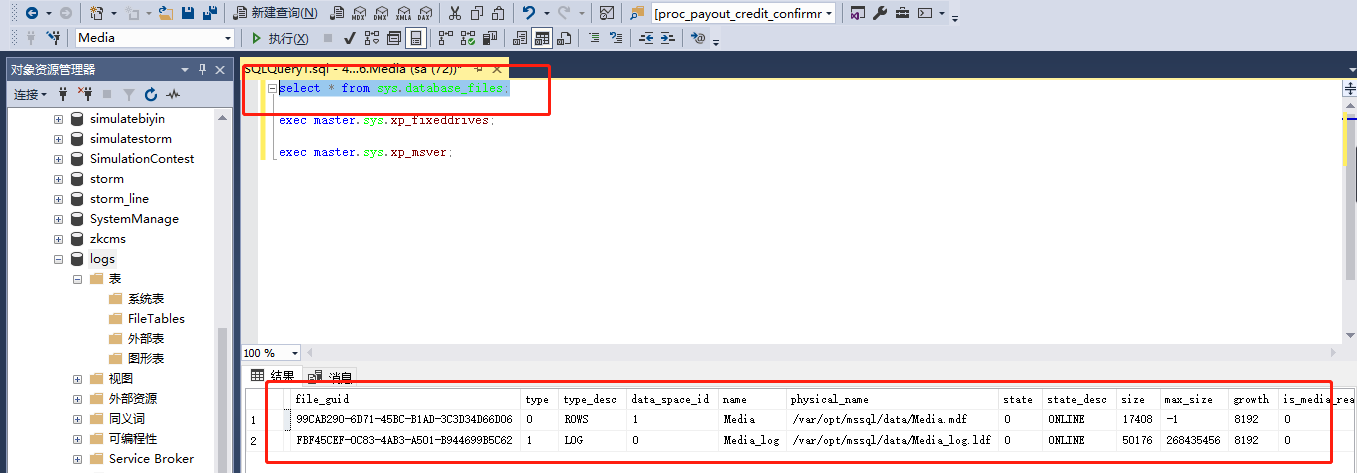
2.2获取服务器磁盘可用信息
exec master.sys.xp_fixeddrives;exec master.sys.xp_fixeddrives;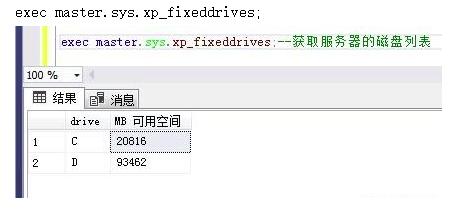
2.2获取数据库版本信息
exec master.sys.xp_msver;exec master.sys.xp_msver;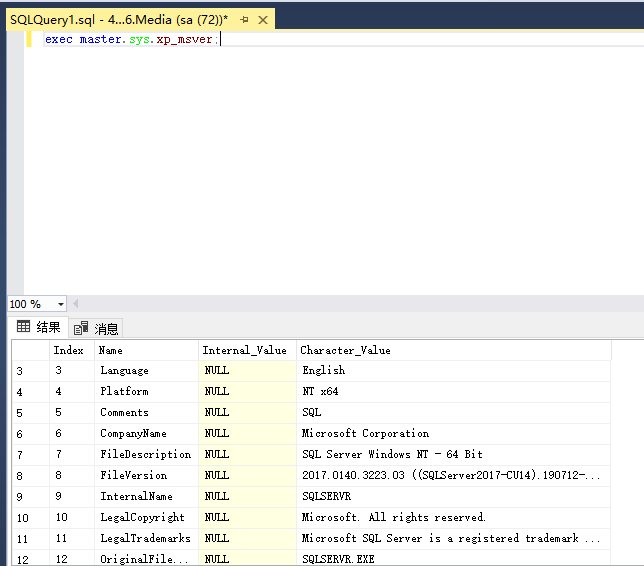
查看数据库版本信息
SELECT @@version
--
select SERVERPROPERTY(N'edition') as Edition --数据版本,如企业版、开发版等
,SERVERPROPERTY(N'collation') as Collation --数据库字符集
,SERVERPROPERTY(N'servername') as ServerName --服务名
,@@VERSION as Version --数据库版本号
,@@LANGUAGE AS Language --数据库使用的语言,如us_english等SELECT @@version
--
select SERVERPROPERTY(N'edition') as Edition --数据版本,如企业版、开发版等
,SERVERPROPERTY(N'collation') as Collation --数据库字符集
,SERVERPROPERTY(N'servername') as ServerName --服务名
,@@VERSION as Version --数据库版本号
,@@LANGUAGE AS Language --数据库使用的语言,如us_english等2.3获取sqlserver启动时间
SELECT sqlserver_start_time FROM sys.dm_os_sys_info;SELECT sqlserver_start_time FROM sys.dm_os_sys_info;三、基本操作
3.0查看所有数据库
Select Name FROM Master..SysDatabases orDER BY NameSelect Name FROM Master..SysDatabases orDER BY Name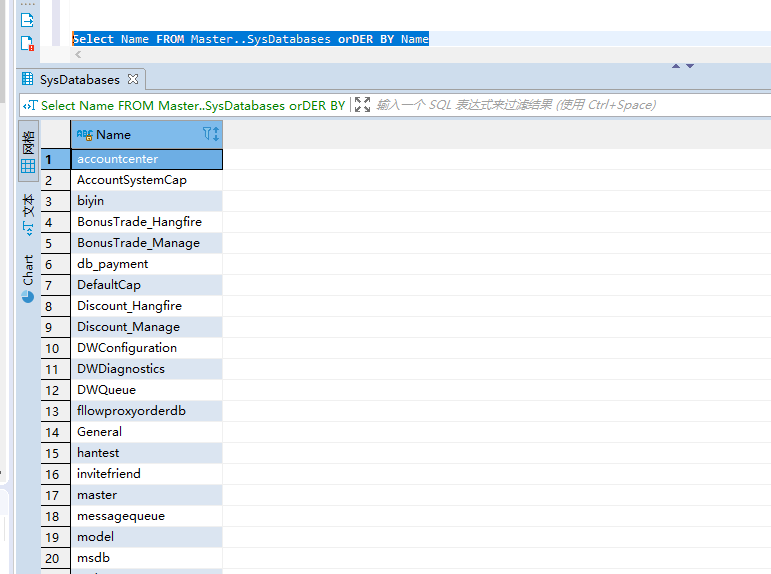
3.1创建数据库
#指定字符集,这个默认创建数据库类型为FULL
CREATE DATABASE TestData COLLATE Chinese_PRC_CI_AS
GO
#默认创建
CREATE DATABASE TestData
GO#指定字符集,这个默认创建数据库类型为FULL
CREATE DATABASE TestData COLLATE Chinese_PRC_CI_AS
GO
#默认创建
CREATE DATABASE TestData
GO- 指定数据库文件位置
use master;
go
create database E_Market
on primary
(
name="E_Market_data",
filename="/var/opt/mssql/data/E_Market_data.mdf",
size=5MB,
maxsize=100MB,
filegrowth=15%
)
log on
(
name="E_Market_log",
filename="/var/opt/mssql/data/E_Market_log.ldf",
size=5MB,
filegrowth=0
)
gouse master;
go
create database E_Market
on primary
(
name="E_Market_data",
filename="/var/opt/mssql/data/E_Market_data.mdf",
size=5MB,
maxsize=100MB,
filegrowth=15%
)
log on
(
name="E_Market_log",
filename="/var/opt/mssql/data/E_Market_log.ldf",
size=5MB,
filegrowth=0
)
go数据库重命名
USE master;
GO
EXEC sp_renamedb N'old_name', N'new_name';
GOUSE master;
GO
EXEC sp_renamedb N'old_name', N'new_name';
GO但是我们打开数据库默认存放路径,发现MDF和LDF的名称并没有改变,此时需要修改存储路径的名字
3.2查询
查看字符集
正确设置 SQL Server 排序规则
正确的设置 SQL Server 排序规则 ,保持 Instances、Databases、Columns 中 3 处排序规则一致,默认字符集是 Chinese_PRC_CI_AS 。
尽可能使用 nvarchar 等 Unicode 类型,而非 varchar 类型
#查询当前SQL Server服务器的排序规则
SELECT SERVERPROPERTY(N'Collation')
#指定数据库名字,DataName----》数据库名字
SELECT name,collation_name FROM sys.databases WHERE name = N'DataName';#查询当前SQL Server服务器的排序规则
SELECT SERVERPROPERTY(N'Collation')
#指定数据库名字,DataName----》数据库名字
SELECT name,collation_name FROM sys.databases WHERE name = N'DataName';#而表中的列(columns)默认情况是继承 Databases 的排序规则(除非在创建表时对列的排序规则进行指定),我们可通过目录视图 sys.columns 查询表中 columns 的排序规则信息
SELECT name, collation_name FROM sys.columns where collation_name is NOT NULLSELECT name, collation_name FROM sys.columns where collation_name is NOT NULL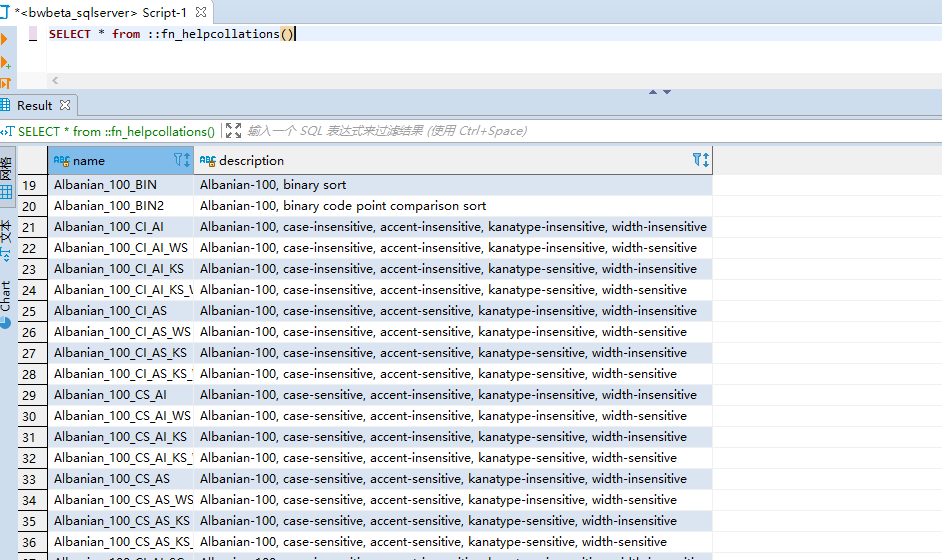
- 目录视图,查看字符集
而表中的列(columns)默认情况是继承 Databases 的排序规则(除非在创建表时对列的排序规则进行指定),我们可通过目录视图 sys.columns 查询表中 columns 的排序规则信息
SELECT name, collation_name FROM sys.columns where collation_name is NOT NULLSELECT name, collation_name FROM sys.columns where collation_name is NOT NULL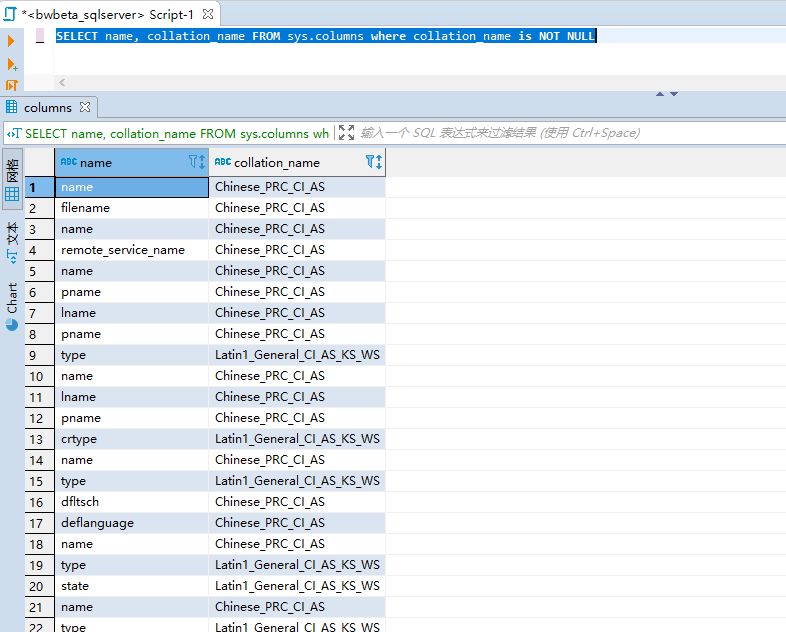
修改字符集
- 方式1
通过图形界面修改
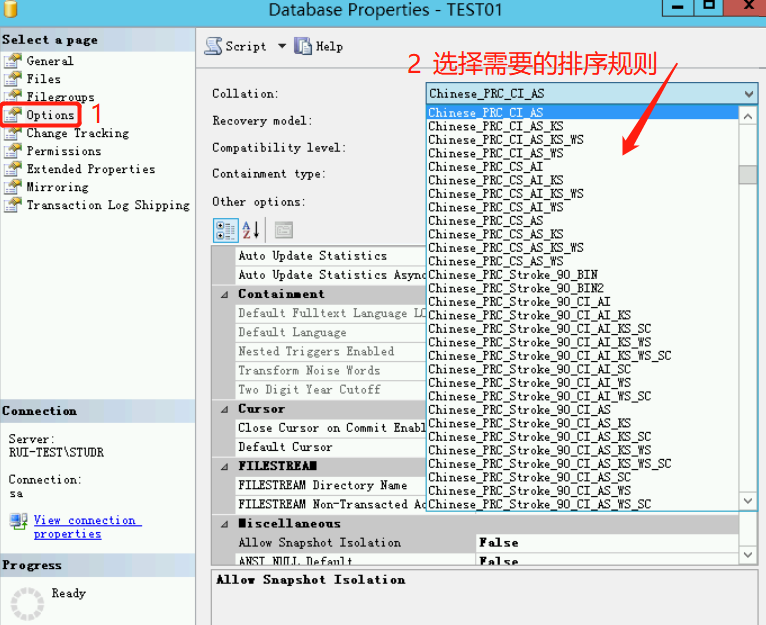
- 方式2
查看下
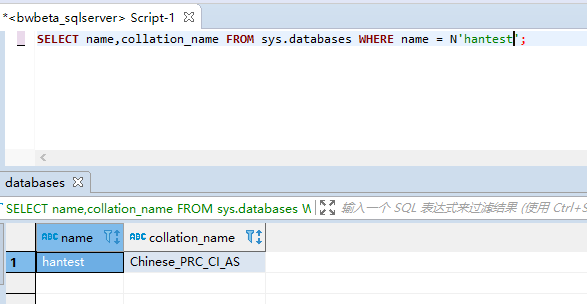
在查询分析器中,输入如下命令:
ALTER DATABASE hantest COLLATE Chinese_PRC_CI_ASALTER DATABASE hantest COLLATE Chinese_PRC_CI_AS--通过目录视图 sys.databases 查询 Databases 的排序规则
SELECT name,collation_name FROM sys.databases WHERE name = N'hantest'; //将hantest为数据库名--通过目录视图 sys.databases 查询 Databases 的排序规则
SELECT name,collation_name FROM sys.databases WHERE name = N'hantest'; //将hantest为数据库名
3.2 查看远程登陆人数
-- 查看远程登陆人
use master
SELECT login_name,Count(0) user_count
FROM Sys.dm_exec_requests dr WITH(nolock)
RIGHT OUTER JOIN Sys.dm_exec_sessions ds WITH(nolock)
ON dr.session_id = ds.session_id
RIGHT OUTER JOIN Sys.dm_exec_connections dc WITH(nolock)
ON ds.session_id = dc.session_id
WHERE ds.session_id > 50
GROUP BY login_name
ORDER BY user_count DESC
#或者
use master
select loginame,count(0) from sysprocesses
group by loginame
order by count(0) desc-- 查看远程登陆人
use master
SELECT login_name,Count(0) user_count
FROM Sys.dm_exec_requests dr WITH(nolock)
RIGHT OUTER JOIN Sys.dm_exec_sessions ds WITH(nolock)
ON dr.session_id = ds.session_id
RIGHT OUTER JOIN Sys.dm_exec_connections dc WITH(nolock)
ON ds.session_id = dc.session_id
WHERE ds.session_id > 50
GROUP BY login_name
ORDER BY user_count DESC
#或者
use master
select loginame,count(0) from sysprocesses
group by loginame
order by count(0) desc查看远程连接用户主机名
select hostname,count(0) from sysprocesses where loginame='sa'
group by hostname
order by count(0) descselect hostname,count(0) from sysprocesses where loginame='sa'
group by hostname
order by count(0) desc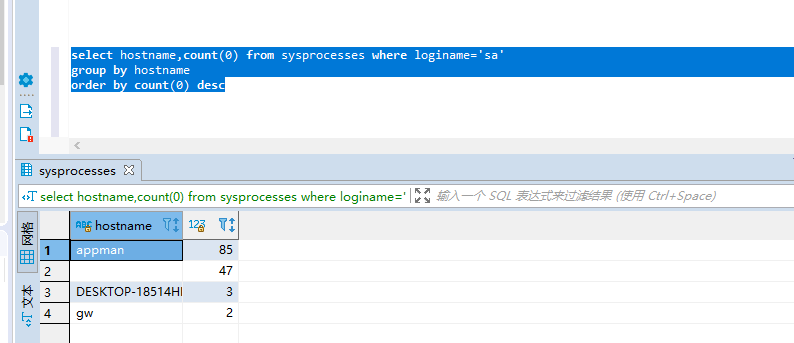
3.2 查看用户登陆日志
SELECT (sd.Name)'数据库',sp.* FROM
[Master].[dbo].[SYSPROCESSES] sp,[Master].[dbo].[SYSDATABASES] sd where sd.Name = 'DB_Name'
order by login_time descSELECT (sd.Name)'数据库',sp.* FROM
[Master].[dbo].[SYSPROCESSES] sp,[Master].[dbo].[SYSDATABASES] sd where sd.Name = 'DB_Name'
order by login_time desc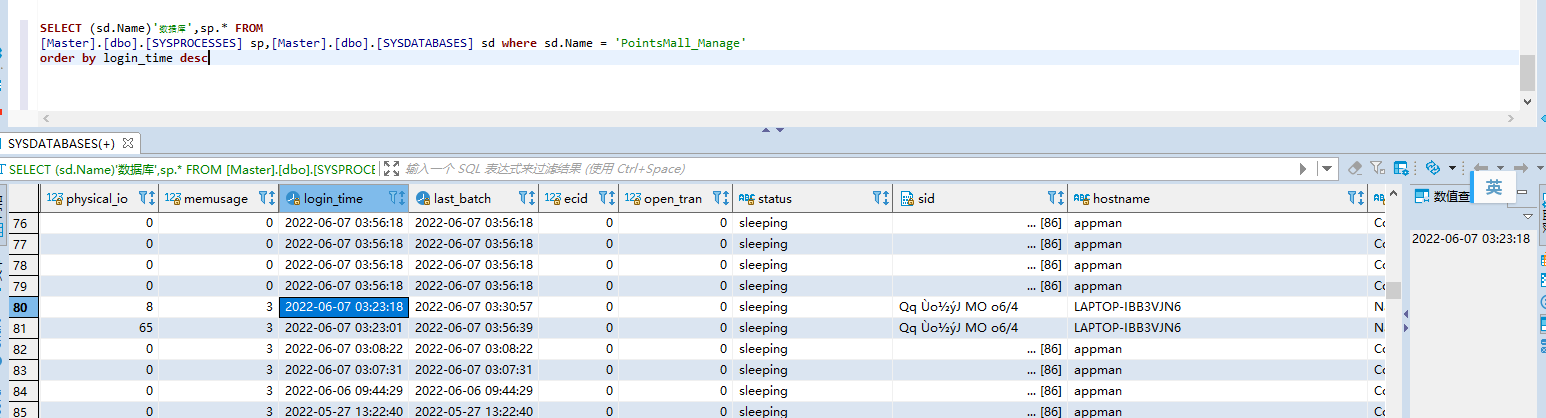
3.3查看死锁
- 用扩展时间抓取过去的死锁信息
DECLARE @SessionName SysName
SELECT @SessionName = 'system_health'
IF OBJECT_ID('tempdb..#Events') IS NOT NULL BEGIN
DROP TABLE #Events
END
DECLARE @Target_File NVarChar(1000)
, @Target_Dir NVarChar(1000)
, @Target_File_WildCard NVarChar(1000)
SELECT @Target_File = CAST(t.target_data as XML).value('EventFileTarget[1]/File[1]/@name', 'NVARCHAR(256)')
FROM sys.dm_xe_session_targets t
INNER JOIN sys.dm_xe_sessions s ON s.address = t.event_session_address
WHERE s.name = @SessionName
AND t.target_name = 'event_file'
SELECT @Target_Dir = LEFT(@Target_File, Len(@Target_File) - CHARINDEX('\', REVERSE(@Target_File)))
SELECT @Target_File_WildCard = @Target_Dir + '\' + @SessionName + '_*.xel'
--Keep this as a separate table because it's called twice in the next query. You don't want this running twice.
SELECT DeadlockGraph = CAST(event_data AS XML)
, DeadlockID = Row_Number() OVER(ORDER BY file_name, file_offset)
INTO #Events
FROM sys.fn_xe_file_target_read_file(@Target_File_WildCard, null, null, null) AS F
WHERE event_data like '<event name="xml_deadlock_report%'
;WITH Victims AS
(
SELECT VictimID = Deadlock.Victims.value('@id', 'varchar(50)')
, e.DeadlockID
FROM #Events e
CROSS APPLY e.DeadlockGraph.nodes('/event/data/value/deadlock/victim-list/victimProcess') as Deadlock(Victims)
)
, DeadlockObjects AS
(
SELECT DISTINCT e.DeadlockID
, ObjectName = Deadlock.Resources.value('@objectname', 'nvarchar(256)')
FROM #Events e
CROSS APPLY e.DeadlockGraph.nodes('/event/data/value/deadlock/resource-list/*') as Deadlock(Resources)
)
SELECT *
FROM
(
SELECT e.DeadlockID
, TransactionTime = Deadlock.Process.value('@lasttranstarted', 'datetime')
, DeadlockGraph
, DeadlockObjects = substring((SELECT (', ' + o.ObjectName)
FROM DeadlockObjects o
WHERE o.DeadlockID = e.DeadlockID
ORDER BY o.ObjectName
FOR XML PATH ('')
), 3, 4000)
, Victim = CASE WHEN v.VictimID IS NOT NULL
THEN 1
ELSE 0
END
, SPID = Deadlock.Process.value('@spid', 'int')
, ProcedureName = Deadlock.Process.value('executionStack[1]/frame[1]/@procname[1]', 'varchar(200)')
, LockMode = Deadlock.Process.value('@lockMode', 'char(1)')
, Code = Deadlock.Process.value('executionStack[1]/frame[1]', 'varchar(1000)')
, ClientApp = CASE LEFT(Deadlock.Process.value('@clientapp', 'varchar(100)'), 29)
WHEN 'SQLAgent - TSQL JobStep (Job '
THEN 'SQLAgent Job: ' + (SELECT name FROM msdb..sysjobs sj WHERE substring(Deadlock.Process.value('@clientapp', 'varchar(100)'),32,32)=(substring(sys.fn_varbintohexstr(sj.job_id),3,100))) + ' - ' + SUBSTRING(Deadlock.Process.value('@clientapp', 'varchar(100)'), 67, len(Deadlock.Process.value('@clientapp', 'varchar(100)'))-67)
ELSE Deadlock.Process.value('@clientapp', 'varchar(100)')
END
, HostName = Deadlock.Process.value('@hostname', 'varchar(20)')
, LoginName = Deadlock.Process.value('@loginname', 'varchar(20)')
, InputBuffer = Deadlock.Process.value('inputbuf[1]', 'varchar(1000)')
FROM #Events e
CROSS APPLY e.DeadlockGraph.nodes('/event/data/value/deadlock/process-list/process') as Deadlock(Process)
LEFT JOIN Victims v ON v.DeadlockID = e.DeadlockID AND v.VictimID = Deadlock.Process.value('@id', 'varchar(50)')
) X
ORDER BY DeadlockID DESCDECLARE @SessionName SysName
SELECT @SessionName = 'system_health'
IF OBJECT_ID('tempdb..#Events') IS NOT NULL BEGIN
DROP TABLE #Events
END
DECLARE @Target_File NVarChar(1000)
, @Target_Dir NVarChar(1000)
, @Target_File_WildCard NVarChar(1000)
SELECT @Target_File = CAST(t.target_data as XML).value('EventFileTarget[1]/File[1]/@name', 'NVARCHAR(256)')
FROM sys.dm_xe_session_targets t
INNER JOIN sys.dm_xe_sessions s ON s.address = t.event_session_address
WHERE s.name = @SessionName
AND t.target_name = 'event_file'
SELECT @Target_Dir = LEFT(@Target_File, Len(@Target_File) - CHARINDEX('\', REVERSE(@Target_File)))
SELECT @Target_File_WildCard = @Target_Dir + '\' + @SessionName + '_*.xel'
--Keep this as a separate table because it's called twice in the next query. You don't want this running twice.
SELECT DeadlockGraph = CAST(event_data AS XML)
, DeadlockID = Row_Number() OVER(ORDER BY file_name, file_offset)
INTO #Events
FROM sys.fn_xe_file_target_read_file(@Target_File_WildCard, null, null, null) AS F
WHERE event_data like '<event name="xml_deadlock_report%'
;WITH Victims AS
(
SELECT VictimID = Deadlock.Victims.value('@id', 'varchar(50)')
, e.DeadlockID
FROM #Events e
CROSS APPLY e.DeadlockGraph.nodes('/event/data/value/deadlock/victim-list/victimProcess') as Deadlock(Victims)
)
, DeadlockObjects AS
(
SELECT DISTINCT e.DeadlockID
, ObjectName = Deadlock.Resources.value('@objectname', 'nvarchar(256)')
FROM #Events e
CROSS APPLY e.DeadlockGraph.nodes('/event/data/value/deadlock/resource-list/*') as Deadlock(Resources)
)
SELECT *
FROM
(
SELECT e.DeadlockID
, TransactionTime = Deadlock.Process.value('@lasttranstarted', 'datetime')
, DeadlockGraph
, DeadlockObjects = substring((SELECT (', ' + o.ObjectName)
FROM DeadlockObjects o
WHERE o.DeadlockID = e.DeadlockID
ORDER BY o.ObjectName
FOR XML PATH ('')
), 3, 4000)
, Victim = CASE WHEN v.VictimID IS NOT NULL
THEN 1
ELSE 0
END
, SPID = Deadlock.Process.value('@spid', 'int')
, ProcedureName = Deadlock.Process.value('executionStack[1]/frame[1]/@procname[1]', 'varchar(200)')
, LockMode = Deadlock.Process.value('@lockMode', 'char(1)')
, Code = Deadlock.Process.value('executionStack[1]/frame[1]', 'varchar(1000)')
, ClientApp = CASE LEFT(Deadlock.Process.value('@clientapp', 'varchar(100)'), 29)
WHEN 'SQLAgent - TSQL JobStep (Job '
THEN 'SQLAgent Job: ' + (SELECT name FROM msdb..sysjobs sj WHERE substring(Deadlock.Process.value('@clientapp', 'varchar(100)'),32,32)=(substring(sys.fn_varbintohexstr(sj.job_id),3,100))) + ' - ' + SUBSTRING(Deadlock.Process.value('@clientapp', 'varchar(100)'), 67, len(Deadlock.Process.value('@clientapp', 'varchar(100)'))-67)
ELSE Deadlock.Process.value('@clientapp', 'varchar(100)')
END
, HostName = Deadlock.Process.value('@hostname', 'varchar(20)')
, LoginName = Deadlock.Process.value('@loginname', 'varchar(20)')
, InputBuffer = Deadlock.Process.value('inputbuf[1]', 'varchar(1000)')
FROM #Events e
CROSS APPLY e.DeadlockGraph.nodes('/event/data/value/deadlock/process-list/process') as Deadlock(Process)
LEFT JOIN Victims v ON v.DeadlockID = e.DeadlockID AND v.VictimID = Deadlock.Process.value('@id', 'varchar(50)')
) X
ORDER BY DeadlockID DESCSELECT request_session_id spid, OBJECT_NAME(resource_associated_entity_id) tableName FROM sys.dm_tran_locks WHERE resource_type = 'OBJECT 'SELECT request_session_id spid, OBJECT_NAME(resource_associated_entity_id) tableName FROM sys.dm_tran_locks WHERE resource_type = 'OBJECT '- 或者
--查看被锁表:
SELECT
request_session_id spid,
OBJECT_NAME(
resource_associated_entity_id
) tableName
FROM
sys.dm_tran_locks
WHERE
resource_type = 'OBJECT'
ORDER BY request_session_id ASC
--spid 锁表进程
--tableName 被锁表名
--根据锁表进程查询相应进程互锁的SQL语句
DBCC INPUTBUFFER (spid)--查看被锁表:
SELECT
request_session_id spid,
OBJECT_NAME(
resource_associated_entity_id
) tableName
FROM
sys.dm_tran_locks
WHERE
resource_type = 'OBJECT'
ORDER BY request_session_id ASC
--spid 锁表进程
--tableName 被锁表名
--根据锁表进程查询相应进程互锁的SQL语句
DBCC INPUTBUFFER (spid)- 或者
select * from master.sys.sysprocesses where dbid=db_id('db_name')
-- kill
KILL spidselect * from master.sys.sysprocesses where dbid=db_id('db_name')
-- kill
KILL spid
解锁语句
-- 解锁:
DECLARE
@spid INT
SET @spid = 52--锁表进程
DECLARE
@SQL VARCHAR (1000)
SET @SQL = 'kill ' + CAST (@spid AS VARCHAR) EXEC (@SQL)-- 解锁:
DECLARE
@spid INT
SET @spid = 52--锁表进程
DECLARE
@SQL VARCHAR (1000)
SET @SQL = 'kill ' + CAST (@spid AS VARCHAR) EXEC (@SQL)生成解锁SQL语句
--生成解锁SQL
SELECT
DISTINCT 'DECLARE @spid INT SET @spid = ',request_session_id,' DECLARE @SQL VARCHAR (1000) SET @SQL = ''kill '' + CAST (@spid AS VARCHAR) EXEC (@SQL);' as s
FROM
sys.dm_tran_locks
WHERE
resource_type = 'OBJECT' --spid 锁表进程
--tableName 被锁表名--生成解锁SQL
SELECT
DISTINCT 'DECLARE @spid INT SET @spid = ',request_session_id,' DECLARE @SQL VARCHAR (1000) SET @SQL = ''kill '' + CAST (@spid AS VARCHAR) EXEC (@SQL);' as s
FROM
sys.dm_tran_locks
WHERE
resource_type = 'OBJECT' --spid 锁表进程
--tableName 被锁表名死锁trace Log
SQL Server 跟死锁相关的Trace Flag是 1204 和 1222,两个Trace Flag的Scope都是global only,两者记录的信息基本相同,都会把造成死锁的两个事务、抢占的资源、死锁类型和命令记录下来。前者是以文本格式记录,后者是以XML格式记录的,可以同时打开这两个追踪标志,记录的数据都存储在错误日志(Error Log)中
微软的官方文档对这两个Trace Falg的定义是:
- 1204:Returns the resources and types of locks participating in a deadlock and also the current command affected.
- 1222:Returns the resources and types of locks that are participating in a deadlock and also the current command affected, in an XML format that does not comply with any XSD schema
跟踪标志
| 标志 | 描述 |
|---|---|
| 3604 | 直接返回信息到 当前客户端;而不是 打印信息 到 错误日志文件 |
| 2588 | 显示隐藏的DBCC命令、以及提供帮助信息 |
| -1 | 用作 traceon的最后一个参数。表示服务器范围有效;否则仅仅当前会话有效 |
| 1204 | 返回参与死锁的锁的资源和类型,以及受影响的当前命令 |
| 1222 | 返回参与死锁的锁的资源和类型,以及使用了不符合任何XSD架构的XML格式的受影响的当前命令(比1204更进一步,2005及以上版本可以使用) |
| 3605 | 将DBCC的结果输出到错误日志 |
打开追踪标志
- 查看状态
DBCC TRACESTATUS(1204,1222, -1)
-- Status为0,表示当前这两个Trace Flag都处于OFF状态
-1 代表全局开启DBCC TRACESTATUS(1204,1222, -1)
-- Status为0,表示当前这两个Trace Flag都处于OFF状态
-1 代表全局开启- 开启
DBCC TRACEON(1204,1222, -1)
-- Status为1,表示当前这两个Trace Flag都处于ON状态
-- 一旦系统检测到死锁,就会把死锁发生时的消息都记录到错误日志中DBCC TRACEON(1204,1222, -1)
-- Status为1,表示当前这两个Trace Flag都处于ON状态
-- 一旦系统检测到死锁,就会把死锁发生时的消息都记录到错误日志中- 关闭
DBCC TRACEOFF(1204,1222, -1)DBCC TRACEOFF(1204,1222, -1)3.4查看表行数
-- 查看表名及行数
use invitefriend
SELECT a.name, b.rows FROM sysobjects AS a INNER JOIN sysindexes AS b ON a.id = b.id WHERE (a.type = 'u') AND (b.indid IN (0, 1)) ORDER BY a.name,b.rows DESC-- 查看表名及行数
use invitefriend
SELECT a.name, b.rows FROM sysobjects AS a INNER JOIN sysindexes AS b ON a.id = b.id WHERE (a.type = 'u') AND (b.indid IN (0, 1)) ORDER BY a.name,b.rows DESC
3.5查看某库中所有表
Select Name FROM db_payment..SysObjects Where XType='U' orDER BY NameSelect Name FROM db_payment..SysObjects Where XType='U' orDER BY NameXType=‘U’ :表示所有用户表; XType=‘S’ :表示所有系统表;
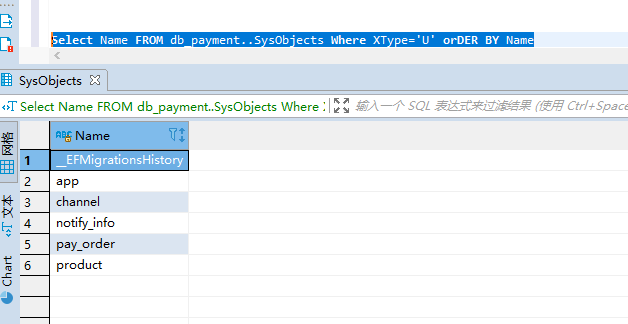
获取数据所有类型
use hantest
select name from systypesuse hantest
select name from systypes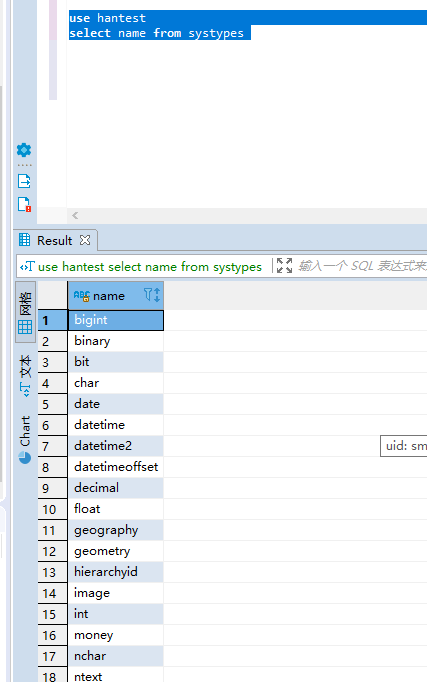
3.6表操作
创建表
use dataName
CREATE TABLE DEPT
(DEPTNO int primary key,
DNAME VARCHAR(14),
LOC VARCHAR(13) );use dataName
CREATE TABLE DEPT
(DEPTNO int primary key,
DNAME VARCHAR(14),
LOC VARCHAR(13) );插入数据
use dataName
INSERT INTO DEPT VALUES (101, 'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT VALUES (201, 'RESEARCH', 'DALLAS');
INSERT INTO DEPT VALUES (301, 'SALES', 'CHICAGO');
INSERT INTO DEPT VALUES (401, 'OPERATIONS', 'BOSTON');use dataName
INSERT INTO DEPT VALUES (101, 'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT VALUES (201, 'RESEARCH', 'DALLAS');
INSERT INTO DEPT VALUES (301, 'SALES', 'CHICAGO');
INSERT INTO DEPT VALUES (401, 'OPERATIONS', 'BOSTON');- 或者
use hantest
CREATE TABLE SALES
(
CUSTOMER_ID INT NOT NULL ,
ITEM_ID INT NOT NULL ,
SALE_QUANTITY SMALLINT NOT NULL ,
SALE_DATE DATE NOT NULL
);
-- insert
INSERT INTO SALES
SELECT RAND(CAST( NEWID() AS varbinary )) * 900 + 1 AS CUSTOMER_ID
, RAND(CAST( NEWID() AS varbinary )) * 500 + 1 AS ITEM_ID
, RAND(CAST( NEWID() AS varbinary )) * 10 + 1 AS SALE_QUANTITY
, DATEADD(D, RAND(CAST( NEWID() AS varbinary )) * 100, '2000/1/1') AS SALE_DATE
FROM sys.columns
go 10use hantest
CREATE TABLE SALES
(
CUSTOMER_ID INT NOT NULL ,
ITEM_ID INT NOT NULL ,
SALE_QUANTITY SMALLINT NOT NULL ,
SALE_DATE DATE NOT NULL
);
-- insert
INSERT INTO SALES
SELECT RAND(CAST( NEWID() AS varbinary )) * 900 + 1 AS CUSTOMER_ID
, RAND(CAST( NEWID() AS varbinary )) * 500 + 1 AS ITEM_ID
, RAND(CAST( NEWID() AS varbinary )) * 10 + 1 AS SALE_QUANTITY
, DATEADD(D, RAND(CAST( NEWID() AS varbinary )) * 100, '2000/1/1') AS SALE_DATE
FROM sys.columns
go 10查询当前数据库下所有用户表
select * from sysobjects where xtype='u' order by name
-- 或者
select * from sys.tablesselect * from sysobjects where xtype='u' order by name
-- 或者
select * from sys.tableshttps://www.xin3721.com/Articletsql/sql28477.html
查看表结构
use db_name
sp_help table_name;
-- 查看列
sp_columns table_nameuse db_name
sp_help table_name;
-- 查看列
sp_columns table_name- 或者
SELECT 表名 = CASE WHEN a.colorder = 1 THEN d.name ELSE '' END ,
字段说明 = ISNULL(g.[value], '') ,
字段名 = a.name ,
类型 = CASE WHEN b.name IN ( 'varchar', 'nvarchar' )
THEN b.name + '('
+ CAST(COLUMNPROPERTY(a.id, a.name, 'PRECISION') AS VARCHAR(4))
+ ')'
WHEN b.name = 'decimal'
THEN b.name + '('
+ CAST(COLUMNPROPERTY(a.id, a.name, 'PRECISION') AS VARCHAR(4))
+ ','
+ CAST(COLUMNPROPERTY(a.id, a.name, 'Scale') AS VARCHAR(4))
+ ')'
ELSE b.name
END
FROM syscolumns a -- 列名
LEFT JOIN systypes b ON a.xusertype = b.xusertype -- 类型
INNER JOIN sysobjects d ON a.id = d.id AND d.xtype = 'U' AND d.name <> 'dtproperties' --筛选用户对象
--LEFT JOIN syscomments e ON a.cdefault = e.id --默认值
LEFT JOIN sys.extended_properties g ON a.id = g.major_id AND a.colid = g.minor_id --扩展属性(字段说明)
--LEFT JOIN sys.extended_properties f ON d.id = f.major_id AND f.minor_id = 0 --扩展属性(表说明)
WHERE d.name = 'table_name' --可修改表名
ORDER BY a.id , a.colorderSELECT 表名 = CASE WHEN a.colorder = 1 THEN d.name ELSE '' END ,
字段说明 = ISNULL(g.[value], '') ,
字段名 = a.name ,
类型 = CASE WHEN b.name IN ( 'varchar', 'nvarchar' )
THEN b.name + '('
+ CAST(COLUMNPROPERTY(a.id, a.name, 'PRECISION') AS VARCHAR(4))
+ ')'
WHEN b.name = 'decimal'
THEN b.name + '('
+ CAST(COLUMNPROPERTY(a.id, a.name, 'PRECISION') AS VARCHAR(4))
+ ','
+ CAST(COLUMNPROPERTY(a.id, a.name, 'Scale') AS VARCHAR(4))
+ ')'
ELSE b.name
END
FROM syscolumns a -- 列名
LEFT JOIN systypes b ON a.xusertype = b.xusertype -- 类型
INNER JOIN sysobjects d ON a.id = d.id AND d.xtype = 'U' AND d.name <> 'dtproperties' --筛选用户对象
--LEFT JOIN syscomments e ON a.cdefault = e.id --默认值
LEFT JOIN sys.extended_properties g ON a.id = g.major_id AND a.colid = g.minor_id --扩展属性(字段说明)
--LEFT JOIN sys.extended_properties f ON d.id = f.major_id AND f.minor_id = 0 --扩展属性(表说明)
WHERE d.name = 'table_name' --可修改表名
ORDER BY a.id , a.colorder
复制表结构
use dbname
select top 1 * Into newTable From sourceTableuse dbname
select top 1 * Into newTable From sourceTable查询数据插入到临时表
-- 把 test_table 的 100 条数据放到临时表 tmp_table 里
select top 100 * into #tmp_table from test_table;-- 把 test_table 的 100 条数据放到临时表 tmp_table 里
select top 100 * into #tmp_table from test_table;插入到一个不存在的表
-- 把 表 test_table 的数据放到一个现创的 new_table 里
select * into new_table from test_table ;-- 把 表 test_table 的数据放到一个现创的 new_table 里
select * into new_table from test_table ;插入到一个已经存在的数据表
-- 把 test_01 的数据都放到 test_02 表里
insert into test_02
select * from test_01 ;-- 把 test_01 的数据都放到 test_02 表里
insert into test_02
select * from test_01 ;修改表名字
--修改表名
EXEC sp_rename '旧表名', '新表名'
-- 修改列名
EXEC sp_rename '表名.[旧列名]','新列名','COLUMN'--修改表名
EXEC sp_rename '旧表名', '新表名'
-- 修改列名
EXEC sp_rename '表名.[旧列名]','新列名','COLUMN'3.7删除表
批量删除
1、delete操作会被完整记录到日志里,它需要大量空间和时间
2、如果删除中间发生中断,一切删除会回滚(在一个事务里)
3、同时删除多行,记录上的锁也许会被提升为排它表锁,从而阻碍操作完成之前有对这个表的操作(有时候会妨碍正常的业务)所以一般采取分批删除的方法
所以,通过分批次地删除数据可以大大提升删除效率,缩短删除时间:
declare @perCount int;
set @perCount = 6000;
while 1=1
begin
delete top(@perCount) from 表 where CrtDate < '2020-12-23';
if(@@rowcount<@perCount) break;
enddeclare @perCount int;
set @perCount = 6000;
while 1=1
begin
delete top(@perCount) from 表 where CrtDate < '2020-12-23';
if(@@rowcount<@perCount) break;
enddelete、truncate、drop区别
应用范围:truncate只能对table,delete可以是table和view
drop
*删除内容和定义,释放空间。*简单来说就是把整个表去掉.以后要新增数据是不可能的,除非新增一个表,
例如:一个班就是一个表,学生就是表中的数据,学生的职务就是定义
drop table class,就是把整个班移除.学生和职务都消失
truncate
绝招:删除内容、释放空间但不删除定义。与drop不同的是,他只是清空表数据而已,他比较温柔.并且能针对具有自动递增值的字段,做计数重置归零重新计算的作用
同样也是一个班,他只去除所有的学生.班还在,职务还在,如果有新增的学生可以进去,也可以分配上职务
删除内容很容易理解,不删除定义也很容易理解,就是保留表的数据结构
==delete过行数据,所以会出现标识列不连续(体现了delete删除是不释放空间的)==
==truncate删除是释放空间==
1、truncate 在各种表上无论是大的还是小的都非常快。如果有ROLLBACK命令Delete将被撤销,而 truncate 则不会被撤销。 2、truncate 是一个DDL语言,向其他所有的DDL语言一样,他将被隐式提交,不能对 truncate 使用ROLLBACK命令。 3、truncate 将重新设置高水平线和所有的索引。在对整个表和索引进行完全浏览时,经过 truncate 操作后的表比Delete操作后的表要快得多。 4、truncate 不能触发任何Delete触发器。 5、当表被清空后表和表的索引讲重新设置成初始大小,而delete则不能。 6、不能清空父表
delete
https://learn.microsoft.com/zh-cn/sql/t-sql/statements/delete-transact-sql?view=sql-server-2017
删除内容不删除定义
truncate 比 delete速度快,且使用的系统和事务日志资源少。
delete 语句每次删除一行,并在事务日志中为所删除的每行记录一项。所以可以对delete操作进行roll back
- 语法
-- Syntax for SQL Server and Azure SQL Database
[ WITH <common_table_expression> [ ,...n ] ]
DELETE
[ TOP ( expression ) [ PERCENT ] ]
[ FROM ]
{ { table_alias
| <object>
| rowset_function_limited
[ WITH ( table_hint_limited [ ...n ] ) ] }
| @table_variable
}
[ <OUTPUT Clause> ]
[ FROM table_source [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <Query Hint> [ ,...n ] ) ]
[; ]
<object> ::=
{
[ server_name.database_name.schema_name.
| database_name. [ schema_name ] .
| schema_name.
]
table_or_view_name
}-- Syntax for SQL Server and Azure SQL Database
[ WITH <common_table_expression> [ ,...n ] ]
DELETE
[ TOP ( expression ) [ PERCENT ] ]
[ FROM ]
{ { table_alias
| <object>
| rowset_function_limited
[ WITH ( table_hint_limited [ ...n ] ) ] }
| @table_variable
}
[ <OUTPUT Clause> ]
[ FROM table_source [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <Query Hint> [ ,...n ] ) ]
[; ]
<object> ::=
{
[ server_name.database_name.schema_name.
| database_name. [ schema_name ] .
| schema_name.
]
table_or_view_name
}删除表中所有数据
语法:delete from 数据库名.dbo.表名;
示例:delete from testss.dbo.test1;语法:delete from 数据库名.dbo.表名;
示例:delete from testss.dbo.test1;删除单表中重复数据
语法:delete a from 表 as a left join 表 as b on a.列=b.列 where a.列>b.列;
示例:delete a from test1 as a left join test1 as b on a.name=b.name where a.id>b.id;语法:delete a from 表 as a left join 表 as b on a.列=b.列 where a.列>b.列;
示例:delete a from test1 as a left join test1 as b on a.name=b.name where a.id>b.id;删除单表多行数据
语法:delete from 数据库名.dbo.表名 where 条件或者delete top(n) from 数据库名.dbo.表名 where 条件;
示例:
delete from testss.dbo.test1 where id>='14' and id<='15';
delete from testss.dbo.test1 where id between '16' and '17';
delete from testss.dbo.test1 where id in ('18','19');
delete top(2) from testss.dbo.test1 where id>='20';语法:delete from 数据库名.dbo.表名 where 条件或者delete top(n) from 数据库名.dbo.表名 where 条件;
示例:
delete from testss.dbo.test1 where id>='14' and id<='15';
delete from testss.dbo.test1 where id between '16' and '17';
delete from testss.dbo.test1 where id in ('18','19');
delete top(2) from testss.dbo.test1 where id>='20';删除单表单行数据
语法:delete from 数据库名.dbo.表名 where 条件;
示例:delete from testss.dbo.test1 where id='12';语法:delete from 数据库名.dbo.表名 where 条件;
示例:delete from testss.dbo.test1 where id='12';表保留10天数据
delete from 表名 where datediff(day,cast(SUBSTRING([TIME], 1, 8) as datetime),getdate()) > 10delete from 表名 where datediff(day,cast(SUBSTRING([TIME], 1, 8) as datetime),getdate()) > 10查看被删除的数据
select ID,New_ID,(New_ID - ID -1) as '存在的间隔数量',ID+1 as '被删除的行ID'
from
(
select ID,New_ID=(
select min(b.ID) id
from dept b
where b.id > a.id
)
from dept a
) c
where ID+1 <> New_IDselect ID,New_ID,(New_ID - ID -1) as '存在的间隔数量',ID+1 as '被删除的行ID'
from
(
select ID,New_ID=(
select min(b.ID) id
from dept b
where b.id > a.id
)
from dept a
) c
where ID+1 <> New_ID4.删除sqlserver系统日志
#不用重启实例
exec sp_cycle_errorlog#不用重启实例
exec sp_cycle_errorloghttps://www.xin3721.com/Articletsql/list198.html
5.索引
5.1查看索引
use db_name
exec sp_helpindex 'table_name'use db_name
exec sp_helpindex 'table_name'
index_name:指定索引名称.
index_description:包含索引的描述信息,例如唯一性索引,聚集索引等。
index_keys:包含了索引所在表中的列.
- 或者利用系统表
SELECT
TableId=O.[object_id],
TableName=O.Name,
IndexId=ISNULL(KC.[object_id],IDX.index_id),
IndexName=IDX.Name,
IndexType=ISNULL(KC.type_desc,'Index'),
Index_Column_id=IDXC.index_column_id,
ColumnID=C.Column_id,
ColumnName=C.Name,
Sort=CASE INDEXKEY_PROPERTY(IDXC.[object_id],IDXC.index_id,IDXC.index_column_id,'IsDescending')
WHEN 1 THEN 'DESC' WHEN 0 THEN 'ASC' ELSE '' END,
PrimaryKey=CASE WHEN IDX.is_primary_key=1 THEN N'√'ELSE N'' END,
[UQIQUE]=CASE WHEN IDX.is_unique=1 THEN N'√'ELSE N'' END,
Ignore_dup_key=CASE WHEN IDX.ignore_dup_key=1 THEN N'√'ELSE N'' END,
Disabled=CASE WHEN IDX.is_disabled=1 THEN N'√'ELSE N'' END,
Fill_factor=IDX.fill_factor,
Padded=CASE WHEN IDX.is_padded=1 THEN N'√'ELSE N'' END
FROM sys.indexes IDX
INNER JOIN sys.index_columns IDXC
ON IDX.[object_id]=IDXC.[object_id]
AND IDX.index_id=IDXC.index_id
LEFT JOIN sys.key_constraints KC
ON IDX.[object_id]=KC.[parent_object_id]
AND IDX.index_id=KC.unique_index_id
INNER JOIN sys.objects O
ON O.[object_id]=IDX.[object_id]
INNER JOIN sys.columns C
ON O.[object_id]=C.[object_id]
AND O.type='U'
AND O.is_ms_shipped=0
AND IDXC.Column_id=C.Column_id where O.name='FundAccountMoney' --cz201是你要查询的表SELECT
TableId=O.[object_id],
TableName=O.Name,
IndexId=ISNULL(KC.[object_id],IDX.index_id),
IndexName=IDX.Name,
IndexType=ISNULL(KC.type_desc,'Index'),
Index_Column_id=IDXC.index_column_id,
ColumnID=C.Column_id,
ColumnName=C.Name,
Sort=CASE INDEXKEY_PROPERTY(IDXC.[object_id],IDXC.index_id,IDXC.index_column_id,'IsDescending')
WHEN 1 THEN 'DESC' WHEN 0 THEN 'ASC' ELSE '' END,
PrimaryKey=CASE WHEN IDX.is_primary_key=1 THEN N'√'ELSE N'' END,
[UQIQUE]=CASE WHEN IDX.is_unique=1 THEN N'√'ELSE N'' END,
Ignore_dup_key=CASE WHEN IDX.ignore_dup_key=1 THEN N'√'ELSE N'' END,
Disabled=CASE WHEN IDX.is_disabled=1 THEN N'√'ELSE N'' END,
Fill_factor=IDX.fill_factor,
Padded=CASE WHEN IDX.is_padded=1 THEN N'√'ELSE N'' END
FROM sys.indexes IDX
INNER JOIN sys.index_columns IDXC
ON IDX.[object_id]=IDXC.[object_id]
AND IDX.index_id=IDXC.index_id
LEFT JOIN sys.key_constraints KC
ON IDX.[object_id]=KC.[parent_object_id]
AND IDX.index_id=KC.unique_index_id
INNER JOIN sys.objects O
ON O.[object_id]=IDX.[object_id]
INNER JOIN sys.columns C
ON O.[object_id]=C.[object_id]
AND O.type='U'
AND O.is_ms_shipped=0
AND IDXC.Column_id=C.Column_id where O.name='FundAccountMoney' --cz201是你要查询的表
- 或者
SELECT CASE
WHEN t.[type] = 'U' THEN
'表'
WHEN t.[type] = 'V' THEN
'视图'
END AS '类型',
SCHEMA_NAME(t.schema_id) + '.' + t.[name] AS '(表/视图)名称',
i.[name] AS 索引名称,
SUBSTRING(column_names, 1, LEN(column_names) - 1) AS '列名',
CASE
WHEN i.[type] = 1 THEN
'聚集索引'
WHEN i.[type] = 2 THEN
'非聚集索引'
WHEN i.[type] = 3 THEN
'XML索引'
WHEN i.[type] = 4 THEN
'空间索引'
WHEN i.[type] = 5 THEN
'聚簇列存储索引'
WHEN i.[type] = 6 THEN
'非聚集列存储索引'
WHEN i.[type] = 7 THEN
'非聚集哈希索引'
END AS '索引类型',
CASE
WHEN i.is_unique = 1 THEN
'唯一'
ELSE
'不唯一'
END AS '索引是否唯一'
FROM sys.objects t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
CROSS APPLY
(
SELECT col.[name] + ', '
FROM sys.index_columns ic
INNER JOIN sys.columns col
ON ic.object_id = col.object_id
AND ic.column_id = col.column_id
WHERE ic.object_id = t.object_id
AND ic.index_id = i.index_id
ORDER BY col.column_id
FOR XML PATH('')
) D(column_names)
WHERE t.is_ms_shipped <> 1
AND index_id > 0
AND t.name='table_name' -- 修改表名字
ORDER BY i.[name];SELECT CASE
WHEN t.[type] = 'U' THEN
'表'
WHEN t.[type] = 'V' THEN
'视图'
END AS '类型',
SCHEMA_NAME(t.schema_id) + '.' + t.[name] AS '(表/视图)名称',
i.[name] AS 索引名称,
SUBSTRING(column_names, 1, LEN(column_names) - 1) AS '列名',
CASE
WHEN i.[type] = 1 THEN
'聚集索引'
WHEN i.[type] = 2 THEN
'非聚集索引'
WHEN i.[type] = 3 THEN
'XML索引'
WHEN i.[type] = 4 THEN
'空间索引'
WHEN i.[type] = 5 THEN
'聚簇列存储索引'
WHEN i.[type] = 6 THEN
'非聚集列存储索引'
WHEN i.[type] = 7 THEN
'非聚集哈希索引'
END AS '索引类型',
CASE
WHEN i.is_unique = 1 THEN
'唯一'
ELSE
'不唯一'
END AS '索引是否唯一'
FROM sys.objects t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
CROSS APPLY
(
SELECT col.[name] + ', '
FROM sys.index_columns ic
INNER JOIN sys.columns col
ON ic.object_id = col.object_id
AND ic.column_id = col.column_id
WHERE ic.object_id = t.object_id
AND ic.index_id = i.index_id
ORDER BY col.column_id
FOR XML PATH('')
) D(column_names)
WHERE t.is_ms_shipped <> 1
AND index_id > 0
AND t.name='table_name' -- 修改表名字
ORDER BY i.[name];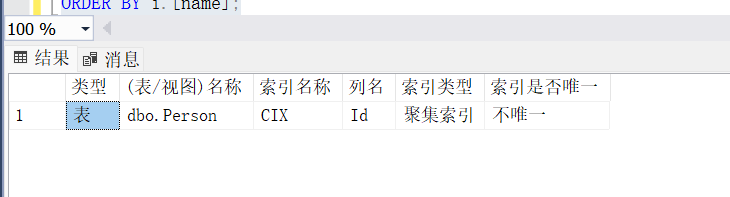
- 或者
SELECT OBJECT_SCHEMA_NAME(ind.object_id) AS SchemaName
, OBJECT_NAME(ind.object_id) AS ObjectName
, ind.name AS IndexName
, ind.is_primary_key AS IsPrimaryKey
, ind.is_unique AS IsUniqueIndex
, col.name AS ColumnName
, ic.is_included_column AS IsIncludedColumn
, ic.key_ordinal AS ColumnOrder
FROM sys.indexes ind
INNER JOIN sys.index_columns ic
ON ind.object_id = ic.object_id
AND ind.index_id = ic.index_id
INNER JOIN sys.columns col
ON ic.object_id = col.object_id
AND ic.column_id = col.column_id
INNER JOIN sys.tables t
ON ind.object_id = t.object_id
WHERE t.is_ms_shipped = 0
ORDER BY OBJECT_SCHEMA_NAME(ind.object_id) --SchemaName
, OBJECT_NAME(ind.object_id) --ObjectName
, ind.is_primary_key DESC
, ind.is_unique DESC
, ind.name --IndexName
, ic.key_ordinalSELECT OBJECT_SCHEMA_NAME(ind.object_id) AS SchemaName
, OBJECT_NAME(ind.object_id) AS ObjectName
, ind.name AS IndexName
, ind.is_primary_key AS IsPrimaryKey
, ind.is_unique AS IsUniqueIndex
, col.name AS ColumnName
, ic.is_included_column AS IsIncludedColumn
, ic.key_ordinal AS ColumnOrder
FROM sys.indexes ind
INNER JOIN sys.index_columns ic
ON ind.object_id = ic.object_id
AND ind.index_id = ic.index_id
INNER JOIN sys.columns col
ON ic.object_id = col.object_id
AND ic.column_id = col.column_id
INNER JOIN sys.tables t
ON ind.object_id = t.object_id
WHERE t.is_ms_shipped = 0
ORDER BY OBJECT_SCHEMA_NAME(ind.object_id) --SchemaName
, OBJECT_NAME(ind.object_id) --ObjectName
, ind.is_primary_key DESC
, ind.is_unique DESC
, ind.name --IndexName
, ic.key_ordinal
5.2创建
5.3修改
5.4删除
drop index 索引名称 on 表名drop index 索引名称 on 表名5.5优先级
SQL Server查询数据三种方式Table Scan/Index Seek/Index Scan
Table Scan:全表扫描,没有用到索引;
Index Seek:索引查找,有用到索引,根据聚集索引和非聚集索引分为Clustered Index Seek和NonClustered Index Seek;
Index Scan:索引扫描,有用到索引,效率比Table Scan高,但低于Index Seek。也分为Clustered Index Scan和
NonClustered Index Scan;
显然,Index Seek查询效率最高,我们应该在查询中尽量用Index Seek,那什么时候会用到Index Seek呢?我们再看两个查询的执行计划: ·索引全部字段包含在where子句中; ·复合索引部分字段包含在where子句中且是索引前几个字段
优先级Clustered Index Seek>NonClustered Index Seek>NonClustered Index Scan>Clustered Index Scan>Table Scan
SqlServer中Index Seek的匹配规则(一) https://www.cnblogs.com/OpenCoder/p/5804794.htmlhttps://www.cnblogs.com/OpenCoder/category/774800.html
四、sql 执行计划
4.1 执行时间最长 sql
SELECT TOP 10 qp.query_plan,qt.text,total_worker_time
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp[@LogicalOp="Index Scan"
or @LogicalOp="Clustered Index Scan"
or @LogicalOp="Table Scan"]')=1
order by total_worker_time DESCSELECT TOP 10 qp.query_plan,qt.text,total_worker_time
from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp[@LogicalOp="Index Scan"
or @LogicalOp="Clustered Index Scan"
or @LogicalOp="Table Scan"]')=1
order by total_worker_time DESC