 SRE文档
SRE文档远程连接db
mongo 192.168.3.101:27017/<database> -u <dbuser> -p <dbpassword>
或者
mongo --port 27017 --host 192.168.3.101 <database> -u <dbuser> -p <dbpassword>mongo 192.168.3.101:27017/<database> -u <dbuser> -p <dbpassword>
或者
mongo --port 27017 --host 192.168.3.101 <database> -u <dbuser> -p <dbpassword>uri 连接规则
[]大括号中的字段表示非必填项
mongodb://[username:password@]host1[:port1][,...hostN[:portN]][/[defaultauthdb][?options]]mongodb://[username:password@]host1[:port1][,...hostN[:portN]][/[defaultauthdb][?options]]用户名为testUser,密码为testPwd,默认连接的数据库是testDB,连接的host和端口共三个
mongodb://testUser:testPwd@192.168.1.101:27017,192.168.1.102:27017,192.168.1.103:27017/testDB用户名为testUser,密码为testPwd,默认连接的数据库是testDB,连接的host和端口共三个
mongodb://testUser:testPwd@192.168.1.101:27017,192.168.1.102:27017,192.168.1.103:27017/testDB- 单体数据库
mongodb://mongodb0.example.com:27017mongodb://mongodb0.example.com:27017- 副本集数据库
- 添加
?replicaSet=myRepl可选项
mongodb://mongodb0.example.com:27017,mongodb1.example.com:27017,mongodb2.example.com:27017/?replicaSet=myReplmongodb://mongodb0.example.com:27017,mongodb1.example.com:27017,mongodb2.example.com:27017/?replicaSet=myRepl- 单实例连接
mongodb://leihuo:fa2e5474db854dd@172.16.195.193:47017/rank?authSource=rank&authMechanism=SCRAM-SHA-1mongodb://leihuo:fa2e5474db854dd@172.16.195.193:47017/rank?authSource=rank&authMechanism=SCRAM-SHA-1查看表
> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
test 0.000GB
> use test
switched to db test
#查看有哪些表
> show collections/tables
userdetails
> db.userdetails.find()
{ "_id" : ObjectId("61b711f67978d27bed034272"), "F_Name" : "fist name", "L_NAME" : "last name", "ID_NO" : "12345", "AGE" : "49", "TEL" : "+254654671" }> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
test 0.000GB
> use test
switched to db test
#查看有哪些表
> show collections/tables
userdetails
> db.userdetails.find()
{ "_id" : ObjectId("61b711f67978d27bed034272"), "F_Name" : "fist name", "L_NAME" : "last name", "ID_NO" : "12345", "AGE" : "49", "TEL" : "+254654671" }删除表内容
在MongoDB中删除数据,可通过以下三种方式:
db.collection.remove()
删除单个文档或满足条件的所有文档
db.collection.deleteMany()
删除满足条件的所有文档。
db.collection.bulkWrite()
批量操作接口,可执行批量插入、更新、删除操作
标注:
deleteMany语法简洁
deleteMany,bulkWrite 效率差不多
http://m.zyiz.net/tech/detail-246718.html在MongoDB中删除数据,可通过以下三种方式:
db.collection.remove()
删除单个文档或满足条件的所有文档
db.collection.deleteMany()
删除满足条件的所有文档。
db.collection.bulkWrite()
批量操作接口,可执行批量插入、更新、删除操作
标注:
deleteMany语法简洁
deleteMany,bulkWrite 效率差不多
http://m.zyiz.net/tech/detail-246718.htmldeleteOne
语法:
db.collection.deleteOne()
#传入要删除的那个字段查询条件,删除一条
> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b9867902c77af4a8c1d3af"), "id" : 2, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b2"), "id" : 5, "name" : "ben", "age" : 24 }
> db.user1.deleteOne({name:"ben"})
{ "acknowledged" : true, "deletedCount" : 1 }语法:
db.collection.deleteOne()
#传入要删除的那个字段查询条件,删除一条
> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b9867902c77af4a8c1d3af"), "id" : 2, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b2"), "id" : 5, "name" : "ben", "age" : 24 }
> db.user1.deleteOne({name:"ben"})
{ "acknowledged" : true, "deletedCount" : 1 }deleteMany
> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b9867902c77af4a8c1d3af"), "id" : 2, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b9893702c77af4a8c1d3b3"), "id" : 5, "name" : "mike", "age" : 84 }
> db.user1.deleteMany({ age:84 })
{ "acknowledged" : true, "deletedCount" : 2 }> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b9867902c77af4a8c1d3af"), "id" : 2, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b9893702c77af4a8c1d3b3"), "id" : 5, "name" : "mike", "age" : 84 }
> db.user1.deleteMany({ age:84 })
{ "acknowledged" : true, "deletedCount" : 2 }清空表
drop() 和 remove一样 可以清空整张表
> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
#清空表
> db.user1.remove({})drop() 和 remove一样 可以清空整张表
> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
#清空表
> db.user1.remove({})删除表
语法:db.集合名.remove(条件[,是否删除一条])
> use test;
> db.user1.drop()
true
#条件删除
当存在多条符合条件的行时,只删除一条
db.c3.remove({username:"zs30"},true)
存在多条时,全部删除
db.c3.remove({username:"zs30"},true)> use test;
> db.user1.drop()
true
#条件删除
当存在多条符合条件的行时,只删除一条
db.c3.remove({username:"zs30"},true)
存在多条时,全部删除
db.c3.remove({username:"zs30"},true)字段重命名
{$rename: { <field1>: <newName1>, <field2>: <newName2>, ... } }{$rename: { <field1>: <newName1>, <field2>: <newName2>, ... } }将_id为1的记录中的account_id字段修改为user_id
db.getCollection('user').update({_id:1},{$rename:{"account_id":"user_id"}})db.getCollection('user').update({_id:1},{$rename:{"account_id":"user_id"}})- 批量修改
db.getCollection('user').updateMany({},{$rename:{"account_id":"user_id"}})db.getCollection('user').updateMany({},{$rename:{"account_id":"user_id"}})新建表
#增删改查操作前都要先切换到需要操作的数据库
语法:
db.集合名(Collection).操作(参数)
> use test;
switched to db test
> db.user1.insert( { id:1,name:"jack",age:73 } )
WriteResult({ "nInserted" : 1 })
#或者insertOne,官方推荐方式,效率高
> db.user1.insertOne( { id:2,name:"mike",age:84 } )
{
"acknowledged" : true,
"insertedId" : ObjectId("61b9867902c77af4a8c1d3af")
}
#插入多条数据,insertMany
> db.user1.insertMany([{ id:3,name:"peter",age:14 },{ id:4,name:"tom",age:13 },{ id:5,name:"ben",age:24 }])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("61b986f602c77af4a8c1d3b0"),
ObjectId("61b986f602c77af4a8c1d3b1"),
ObjectId("61b986f602c77af4a8c1d3b2")
]
}#增删改查操作前都要先切换到需要操作的数据库
语法:
db.集合名(Collection).操作(参数)
> use test;
switched to db test
> db.user1.insert( { id:1,name:"jack",age:73 } )
WriteResult({ "nInserted" : 1 })
#或者insertOne,官方推荐方式,效率高
> db.user1.insertOne( { id:2,name:"mike",age:84 } )
{
"acknowledged" : true,
"insertedId" : ObjectId("61b9867902c77af4a8c1d3af")
}
#插入多条数据,insertMany
> db.user1.insertMany([{ id:3,name:"peter",age:14 },{ id:4,name:"tom",age:13 },{ id:5,name:"ben",age:24 }])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("61b986f602c77af4a8c1d3b0"),
ObjectId("61b986f602c77af4a8c1d3b1"),
ObjectId("61b986f602c77af4a8c1d3b2")
]
}查询
语法: db.集合名.find(条件,[查询的列])
db.collection.find(<query>, [projection])db.collection.find(<query>, [projection])| Parameter | Type | Description |
|---|---|---|
| query | document | 可选。使用查询运算符指定选择筛选器。若要返回集合中的所有文档,请省略此参数或传递空文档 ({}) |
| projection | document | 可选。指定要在与查询筛选器匹配的文档中返回的字段(投影)。若要返回匹配文档中的所有字段, |
格式化:db.集合名.find().pretty()
条件:
查询所有数据 {}或者不写
查询age=6的数据 {age:6}
查询age=6且性别为男 {age:6,sex:'男'}
查询的列
不写 - 查询全部的列
{age:1} 只显示age列,可以显示多个想要的列{user:1,age:1.......}
{age:0} 除了age列外都显示 可以不显示多个想要的列{user:0,age:0}
无论怎么写系统自定义_id都会在
#升级:
db.集合名.find(键:值) 注:值不直接写
{运算符:值}
db.集合名.find({
键:{运算符:值}
})
例如:
年龄小于5的
db.c1.find({age:{$lt:5}})
年龄等于3、4、5的
db.c1.find({age:{$in:[3,4,5]}})条件:
查询所有数据 {}或者不写
查询age=6的数据 {age:6}
查询age=6且性别为男 {age:6,sex:'男'}
查询的列
不写 - 查询全部的列
{age:1} 只显示age列,可以显示多个想要的列{user:1,age:1.......}
{age:0} 除了age列外都显示 可以不显示多个想要的列{user:0,age:0}
无论怎么写系统自定义_id都会在
#升级:
db.集合名.find(键:值) 注:值不直接写
{运算符:值}
db.集合名.find({
键:{运算符:值}
})
例如:
年龄小于5的
db.c1.find({age:{$lt:5}})
年龄等于3、4、5的
db.c1.find({age:{$in:[3,4,5]}})查询所有
db.comment.find()
或
db.comment.find({})
#查询数据(find findOne)
> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b9867902c77af4a8c1d3af"), "id" : 2, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b2"), "id" : 5, "name" : "ben", "age" : 24 }
#无条件查找一条数据,默认当前Collection中的第一条数据,只返回一条数据
> db.user1.findOne()
{
"_id" : ObjectId("61b9864202c77af4a8c1d3ae"),
"id" : 1,
"name" : "jack",
"age" : 73
}db.comment.find()
或
db.comment.find({})
#查询数据(find findOne)
> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b9867902c77af4a8c1d3af"), "id" : 2, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b2"), "id" : 5, "name" : "ben", "age" : 24 }
#无条件查找一条数据,默认当前Collection中的第一条数据,只返回一条数据
> db.user1.findOne()
{
"_id" : ObjectId("61b9864202c77af4a8c1d3ae"),
"id" : 1,
"name" : "jack",
"age" : 73
}条件查询
> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b9867902c77af4a8c1d3af"), "id" : 2, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b2"), "id" : 5, "name" : "ben", "age" : 24 }
#根据name查询,在用mongosh,直接是易读方式展示
> db.user1.find({name:"jack"}).pretty()
{
"_id" : ObjectId("61b9864202c77af4a8c1d3ae"),
"id" : 1,
"name" : "jack",
"age" : 73
}> db.user1.find()
{ "_id" : ObjectId("61b9864202c77af4a8c1d3ae"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("61b9867902c77af4a8c1d3af"), "id" : 2, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b0"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b1"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b986f602c77af4a8c1d3b2"), "id" : 5, "name" : "ben", "age" : 24 }
#根据name查询,在用mongosh,直接是易读方式展示
> db.user1.find({name:"jack"}).pretty()
{
"_id" : ObjectId("61b9864202c77af4a8c1d3ae"),
"id" : 1,
"name" : "jack",
"age" : 73
}投影查询(Projection Query)
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)。
如:查询结果只显示 _id、userid、nickname :
db.comment.find({userid:"1003"},{userid:1,nickname:1})db.comment.find({userid:"1003"},{userid:1,nickname:1})如:查询结果只显示 、userid、nickname ,不显示 _id :
db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0})db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0})再例如:查询所有数据,但只显示 _id、userid、nickname :
db.comment.find({},{userid:1,nickname:1})db.comment.find({},{userid:1,nickname:1})限制查询
use test
db.myuser.insert( {name:"shijiange1", age: 20} )
db.myuser.insert( {name:"shijiange2", age: 28} )
db.myuser.insert( {name:"shijiange3", age: 38} )
db.myuser.insert( {name:"zhangsan1", age: 58} )
db.myuser.insert( {name:"zhangsan2", age: 68} )
db.myuser.insert( {name:"zhangsan3", age: 25} )
#查看前面两条记录
shijiange> db.myuser.find().limit(2)
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de7"),
name: 'shijiange1',
age: 20
},
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de8"),
name: 'shijiange2',
age: 28
}
]use test
db.myuser.insert( {name:"shijiange1", age: 20} )
db.myuser.insert( {name:"shijiange2", age: 28} )
db.myuser.insert( {name:"shijiange3", age: 38} )
db.myuser.insert( {name:"zhangsan1", age: 58} )
db.myuser.insert( {name:"zhangsan2", age: 68} )
db.myuser.insert( {name:"zhangsan3", age: 25} )
#查看前面两条记录
shijiange> db.myuser.find().limit(2)
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de7"),
name: 'shijiange1',
age: 20
},
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de8"),
name: 'shijiange2',
age: 28
}
]统计查询
db.collection.count(query, options)db.collection.count(query, options)| Parameter | Type | Description |
|---|---|---|
| query | document | 查询选择条件。 |
| options | document | 可选。用于修改计数的额外选项 |
统计comment集合的所有的记录数:
db.comment.count()db.comment.count()统计userid为1003的记录条数
db.comment.count({userid:"1003"})db.comment.count({userid:"1003"})跳过记录
test>db.myuser.find().skip(2).limit(2)test>db.myuser.find().skip(2).limit(2)分页查询
语法:db.集合名.find().skip(数字).limit(数字)
说明:skip里的数字指跳过指定数量(可选),limit限制查询的数量
db.c2.find().sort({age:-1}).skip(1).limit(2)语法:db.集合名.find().skip(数字).limit(数字)
说明:skip里的数字指跳过指定数量(可选),limit限制查询的数量
db.c2.find().sort({age:-1}).skip(1).limit(2)shijiange> db.myuser.find().skip(0).limit(2)
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de7"),
name: 'shijiange1',
age: 20
},
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de8"),
name: 'shijiange2',
age: 28
}
]
shijiange> db.myuser.find().skip(2).limit(2)
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de9"),
name: 'shijiange3',
age: 38
},
{
_id: ObjectId("61bc01bab9c7cadcc9dd2dea"),
name: 'zhangsan1',
age: 58
}
]
shijiange> db.myuser.find().skip(4).limit(2)
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2deb"),
name: 'zhangsan2',
age: 68
},
{
_id: ObjectId("61bc01bbb9c7cadcc9dd2dec"),
name: 'zhangsan3',
age: 25
}
]shijiange> db.myuser.find().skip(0).limit(2)
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de7"),
name: 'shijiange1',
age: 20
},
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de8"),
name: 'shijiange2',
age: 28
}
]
shijiange> db.myuser.find().skip(2).limit(2)
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de9"),
name: 'shijiange3',
age: 38
},
{
_id: ObjectId("61bc01bab9c7cadcc9dd2dea"),
name: 'zhangsan1',
age: 58
}
]
shijiange> db.myuser.find().skip(4).limit(2)
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2deb"),
name: 'zhangsan2',
age: 68
},
{
_id: ObjectId("61bc01bbb9c7cadcc9dd2dec"),
name: 'zhangsan3',
age: 25
}
]聚合查询
db.集合名称.aggregate([
{管道:{表达式}}
....
])
常用管道:
$group 将集合中的文档分组,用于统计结果
$match 过滤数据,只要输出符合条件的文档
$sort 聚合数据进一步排序
$skip 跳过指定文档数
$limit 限制集合数据返回文档数
....
常用表达式:
$sum 总和 $sum:1同count表示统计
$avg 平均
$min 最小值
$max 最大值
准备:
db.c3.insert({_id:1,name:"a",sex:1,age:1})
db.c3.insert({_id:2,name:"a",sex:1,age:2})
db.c3.insert({_id:3,name:"b",sex:1,age:3})
db.c3.insert({_id:4,name:"c",sex:2,age:4})
db.c3.insert({_id:5,name:"d",sex:2,age:5})
操作:
男女生的总年龄
#_id 必须加,后跟指定列
#rew 求和 返回结果数
db.c3.aggregate([
{
$group:{
_id:"$sex",
res:{$sum:"$sex"}
}
}
])
求男女总人数
db.c3.aggregate([
{
$group:{
_id:"$sex",
res:{$sum:1}
}
}
])
求学生总数和平均年龄
db.c3.aggregate([
{
$group:{
_id:null,
res:{$sum:1},
total_avg:{$avg:"$age"}
}
}
])
查询男生女生人数,升序排序
db.c3.aggregate([
{$group:{ _id:"$sex",res:{$sum:1}}},
{$sort:{res:1}}
])db.集合名称.aggregate([
{管道:{表达式}}
....
])
常用管道:
$group 将集合中的文档分组,用于统计结果
$match 过滤数据,只要输出符合条件的文档
$sort 聚合数据进一步排序
$skip 跳过指定文档数
$limit 限制集合数据返回文档数
....
常用表达式:
$sum 总和 $sum:1同count表示统计
$avg 平均
$min 最小值
$max 最大值
准备:
db.c3.insert({_id:1,name:"a",sex:1,age:1})
db.c3.insert({_id:2,name:"a",sex:1,age:2})
db.c3.insert({_id:3,name:"b",sex:1,age:3})
db.c3.insert({_id:4,name:"c",sex:2,age:4})
db.c3.insert({_id:5,name:"d",sex:2,age:5})
操作:
男女生的总年龄
#_id 必须加,后跟指定列
#rew 求和 返回结果数
db.c3.aggregate([
{
$group:{
_id:"$sex",
res:{$sum:"$sex"}
}
}
])
求男女总人数
db.c3.aggregate([
{
$group:{
_id:"$sex",
res:{$sum:1}
}
}
])
求学生总数和平均年龄
db.c3.aggregate([
{
$group:{
_id:null,
res:{$sum:1},
total_avg:{$avg:"$age"}
}
}
])
查询男生女生人数,升序排序
db.c3.aggregate([
{$group:{ _id:"$sex",res:{$sum:1}}},
{$sort:{res:1}}
])sort排序
语法:db.集合名.find().sort(JSON数据)
说明:键-就是要排序的列/字段,值:1升序 -1降序
使用:对年龄进行降序排序
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关语法:db.集合名.find().sort(JSON数据)
说明:键-就是要排序的列/字段,值:1升序 -1降序
使用:对年龄进行降序排序
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关shijiange>db.myuser.find().sort({ age: 1 }) #按age升序
db.myuser.find().sort({ age: -1 }) #按age降序shijiange>db.myuser.find().sort({ age: 1 }) #按age升序
db.myuser.find().sort({ age: -1 }) #按age降序比较查询
shijiange> db.myuser.find({ age: {$lt: 30} })
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de7"),
name: 'shijiange1',
age: 20
},
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de8"),
name: 'shijiange2',
age: 28
},
{
_id: ObjectId("61bc01bbb9c7cadcc9dd2dec"),
name: 'zhangsan3',
age: 25
}
]shijiange> db.myuser.find({ age: {$lt: 30} })
[
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de7"),
name: 'shijiange1',
age: 20
},
{
_id: ObjectId("61bc01bab9c7cadcc9dd2de8"),
name: 'shijiange2',
age: 28
},
{
_id: ObjectId("61bc01bbb9c7cadcc9dd2dec"),
name: 'zhangsan3',
age: 25
}
]| 参数 | 解释 |
|---|---|
| $gt | 大于 |
| $lt | 小于 |
| $gte | 大于或等于 |
| $lte | 小于或等于 |
| $or | 或 |
| $and | 并且 |
| $ne | 不等于 |
| $in | 包含 |
| $nin | 不包含 |
包含查询
包含使用$in操作符。
示例:查询评论的集合中userid字段包含1003或1004的文档
db.comment.find({userid:{$in:["1003","1004"]}})db.comment.find({userid:{$in:["1003","1004"]}})不包含使用$nin操作符。
示例:查询评论集合中userid字段不包含1003和1004的文档
db.comment.find({userid:{$nin:["1003","1004"]}})db.comment.find({userid:{$nin:["1003","1004"]}})条件连接查询
如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联。 格式为:
$and:[ { },{ },{ } ]$and:[ { },{ },{ } ]示例:查询评论集合中likenum大于等于700 并且小于2000的文档:
db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})如果两个以上条件之间是或者的关系,我们使用 操作符进行关联,与前面 and的使用方式相同 格式为:
$or:[ { },{ },{ } ]$or:[ { },{ },{ } ]示例:查询评论集合中userid为1003,或者点赞数小于1000的文档记录
db.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]})db.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]})逻辑条件
db.myuser.find( {name: 'shijiange1'} )
db.myuser.find( {name: 'shijiange2'} )
db.myuser.find({ $or: [ {name: 'shijiange1'},{name: 'shijiange2'} ] })
db.myuser.find({ $and: [ {name: 'shijiange1'},{age: 20} ] })db.myuser.find( {name: 'shijiange1'} )
db.myuser.find( {name: 'shijiange2'} )
db.myuser.find({ $or: [ {name: 'shijiange1'},{name: 'shijiange2'} ] })
db.myuser.find({ $and: [ {name: 'shijiange1'},{age: 20} ] })正则查询
db.collection.find({field:/正则表达式/})
或
db.集合.find({字段:/正则表达式/})
正则表达式是js的语法,直接量的写法db.collection.find({field:/正则表达式/})
或
db.集合.find({字段:/正则表达式/})
正则表达式是js的语法,直接量的写法#支持普通正则和扩展正则
db.myuser.find({ name: {$regex: "shijiange[1-9]"} }) #普通正则过滤
db.myuser.find( {"name":{$regex:"(zhangsan)"}} ) #支持分组正则#支持普通正则和扩展正则
db.myuser.find({ name: {$regex: "shijiange[1-9]"} }) #普通正则过滤
db.myuser.find( {"name":{$regex:"(zhangsan)"}} ) #支持分组正则更新表
| 运算符 | 作用 |
|---|---|
| $inc | 递增 |
| $rename | 重命名列 |
| $set | 修改列值 |
| $unset | 删除列 |
基础语法: db.集合名.update(条件,新数据[,是否新增,是否修改多条])
是否新增:指条件匹配不到数据则插入,true是插入,false否不插入默认
是否修改多条:指将匹配成功的数据都修改(true是,false否默认)
for(var i=1;i<=10;i++){
db.c3.insert({username:"zs"+i,age:i});
}
db.c3.update({username:"zs1"},{username:"zs2"})#这样是替换,将符合条件的行直接换成这个是否新增:指条件匹配不到数据则插入,true是插入,false否不插入默认
是否修改多条:指将匹配成功的数据都修改(true是,false否默认)
for(var i=1;i<=10;i++){
db.c3.insert({username:"zs"+i,age:i});
}
db.c3.update({username:"zs1"},{username:"zs2"})#这样是替换,将符合条件的行直接换成这个升级语法:
db.c3.update({username:"zs2"},{$set:{username:"zs222"}})
给zs10 增加2岁
db.c3.update({username:"zs10"},{$inc:{age:2}})
给zs10 减少2岁
db.c3.update({username:"zs10"},{$inc:{age:-2}})
准备:插入一个数据: db.c4.insert({username:"熊子阳",age:18,who:"男",other:"没钱"})
修改数据,将 熊子阳 改为 Aoi ,age 改为999 ,who 改为 sex ,other 删除
db.c4.update({username:"熊子阳"},
{$set:{username:"Aoi"}},
{$inc:{age:971}},
{$rename:{who:sex}},
{$unset:{other:true}})
正确写法:
db.c4.update({username:"熊子阳"},{
$set:{username:"Aoi"},
$inc:{age:971},
$rename:{who:"sex"},
$unset:{other:true}
})
#更新不存在的值,若不存在则不会有操作
> db.c3.update({username:"zs30"},{$set:{age:30}})
#在最后加一个true参数,作用是,如果不存在,则插入该条数据,默认为false则不管
> db.c3.update({username:"zs30"},{$set:{age:30}},true)
#第四个参数如果为true,当匹配到多条条件符合的元素时,都更改,默认为false,只改一条
> db.c3.update({},{$set:{age:20}},false,true)db.c3.update({username:"zs2"},{$set:{username:"zs222"}})
给zs10 增加2岁
db.c3.update({username:"zs10"},{$inc:{age:2}})
给zs10 减少2岁
db.c3.update({username:"zs10"},{$inc:{age:-2}})
准备:插入一个数据: db.c4.insert({username:"熊子阳",age:18,who:"男",other:"没钱"})
修改数据,将 熊子阳 改为 Aoi ,age 改为999 ,who 改为 sex ,other 删除
db.c4.update({username:"熊子阳"},
{$set:{username:"Aoi"}},
{$inc:{age:971}},
{$rename:{who:sex}},
{$unset:{other:true}})
正确写法:
db.c4.update({username:"熊子阳"},{
$set:{username:"Aoi"},
$inc:{age:971},
$rename:{who:"sex"},
$unset:{other:true}
})
#更新不存在的值,若不存在则不会有操作
> db.c3.update({username:"zs30"},{$set:{age:30}})
#在最后加一个true参数,作用是,如果不存在,则插入该条数据,默认为false则不管
> db.c3.update({username:"zs30"},{$set:{age:30}},true)
#第四个参数如果为true,当匹配到多条条件符合的元素时,都更改,默认为false,只改一条
> db.c3.update({},{$set:{age:20}},false,true)update
#要注意的是({"条件"},{"关键字":{"修改内容"}}),其中如果条件为空,那么将会修改Collection中所有的数据(不推荐)
语法:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别#要注意的是({"条件"},{"关键字":{"修改内容"}}),其中如果条件为空,那么将会修改Collection中所有的数据(不推荐)
语法:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别- update
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
#更新
> db.user1.update( {"name":"peter" }, {$set: {age:21} })
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4"), "id" : 3, "name" : "peter", "age" : 21 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
#条件为空
> db.user1.update( {"name":"peter" }, {})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
>> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4"), "id" : 3, "name" : "peter", "age" : 14 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
#更新
> db.user1.update( {"name":"peter" }, {$set: {age:21} })
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4"), "id" : 3, "name" : "peter", "age" : 21 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
#条件为空
> db.user1.update( {"name":"peter" }, {})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
>updateOne
#根据条件修改一条数据的内容,如出现多条,只修改最靠前的数据
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }
> db.user1.updateOne( {age:84 }, {$set: {"name":"xiao"} })
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }#根据条件修改一条数据的内容,如出现多条,只修改最靠前的数据
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "mike", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }
> db.user1.updateOne( {age:84 }, {$set: {"name":"xiao"} })
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }更新字段
#查询到指定的字段的数据,更新加一个字段
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }
> db.user1.updateOne( {age:13 }, {$set: {hobby:["羽毛球","篮球","足球"]} })
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13, "hobby" : [ "羽毛球", "篮球", "足球" ] }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }#查询到指定的字段的数据,更新加一个字段
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13 }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }
> db.user1.updateOne( {age:13 }, {$set: {hobby:["羽毛球","篮球","足球"]} })
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13, "hobby" : [ "羽毛球", "篮球", "足球" ] }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }updateMany
#根据条件新增字段
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13, "hobby" : [ "羽毛球", "篮球", "足球" ] }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }
> db.user1.updateMany( {age:84 }, {$set: {gender:"男"} })
{ "acknowledged" : true, "matchedCount" : 2, "modifiedCount" : 2 }
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13, "hobby" : [ "羽毛球", "篮球", "足球" ] }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84, "gender" : "男" }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84, "gender" : "男" }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }#根据条件新增字段
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13, "hobby" : [ "羽毛球", "篮球", "足球" ] }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84 }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84 }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }
> db.user1.updateMany( {age:84 }, {$set: {gender:"男"} })
{ "acknowledged" : true, "matchedCount" : 2, "modifiedCount" : 2 }
> db.user1.find()
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b4") }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b5"), "id" : 4, "name" : "tom", "age" : 13, "hobby" : [ "羽毛球", "篮球", "足球" ] }
{ "_id" : ObjectId("61b98a4002c77af4a8c1d3b6"), "id" : 5, "name" : "ben", "age" : 24 }
{ "_id" : ObjectId("61b98cab02c77af4a8c1d3b7"), "id" : 6, "name" : "xiao", "age" : 84, "gender" : "男" }
{ "_id" : ObjectId("61b98cb402c77af4a8c1d3b8"), "id" : 7, "name" : "li", "age" : 84, "gender" : "男" }
{ "_id" : ObjectId("61b98cc302c77af4a8c1d3b9"), "id" : 8, "name" : "han", "age" : 18 }增加表
语法:
db.集合名.insert(JSON数据)
集合存在,则直接插入数据,集合不存在,隐式创建并插入
>use test
>db.c1.insert({username:"xzy",age:18})
#批量插入
>db.c1.insertMany({})
插入多条数据:
传递数组,数组中每个元素都是一个JSON类型
db.c1.insert([
{username:"z3",age:3},
{username:"z4",age:4},
{username:"z5",age:5}
])
#插入十条数据: ,mongodb底层使用JS引擎实现的,所以支持部分js语法,可以使用for循环
for(var i=1;i<=10;i++){
db.c1.insert({username:"a"+i,age:i})
}>use test
>db.c1.insert({username:"xzy",age:18})
#批量插入
>db.c1.insertMany({})
插入多条数据:
传递数组,数组中每个元素都是一个JSON类型
db.c1.insert([
{username:"z3",age:3},
{username:"z4",age:4},
{username:"z5",age:5}
])
#插入十条数据: ,mongodb底层使用JS引擎实现的,所以支持部分js语法,可以使用for循环
for(var i=1;i<=10;i++){
db.c1.insert({username:"a"+i,age:i})
}索引
语法:
db.collection.createIndex(keys, options)
MongoDB中1代表升序,-1代表降序语法:
db.collection.createIndex(keys, options)
MongoDB中1代表升序,-1代表降序options
| 参数 | 类型 | 描述 |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。如:key_1、key_-1、key_text。 |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
其中需要关注的参数:background、unique和expireAfterSeconds,并且索引默认是区分大小写的
use shijiange
for(i=1; i<=500000;i++){
db.myuser.insert( {name:'mytest'+i, age:i} )
}
#统计条数
shijiange> db.myuser.countDocuments()
354739
mongodb有慢查询的概念,默认是超过100ms会记录慢日志mongodb.log
>db.getProfilingStatus()
shijiange> db.myuser.find( {age:9999} )
[
{
_id: ObjectId("61bc0505b9c7cadcc9dd54fb"),
name: 'mytest9999',
age: 9999
}
]
#需要花费162ms
{"t":{"$date":"2021-12-16T22:51:45.308-05:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn2","msg":"Slow query","attr":{"type":"command","ns":"shijiange.myuser","appName":"mongosh 1.1.6","command":{"find":"myuser","filter":{"age":9999},"lsid":{"id":{"$uuid":"5d6c3e2a-fc12-4827-9e9e-e998705691b5"}},"$db":"shijiange"},"planSummary":"COLLSCAN","keysExamined":0,"docsExamined":500006,"cursorExhausted":true,"numYields":500,"nreturned":1,"queryHash":"3838C5F3","planCacheKey":"BB98D80C","reslen":160,"locks":{"Global":{"acquireCount":{"r":501}},"Mutex":{"acquireCount":{"r":1}}},"storage":{},"remote":"127.0.0.1:58358","protocol":"op_msg","durationMillis":162}}use shijiange
for(i=1; i<=500000;i++){
db.myuser.insert( {name:'mytest'+i, age:i} )
}
#统计条数
shijiange> db.myuser.countDocuments()
354739
mongodb有慢查询的概念,默认是超过100ms会记录慢日志mongodb.log
>db.getProfilingStatus()
shijiange> db.myuser.find( {age:9999} )
[
{
_id: ObjectId("61bc0505b9c7cadcc9dd54fb"),
name: 'mytest9999',
age: 9999
}
]
#需要花费162ms
{"t":{"$date":"2021-12-16T22:51:45.308-05:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn2","msg":"Slow query","attr":{"type":"command","ns":"shijiange.myuser","appName":"mongosh 1.1.6","command":{"find":"myuser","filter":{"age":9999},"lsid":{"id":{"$uuid":"5d6c3e2a-fc12-4827-9e9e-e998705691b5"}},"$db":"shijiange"},"planSummary":"COLLSCAN","keysExamined":0,"docsExamined":500006,"cursorExhausted":true,"numYields":500,"nreturned":1,"queryHash":"3838C5F3","planCacheKey":"BB98D80C","reslen":160,"locks":{"Global":{"acquireCount":{"r":501}},"Mutex":{"acquireCount":{"r":1}}},"storage":{},"remote":"127.0.0.1:58358","protocol":"op_msg","durationMillis":162}}explain
shijiange> db.myuser.find( {age:9999} ).explain(true)
{
explainVersion: '1',
queryPlanner: {
namespace: 'shijiange.myuser',
indexFilterSet: false,
parsedQuery: { age: { '$eq': 9999 } },
maxIndexedOrSolutionsReached: false,
maxIndexedAndSolutionsReached: false,
maxScansToExplodeReached: false,
winningPlan: {
stage: 'COLLSCAN', #---------------------->>注意这里,collscan全表扫描
filter: { age: { '$eq': 9999 } },
direction: 'forward'
},
rejectedPlans: []
},
executionStats: {
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 166,-----------》》执行时间ms
totalKeysExamined: 0,
totalDocsExamined: 500006,
executionStages: {
stage: 'COLLSCAN',
filter: { age: { '$eq': 9999 } },
nReturned: 1,
executionTimeMillisEstimate: 2,
works: 500008,
advanced: 1,
needTime: 500006,
needYield: 0,
saveState: 500,
restoreState: 500,
isEOF: 1,
direction: 'forward',
docsExamined: 500006
},
allPlansExecution: []
},
command: { find: 'myuser', filter: { age: 9999 }, '$db': 'shijiange' },
serverInfo: {
host: 'slave01',
port: 27017,
version: '5.0.5',
gitVersion: 'd65fd89df3fc039b5c55933c0f71d647a54510ae'
},
serverParameters: {
internalQueryFacetBufferSizeBytes: 104857600,
internalQueryFacetMaxOutputDocSizeBytes: 104857600,
internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,
internalDocumentSourceGroupMaxMemoryBytes: 104857600,
internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,
internalQueryProhibitBlockingMergeOnMongoS: 0,
internalQueryMaxAddToSetBytes: 104857600,
internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600
},
ok: 1
}shijiange> db.myuser.find( {age:9999} ).explain(true)
{
explainVersion: '1',
queryPlanner: {
namespace: 'shijiange.myuser',
indexFilterSet: false,
parsedQuery: { age: { '$eq': 9999 } },
maxIndexedOrSolutionsReached: false,
maxIndexedAndSolutionsReached: false,
maxScansToExplodeReached: false,
winningPlan: {
stage: 'COLLSCAN', #---------------------->>注意这里,collscan全表扫描
filter: { age: { '$eq': 9999 } },
direction: 'forward'
},
rejectedPlans: []
},
executionStats: {
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 166,-----------》》执行时间ms
totalKeysExamined: 0,
totalDocsExamined: 500006,
executionStages: {
stage: 'COLLSCAN',
filter: { age: { '$eq': 9999 } },
nReturned: 1,
executionTimeMillisEstimate: 2,
works: 500008,
advanced: 1,
needTime: 500006,
needYield: 0,
saveState: 500,
restoreState: 500,
isEOF: 1,
direction: 'forward',
docsExamined: 500006
},
allPlansExecution: []
},
command: { find: 'myuser', filter: { age: 9999 }, '$db': 'shijiange' },
serverInfo: {
host: 'slave01',
port: 27017,
version: '5.0.5',
gitVersion: 'd65fd89df3fc039b5c55933c0f71d647a54510ae'
},
serverParameters: {
internalQueryFacetBufferSizeBytes: 104857600,
internalQueryFacetMaxOutputDocSizeBytes: 104857600,
internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,
internalDocumentSourceGroupMaxMemoryBytes: 104857600,
internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,
internalQueryProhibitBlockingMergeOnMongoS: 0,
internalQueryMaxAddToSetBytes: 104857600,
internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600
},
ok: 1
}查询索引
shijiange> db.myuser.getIndexes()
[ { v: 2, key: { _id: 1 }, name: '_id_' } ]shijiange> db.myuser.getIndexes()
[ { v: 2, key: { _id: 1 }, name: '_id_' } ]查索引大小
db.collection.totalIndexSize()db.collection.totalIndexSize()添加索引
升序索引
#增加age的升序索引
db.myuser.createIndex({ 'age': 1 })
#或者
db.myuser.ensureIndex( {age:1} )
db.myuser.getIndexes()
db.myuser.find( {age:9999} )
db.myuser.find( {age:9999} ).explain(true)#增加age的升序索引
db.myuser.createIndex({ 'age': 1 })
#或者
db.myuser.ensureIndex( {age:1} )
db.myuser.getIndexes()
db.myuser.find( {age:9999} )
db.myuser.find( {age:9999} ).explain(true)后台创建索引
db.collection.createIndex({ 'name': 1,'createTime': -1 }, { background: true })db.collection.createIndex({ 'name': 1,'createTime': -1 }, { background: true })前台操作,它会阻塞用户对数据的读写操作直到索引构建完毕;后台模式,不阻塞数据读写操作,独立的后台线程异步构建索引,此时仍然允许对数据的读写操作。创建索引时一定要写{ background: true }
唯一索引
db.collection.createIndex({ 'name': 1 }, { unique: true })db.collection.createIndex({ 'name': 1 }, { unique: true })唯一索引是索引具有的一种属性,让索引具备唯一性,确保这张表中,该条索引数据不会重复出现。在每一次insert和update操作时,都会进行索引的唯一性校验,保证该索引的字段组合在表中唯一
时间索引
db.collection.createIndex({ 'createTime': -1 }, { expireAfterSeconds: 180 })db.collection.createIndex({ 'createTime': -1 }, { expireAfterSeconds: 180 })需要注意,使用expireAfterSeconds选项时候,索引关键字段必须是 Date 类型,只支持单字段索引,删除操作非立即执行,默认60秒扫描一次Document数据
索引
db.collection.createIndex({ 'name': 1 })
db.collection.find({
'name': { $regex: '其他' }
}).explain('executionStats')db.collection.createIndex({ 'name': 1 })
db.collection.find({
'name': { $regex: '其他' }
}).explain('executionStats')删除索引
db.collection.dropIndexes() //删除所有所有, _id 索引会除外
db.collection.dropIndex('name') //删除上述name索引
db.collection.dropIndex({ 'name': 1}) //删除name升序索引db.collection.dropIndexes() //删除所有所有, _id 索引会除外
db.collection.dropIndex('name') //删除上述name索引
db.collection.dropIndex({ 'name': 1}) //删除name升序索引db.myuser.dropIndex( {age:1} )
使用正则的话,索引无效果
db.myuser.find( {"name":"mytest1"} )
db.myuser.ensureIndex( {name:1} ) #添加索引
db.myuser.find( {"name":"mytest6"} )
db.myuser.find( {"name":/99999/} )
db.myuser.find( {"name":/99999/} ).explain(true) #使用正则,全表扫描,也是慢db.myuser.dropIndex( {age:1} )
使用正则的话,索引无效果
db.myuser.find( {"name":"mytest1"} )
db.myuser.ensureIndex( {name:1} ) #添加索引
db.myuser.find( {"name":"mytest6"} )
db.myuser.find( {"name":/99999/} )
db.myuser.find( {"name":/99999/} ).explain(true) #使用正则,全表扫描,也是慢唯一索引
#唯一索引对应的值不能重复
use shijiange
db.myuser.insert( {userid:1} )
db.myuser.insert( {userid:1} )
db.myuser.remove({}) #清空数据
db.myuser.ensureIndex( {userid:1},{unique:true} ) #创建唯一索引
db.myuser.insert( {userid:1} )
db.myuser.insert( {userid:2} )
db.myuser.insert( {userid:1} ) #因为是唯一索引,所以会报错#唯一索引对应的值不能重复
use shijiange
db.myuser.insert( {userid:1} )
db.myuser.insert( {userid:1} )
db.myuser.remove({}) #清空数据
db.myuser.ensureIndex( {userid:1},{unique:true} ) #创建唯一索引
db.myuser.insert( {userid:1} )
db.myuser.insert( {userid:2} )
db.myuser.insert( {userid:1} ) #因为是唯一索引,所以会报错重建索引
db.collection.reIndex()db.collection.reIndex()一般是在collection经过很多次修改后,导致collection的文件产生空洞,这时候就会使用到这个方法,通过索引的重建,减少索引文件碎片,并提高索引的效率。
但是重建索引需要遍历整个collection,在数据量很大的情况下,这个过程会非常的慢
修改索引
若要修改现有索引,则需要删除现有索引并重新创建索引
索引类型
单键索引(Single Field)
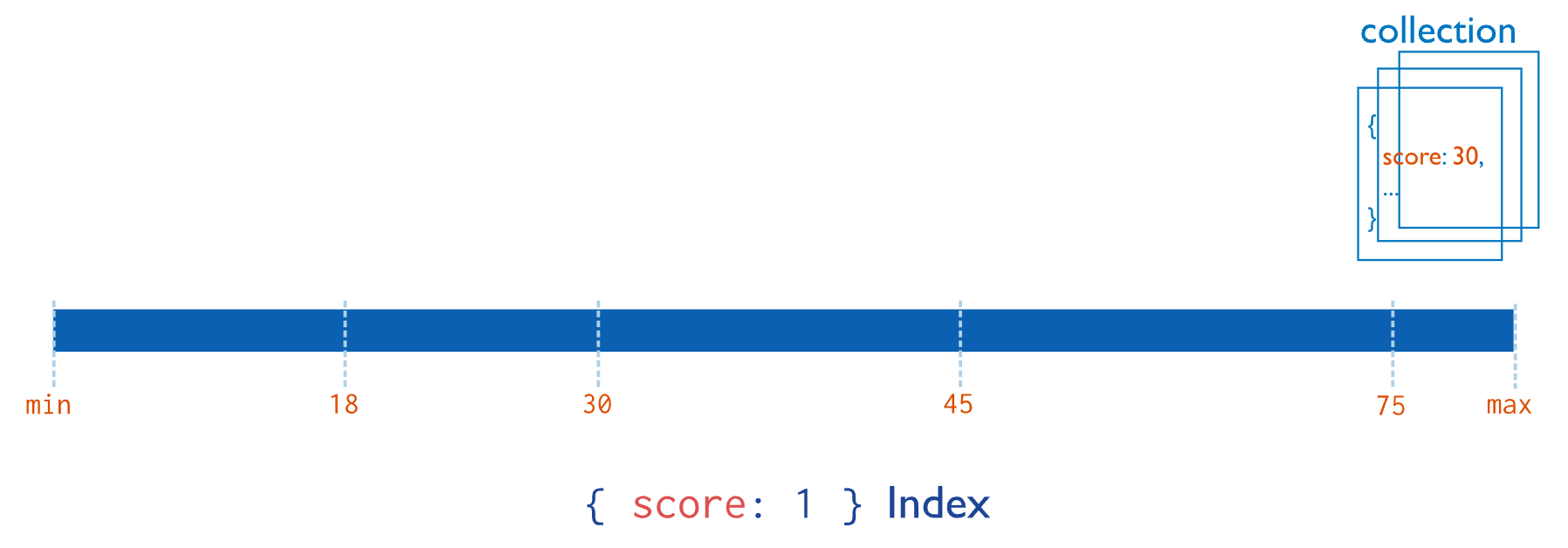
{ key: 1 }{ key: 1 }在默认情况下,所有collection在 _id 字段上都有一个索引,应用程序和用户可以添加额外的索引来支持重要的查询操作。
对于单字段索引和排序操作,索引键的排序顺序(即升序或降序)无关紧要,因为 MongoDB 可以在任意方向上遍历索引
复合索引(Compound Index)

{ key1: 1, key2: 1 }{ key1: 1, key2: 1 }复合索引就是多个字段一起匹配,需要注意的是,在建立复合索引的时候一定要注意顺序的问题,顺序不同将导致查询的结果也不相同
多键值索引(Multikey Index)
{ 'key.sub_key': 1 }{ 'key.sub_key': 1 }也被称为"数组索引",可以对包含数组的字段建立索引。
MongoDB会为数组中的每个元素创建索引键,这些多键值索引支持对数组字段的高效查询。
对数组建立索引的代价是非常高的,它实际上是会对数组中的每一项都单独建立索引,就相当于假设数组中有十项,那么就会在原基础上,多出十倍的索引大小。所以在MongoDB中是禁止对两个数组添加复合索引的,对两个数组添加索引那么索引大小将是爆炸增长
地理位置索引(Geospatial Index)
{ key: '2d' }
{ key: '2dsphere' }{ key: '2d' }
{ key: '2dsphere' }对于保存的经纬度数据字段中,建立地理位置索引可以高效的实现查询,比如说"查找附近的人","查找附近的商家"等。
MongoDB提供两种索引:2D索引和2D球面索引,一种是以平面几何的结果输出,另一种是以球面几何的结果输出。目前这类索引在工作中使用较少
全文索引(Text Indexes)
{ key: 'text' }{ key: 'text' }使用全文索引查找关键词:mongodb
db.collection.find({ $text: { $search: 'mongodb' } })db.collection.find({ $text: { $search: 'mongodb' } })建立全文索引:
db.collection.createIndex({ author: 'text', description: 'text' })db.collection.createIndex({ author: 'text', description: 'text' })哈希索引(Hashed Indexes)
{ key: 'hashed' }{ key: 'hashed' }是指按照某个字段的hash值来建立索引,它的速度比普通索引快,但是无法进行范围查询进行优化,适宜于随机性强的散列。
哈希索引可以用作哈希分片键来对数据进行分片。基于哈希的分片将字段的哈希索引用作分片键,以跨分片群集对数据进行分区,使用哈希分片键对集合进行分片使数据分布更随机
2.修复数据库
在MongoDB中4.0.3,对 WiredTiger 引擎,使用该命令会进行以下操作
- 重建所有索引
- 丢弃损坏的数据
- 为残缺的元数据创建存根文件。
对于MMAPv1 引擎
- 重建所有索引
- 丢弃损坏的数据
数据恢复流程:
先备份现有的数据
我们可以用 cp 命令将现有的数据的整个目录的所有文件都备份一份。
使用 mongod --repair
shell# 针对 所有数据库,停止服务 mongod --repair # 针对 单个数据库 mongod --dbpath /opt/mongodb/data/djx --repair# 针对 所有数据库,停止服务 mongod --repair # 针对 单个数据库 mongod --dbpath /opt/mongodb/data/djx --repair
3.关闭数据库
mongo_shell
#支持tab命令补齐
> use admin;
switched to db admin
> db.shutdownServer()
server should be down...#支持tab命令补齐
> use admin;
switched to db admin
> db.shutdownServer()
server should be down...shell
sudo -u mongod mongod -f /data/mongodb/conf/mongodb.conf --shutdownsudo -u mongod mongod -f /data/mongodb/conf/mongodb.conf --shutdown4.删除数据库
#当库中没有表的时候,mongodb 自动清理库
>use test
>db.dropDatabase()
#或者
mongod --shutdown --dbpath /data/mongodb/data#当库中没有表的时候,mongodb 自动清理库
>use test
>db.dropDatabase()
#或者
mongod --shutdown --dbpath /data/mongodb/data5.非交互式
echo 'db.serverStatus()' | mongo 127.0.0.1:27017
echo 'db.serverStatus().opcounters' | mongo 127.0.0.1:27017echo 'db.serverStatus()' | mongo 127.0.0.1:27017
echo 'db.serverStatus().opcounters' | mongo 127.0.0.1:270176.文档事务
ACID支持程度
| 事务属性 | 支持程度 |
|---|---|
| Atomocity 原子性 | 单表单文档:1.x 就开始支持 复制集多表多行:4.0 开始支持 分片集多表多行:4.2 开始支持 |
| Consistency 一致性 | writeConcern, readConcern |
| Isolation 隔离性 | readConcern |
| Durability 持久性 | Journal and Replication |
多文档事务使用方法
MongoDB多文档事务的使用方式与关系型数据库基本类似。
但是需要注意的是:多文档事务只能应用在副本集 或 mongos 节点上。如果你只是一个单点的mongo实例,是无法进行多文档事务实践的
- shell下
var session = db.getMongo().startSession();
session.startTransaction({readConcern: { level: 'majority' },writeConcern: { w: 'majority' }});
var coll1 = session.getDatabase('students').getCollection('teams');
coll1.update({name: 'yzw-football-team'}, {$set: {members: 20}});
var coll2 = session.getDatabase('students').getCollection('records');
coll1.update({name: 'Edison'}, {$set: {gender: 'Female'}});
// 成功提交事务
session.commitTransaction();
// 失败事务回滚
session.abortTransaction();var session = db.getMongo().startSession();
session.startTransaction({readConcern: { level: 'majority' },writeConcern: { w: 'majority' }});
var coll1 = session.getDatabase('students').getCollection('teams');
coll1.update({name: 'yzw-football-team'}, {$set: {members: 20}});
var coll2 = session.getDatabase('students').getCollection('records');
coll1.update({name: 'Edison'}, {$set: {gender: 'Female'}});
// 成功提交事务
session.commitTransaction();
// 失败事务回滚
session.abortTransaction();7.慢日志
- 配置文件设置yaml
operationProfiling:
slowOpThresholdMs: 200 # 阈值,默认值为100,单位毫秒
mode: slowOp # 默认为 off,可选值 off、slowOp(对应上面的等级 1)、all(对应上面的等级 2)
lowOpSampleRate: 0.42 #随机采集慢查询的百分比值,sampleRate 值默认为1,表示都采集,0.42 表示采集42%的内容operationProfiling:
slowOpThresholdMs: 200 # 阈值,默认值为100,单位毫秒
mode: slowOp # 默认为 off,可选值 off、slowOp(对应上面的等级 1)、all(对应上面的等级 2)
lowOpSampleRate: 0.42 #随机采集慢查询的百分比值,sampleRate 值默认为1,表示都采集,0.42 表示采集42%的内容#普通文件
#开启慢查询,200毫秒的记录
profile = 1
slowms = 200#普通文件
#开启慢查询,200毫秒的记录
profile = 1
slowms = 200- 通过mongo shell
#针对某个库进行配置
>use test
#查看状态:级别和时间
drug:PRIMARY> db.getProfilingStatus()
{ "was" : 1, "slowms" : 100 }
#查看级别
drug:PRIMARY> db.getProfilingLevel()
1
#设置级别
drug:PRIMARY> db.setProfilingLevel(2)
{ "was" : 1, "slowms" : 100, "ok" : 1 }
#设置级别和时间
drug:PRIMARY> db.setProfilingLevel(1,200)
{ "was" : 2, "slowms" : 100, "ok" : 1 }#针对某个库进行配置
>use test
#查看状态:级别和时间
drug:PRIMARY> db.getProfilingStatus()
{ "was" : 1, "slowms" : 100 }
#查看级别
drug:PRIMARY> db.getProfilingLevel()
1
#设置级别
drug:PRIMARY> db.setProfilingLevel(2)
{ "was" : 1, "slowms" : 100, "ok" : 1 }
#设置级别和时间
drug:PRIMARY> db.setProfilingLevel(1,200)
{ "was" : 2, "slowms" : 100, "ok" : 1 }- 启动时添加
mongod --profile=1 --slowms=200mongod --profile=1 --slowms=200修改慢日志大小
#关闭Profiling
drug:PRIMARY> db.setProfilingLevel(0)
{ "was" : 0, "slowms" : 200, "ok" : 1 }
#删除system.profile集合
drug:PRIMARY> db.system.profile.drop()
true
#创建一个新的system.profile集合
drug:PRIMARY> db.createCollection( "system.profile", { capped: true, size:4000000 } )
{ "ok" : 1 }
#重新开启Profiling
drug:PRIMARY> db.setProfilingLevel(1)
{ "was" : 0, "slowms" : 200, "ok" : 1 }#关闭Profiling
drug:PRIMARY> db.setProfilingLevel(0)
{ "was" : 0, "slowms" : 200, "ok" : 1 }
#删除system.profile集合
drug:PRIMARY> db.system.profile.drop()
true
#创建一个新的system.profile集合
drug:PRIMARY> db.createCollection( "system.profile", { capped: true, size:4000000 } )
{ "ok" : 1 }
#重新开启Profiling
drug:PRIMARY> db.setProfilingLevel(1)
{ "was" : 0, "slowms" : 200, "ok" : 1 }注意:要改变Secondary的system.profile的大小,你必须停止Secondary,运行它作为一个独立的,然后再执行上述步骤。完成后,重新启动加入副本集
查询命令
# 查询最近的10个慢查询日志
db.system.profile.find().limit(10).sort( { ts : -1 } ).pretty()
# 查询除命令类型为 ‘command’ 的日志
db.system.profile.find( { op: { $ne : 'command' } } ).pretty()
# 查询数据库为 mydb 集合为 test 的 日志
db.system.profile.find( { ns : 'mydb.test' } ).pretty()
# 查询 低于 5毫秒的日志
db.system.profile.find( { millis : { $gt : 5 } } ).pretty()
# 查询时间从 2012-12-09 3点整到 2012-12-09 3点40分之间的日志
db.system.profile.find({
ts : {
$gt: new ISODate("2012-12-09T03:00:00Z"),
$lt: new ISODate("2012-12-09T03:40:00Z")
}
}).pretty()# 查询最近的10个慢查询日志
db.system.profile.find().limit(10).sort( { ts : -1 } ).pretty()
# 查询除命令类型为 ‘command’ 的日志
db.system.profile.find( { op: { $ne : 'command' } } ).pretty()
# 查询数据库为 mydb 集合为 test 的 日志
db.system.profile.find( { ns : 'mydb.test' } ).pretty()
# 查询 低于 5毫秒的日志
db.system.profile.find( { millis : { $gt : 5 } } ).pretty()
# 查询时间从 2012-12-09 3点整到 2012-12-09 3点40分之间的日志
db.system.profile.find({
ts : {
$gt: new ISODate("2012-12-09T03:00:00Z"),
$lt: new ISODate("2012-12-09T03:40:00Z")
}
}).pretty()- 排查方式
> use test
switched to db test
> db.stats()
>db.serverStatus()
#查看正在执行哪些语句
> db.currentOp()
{ "opid" : "shard3:466404288", "active" : false....}
#kill
>db.killOp("shard3:466404288")> use test
switched to db test
> db.stats()
>db.serverStatus()
#查看正在执行哪些语句
> db.currentOp()
{ "opid" : "shard3:466404288", "active" : false....}
#kill
>db.killOp("shard3:466404288")慢日志解析说明
官方文档:https://docs.mongodb.com/manual/reference/database-profiler/
- 部分说明
drug:PRIMARY> db.system.profile.find().pretty()
{
"op" : "query", #操作类型,有insert、query、update、remove、getmore、command
"ns" : "mc.user", #操作的集合
"query" : { #查询语句
"mp_id" : 5,
"is_fans" : 1,
"latestTime" : {
"$ne" : 0
},
"latestMsgId" : {
"$gt" : 0
},
"$where" : "new Date(this.latestNormalTime)>new Date(this.replyTime)"
},
"cursorid" : NumberLong("1475423943124458998"),
"ntoreturn" : 0, #返回的记录数。例如,profile命令将返回一个文档(一个结果文件),因此ntoreturn值将为1。limit(5)命令将返回五个文件,因此ntoreturn值是5。如果ntoreturn值为0,则该命令没有指定一些文件返回,因为会是这样一个简单的find()命令没有指定的限制。
"ntoskip" : 0, #skip()方法指定的跳跃数
"nscanned" : 304, #扫描数量
"keyUpdates" : 0, #索引更新的数量,改变一个索引键带有一个小的性能开销,因为数据库必须删除旧的key,并插入一个新的key到B-树索引
"numYield" : 0, #该查询为其他查询让出锁的次数
"lockStats" : { #锁信息,R:全局读锁;W:全局写锁;r:特定数据库的读锁;w:特定数据库的写锁
"timeLockedMicros" : { #锁
"r" : NumberLong(19467),
"w" : NumberLong(0)
},
"timeAcquiringMicros" : { #锁等待
"r" : NumberLong(7),
"w" : NumberLong(9)
}
},
"nreturned" : 101, #返回的数量
"responseLength" : 74659, #响应字节长度
"millis" : 19, #消耗的时间(毫秒)
"ts" : ISODate("2014-02-25T02:13:54.899Z"), #语句执行的时间
"client" : "127.0.0.1", #链接ip或则主机
"allUsers" : [ ],
"user" : "" #用户
}drug:PRIMARY> db.system.profile.find().pretty()
{
"op" : "query", #操作类型,有insert、query、update、remove、getmore、command
"ns" : "mc.user", #操作的集合
"query" : { #查询语句
"mp_id" : 5,
"is_fans" : 1,
"latestTime" : {
"$ne" : 0
},
"latestMsgId" : {
"$gt" : 0
},
"$where" : "new Date(this.latestNormalTime)>new Date(this.replyTime)"
},
"cursorid" : NumberLong("1475423943124458998"),
"ntoreturn" : 0, #返回的记录数。例如,profile命令将返回一个文档(一个结果文件),因此ntoreturn值将为1。limit(5)命令将返回五个文件,因此ntoreturn值是5。如果ntoreturn值为0,则该命令没有指定一些文件返回,因为会是这样一个简单的find()命令没有指定的限制。
"ntoskip" : 0, #skip()方法指定的跳跃数
"nscanned" : 304, #扫描数量
"keyUpdates" : 0, #索引更新的数量,改变一个索引键带有一个小的性能开销,因为数据库必须删除旧的key,并插入一个新的key到B-树索引
"numYield" : 0, #该查询为其他查询让出锁的次数
"lockStats" : { #锁信息,R:全局读锁;W:全局写锁;r:特定数据库的读锁;w:特定数据库的写锁
"timeLockedMicros" : { #锁
"r" : NumberLong(19467),
"w" : NumberLong(0)
},
"timeAcquiringMicros" : { #锁等待
"r" : NumberLong(7),
"w" : NumberLong(9)
}
},
"nreturned" : 101, #返回的数量
"responseLength" : 74659, #响应字节长度
"millis" : 19, #消耗的时间(毫秒)
"ts" : ISODate("2014-02-25T02:13:54.899Z"), #语句执行的时间
"client" : "127.0.0.1", #链接ip或则主机
"allUsers" : [ ],
"user" : "" #用户
}主要看:
ts:时间戳
info:具体的操作
millis:操作所花时间,毫秒
nscanned数很大,或者接近记录总数,那么可能没有用到索引查询。reslen很大,有可能返回没必要的字段。nreturned很大,那么有可能查询的时候没有加限制,加分页限制
mtool
https://blog.csdn.net/it_freshman/article/details/118583634
8.调用外shell脚本
cat test.sh
use testdb;
db.test.insert({"name":"user4"});
# mongo --port 27019 < test.shcat test.sh
use testdb;
db.test.insert({"name":"user4"});
# mongo --port 27019 < test.sh