 SRE文档
SRE文档1. etcd_exporter
1.1 介绍
etcd内置了metrics接口供收集数据,在etcd集群任意一台节点上可通过ip:2379/metrics检查是否能正常收集数据
1.2 部署
由于内置了mtrics,安装省略
1.访问
bash
#无证书情况下
curl -L http://localhost:2379/metrics#无证书情况下
curl -L http://localhost:2379/metrics- 有证书情况
bash
curl --cacert /etc/etcd/ssl/etcd-ca.pem --cert /etc/etcd/ssl/etcd.pem --key /etc/etcd/ssl/etcd-key.pem -k https://10.103.236.150:2379/metrics curl --cacert /etc/etcd/ssl/etcd-ca.pem --cert /etc/etcd/ssl/etcd.pem --key /etc/etcd/ssl/etcd-key.pem -k https://10.103.236.150:2379/metrics1.3 Prometheus采集
💡 说明
外置etcd
1.tls
yaml
- job_name: etcd
metrics_path: /metrics
scheme: https
tls_config:
ca_file: /etc/etcd/ssl/etcd-ca.pem
cert_file: /etc/etcd/ssl/etcd.pem
key_file: /etc/etcd/ssl/etcd-key.pem
static_configs:
- targets: [ '10.103.236.150:2379' ]
- targets: [ '10.103.236.151:2379' ]
- targets: [ '10.103.236.152:2379' ] - job_name: etcd
metrics_path: /metrics
scheme: https
tls_config:
ca_file: /etc/etcd/ssl/etcd-ca.pem
cert_file: /etc/etcd/ssl/etcd.pem
key_file: /etc/etcd/ssl/etcd-key.pem
static_configs:
- targets: [ '10.103.236.150:2379' ]
- targets: [ '10.103.236.151:2379' ]
- targets: [ '10.103.236.152:2379' ]- 热更新
curl -X POST http://127.0.0.1:9090/-/reloadcurl -X POST http://127.0.0.1:9090/-/reload2.insecure_tls
yaml
- job_name: "etcd"
scheme: https
tls_config:
insecure_skip_verify: true
static_configs:
- targets: ['10.103.236.150:2379','10.103.236.151:2379','10.103.236.152:2379']- job_name: "etcd"
scheme: https
tls_config:
insecure_skip_verify: true
static_configs:
- targets: ['10.103.236.150:2379','10.103.236.151:2379','10.103.236.152:2379']3.k8s
💡 说明
外置etcd
1.代理-推荐
1.创建代理
对于外置的 etcd 集群,或者以静态 pod 方式启动的 etcd 集群,都不会在 k8s 里创建 service,而 Prometheus 需要根据 service + endpoint 来抓取,因此需要手动创建
yaml
cat > etcd-svc-ep.yaml << EOF
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: monitor
labels:
k8s-app: etcd ## Kubernetes 会根据该标签和 Endpoints 资源关联
app.kubernetes.io/name: etcd ## Prometheus 会根据该标签服务发现到该服务
spec:
type: ClusterIP
clusterIP: None ## 设置为 None,不分配 Service IP
ports:
- name: port
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: monitor
labels:
k8s-app: etcd
subsets:
- addresses: ## 代理的应用IP地址列表
- ip: 10.103.236.150
- ip: 10.103.236.151
- ip: 10.103.236.152
ports:
- port: 2379 ## 代理的应用端口号
EOFcat > etcd-svc-ep.yaml << EOF
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: monitor
labels:
k8s-app: etcd ## Kubernetes 会根据该标签和 Endpoints 资源关联
app.kubernetes.io/name: etcd ## Prometheus 会根据该标签服务发现到该服务
spec:
type: ClusterIP
clusterIP: None ## 设置为 None,不分配 Service IP
ports:
- name: port
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: monitor
labels:
k8s-app: etcd
subsets:
- addresses: ## 代理的应用IP地址列表
- ip: 10.103.236.150
- ip: 10.103.236.151
- ip: 10.103.236.152
ports:
- port: 2379 ## 代理的应用端口号
EOFbash
kubectl apply -f etcd-svc-ep.yamlkubectl apply -f etcd-svc-ep.yaml2.创建 secret 存储证书
bash
kubectl -n monitor create secret generic etcd-ssl --from-file=/etc/etcd/ssl/etcd-ca.pem --from-file=/etc/etcd/ssl/etcd.pem --from-file=/etc/etcd/ssl/etcd-key.pemkubectl -n monitor create secret generic etcd-ssl --from-file=/etc/etcd/ssl/etcd-ca.pem --from-file=/etc/etcd/ssl/etcd.pem --from-file=/etc/etcd/ssl/etcd-key.pem- 查看
bash
kubectl get secret -nmonitor
NAME TYPE DATA AGE
etcd-ssl Opaque 3 77skubectl get secret -nmonitor
NAME TYPE DATA AGE
etcd-ssl Opaque 3 77s3.修改prometheus配置
yaml
volumeMounts:
- name: certs #### 将ETCD证书的ConfigMap挂进Prometheus容器
mountPath: /certs
readOnly: true
volumes:
- name: certs #### 将ETCD证书的ConfigMap挂进Prometheus容器
secret:
secretName: etcd-ssl volumeMounts:
- name: certs #### 将ETCD证书的ConfigMap挂进Prometheus容器
mountPath: /certs
readOnly: true
volumes:
- name: certs #### 将ETCD证书的ConfigMap挂进Prometheus容器
secret:
secretName: etcd-ssl4.配置采集
yaml
###################### kubernetes-etcd ######################
- job_name: "kubernetes-etcd"
scheme: https
tls_config:
## 配置 ETCD 证书所在路径(Prometheus 容器内的文件路径)
ca_file: /certs/etcd-ca.pem
cert_file: /certs/etcd.pem
key_file: /certs/etcd-key.pem
insecure_skip_verify: false
kubernetes_sd_configs:
## 配置服务发现机制,指定 ETCD Service 所在的Namespace名称
- role: endpoints
namespaces:
names: ["monitor"]
relabel_configs:
## 指定从 app.kubernetes.io/name 标签等于 etcd 的 service 服务获取指标信息
- action: keep
source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_name]
regex: etcd###################### kubernetes-etcd ######################
- job_name: "kubernetes-etcd"
scheme: https
tls_config:
## 配置 ETCD 证书所在路径(Prometheus 容器内的文件路径)
ca_file: /certs/etcd-ca.pem
cert_file: /certs/etcd.pem
key_file: /certs/etcd-key.pem
insecure_skip_verify: false
kubernetes_sd_configs:
## 配置服务发现机制,指定 ETCD Service 所在的Namespace名称
- role: endpoints
namespaces:
names: ["monitor"]
relabel_configs:
## 指定从 app.kubernetes.io/name 标签等于 etcd 的 service 服务获取指标信息
- action: keep
source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_name]
regex: etcd- 更新服务
bash
kubectl apply -f 6.prometheus-deploy.yamlkubectl apply -f 6.prometheus-deploy.yaml- 热更新
bash
curl -XPOST http://prometheus.ikubernetes.net/-/reloadcurl -XPOST http://prometheus.ikubernetes.net/-/reload- 效果
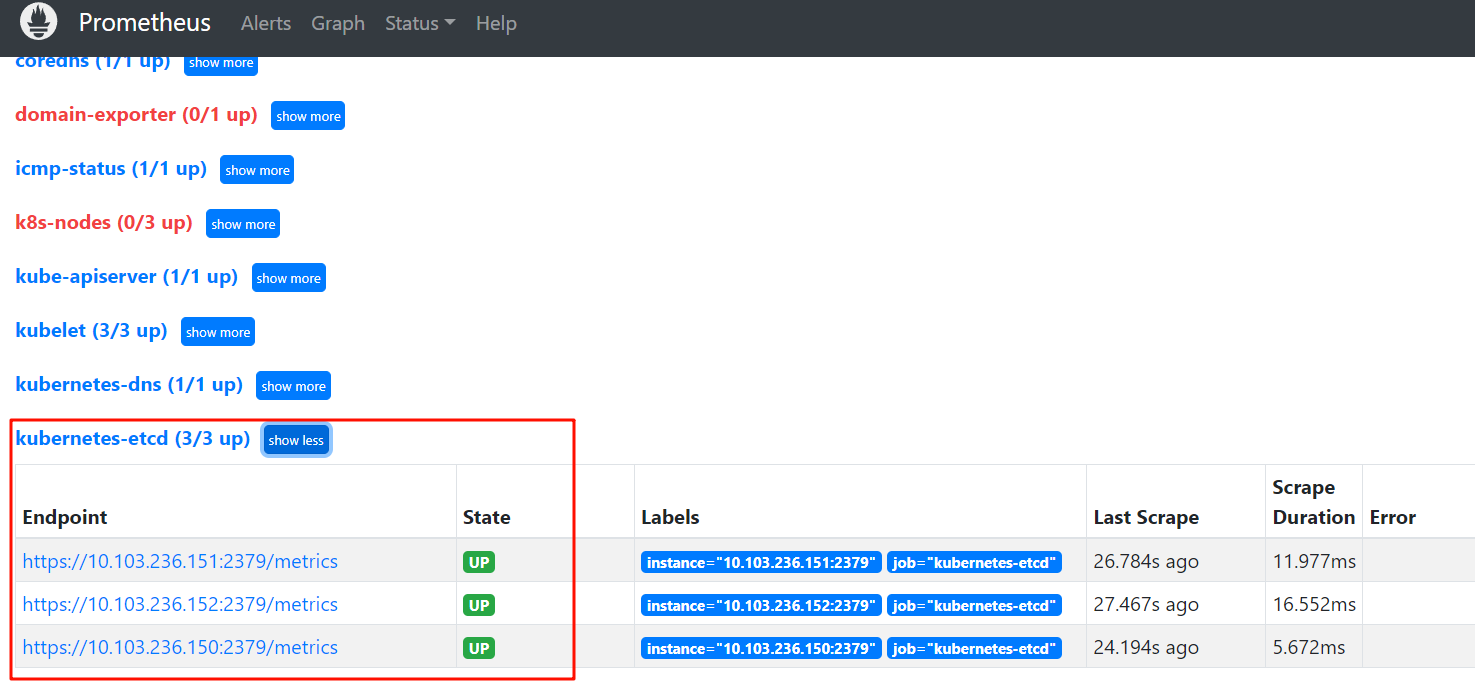
2.非代理
1.配置采集
yaml
- job_name: etcd_external
metrics_path: /metrics
scheme: https
tls_config:
ca_file: /certs/etcd-ca.pem
cert_file: /certs/etcd.pem
key_file: /certs/etcd-key.pem
insecure_skip_verify: false
static_configs:
- targets: [ '10.103.236.150:2379' ]
- targets: [ '10.103.236.151:2379' ]
- targets: [ '10.103.236.152:2379' ] - job_name: etcd_external
metrics_path: /metrics
scheme: https
tls_config:
ca_file: /certs/etcd-ca.pem
cert_file: /certs/etcd.pem
key_file: /certs/etcd-key.pem
insecure_skip_verify: false
static_configs:
- targets: [ '10.103.236.150:2379' ]
- targets: [ '10.103.236.151:2379' ]
- targets: [ '10.103.236.152:2379' ]2.创建 secret 存储证书
bash
kubectl -n monitor create secret generic etcd-ssl --from-file=/etc/etcd/ssl/etcd-ca.pem --from-file=/etc/etcd/ssl/etcd.pem --from-file=/etc/etcd/ssl/etcd-key.pemkubectl -n monitor create secret generic etcd-ssl --from-file=/etc/etcd/ssl/etcd-ca.pem --from-file=/etc/etcd/ssl/etcd.pem --from-file=/etc/etcd/ssl/etcd-key.pem3.修改prometheus配置
yaml
volumeMounts:
- name: certs #### 将ETCD证书的ConfigMap挂进Prometheus容器
mountPath: /certs
readOnly: true
volumes:
- name: certs #### 将ETCD证书的ConfigMap挂进Prometheus容器
secret:
secretName: etcd-ssl volumeMounts:
- name: certs #### 将ETCD证书的ConfigMap挂进Prometheus容器
mountPath: /certs
readOnly: true
volumes:
- name: certs #### 将ETCD证书的ConfigMap挂进Prometheus容器
secret:
secretName: etcd-ssl- 更新服务
bash
kubectl apply -f 6.prometheus-deploy.yamlkubectl apply -f 6.prometheus-deploy.yaml- 热更新
bash
curl -XPOST http://prometheus.ikubernetes.net/-/reloadcurl -XPOST http://prometheus.ikubernetes.net/-/reload- 效果
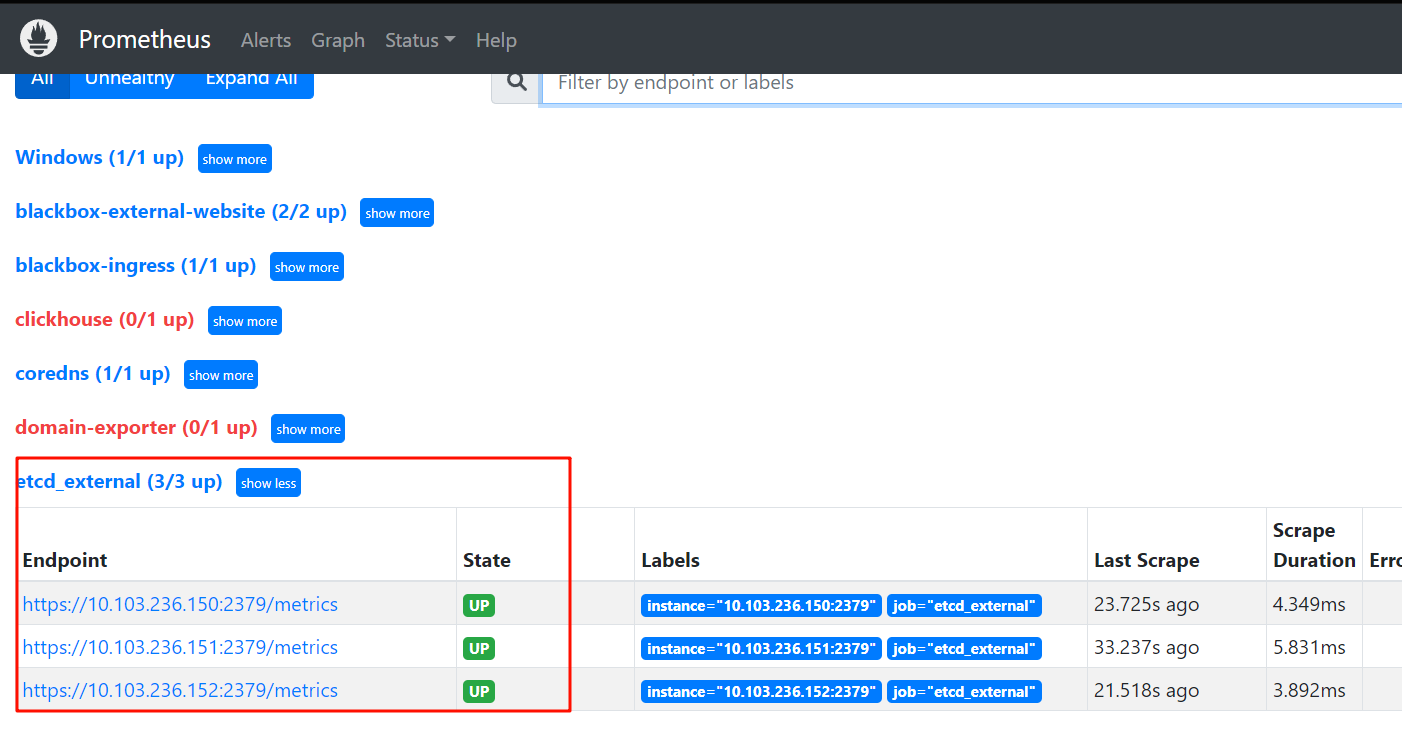
4. 报警规则
监视指标,例如etcd_debugging_mvcc_db_total_size_in_bytes,etcd_debugging_mvcc_keys_total和etcd_debugging_store_expires_total
1.规则
# 当前存活的 etcd 节点数是否小于 (n+1)/2
sum(up{job=~".\*etcd.\*"} == bool 1) by (job) < ((count(up{job=~".\*etcd.\*"}) by (job) + 1) / 2)
# etcd 是否存在 leader,为 0 则表示不存在 leader,表示集群不可用
etcd_server_has_leader{job=~".\*etcd.\*"} == 0
# 15 分钟 内集群 leader 切换次数是否超过 3 次
rate(etcd_server_leader_changes_seen_total{job=~".\*etcd.\*"}[15m]) > 3
# 5 分钟内 WAL fsync 调用延迟 p99 大于 500ms
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.5
# 5 分钟内 DB fsync 调用延迟 p99 大于 500ms
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.25
# 5 分钟内 节点之间 RTT 大于 500 ms
histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5# 当前存活的 etcd 节点数是否小于 (n+1)/2
sum(up{job=~".\*etcd.\*"} == bool 1) by (job) < ((count(up{job=~".\*etcd.\*"}) by (job) + 1) / 2)
# etcd 是否存在 leader,为 0 则表示不存在 leader,表示集群不可用
etcd_server_has_leader{job=~".\*etcd.\*"} == 0
# 15 分钟 内集群 leader 切换次数是否超过 3 次
rate(etcd_server_leader_changes_seen_total{job=~".\*etcd.\*"}[15m]) > 3
# 5 分钟内 WAL fsync 调用延迟 p99 大于 500ms
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.5
# 5 分钟内 DB fsync 调用延迟 p99 大于 500ms
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.25
# 5 分钟内 节点之间 RTT 大于 500 ms
histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5yaml
# these rules synced manually from https://github.com/etcd-io/etcd/blob/master/Documentation/etcd-mixin/mixin.libsonnet
groups:
- name: etcd
rules:
- alert: etcd_InsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcd_NoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has
no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcd_HighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fync durations are
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcd_HighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcd_HighNodeRTTDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": node RTT durations'
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5
for: 10m
labels:
severity: warning# these rules synced manually from https://github.com/etcd-io/etcd/blob/master/Documentation/etcd-mixin/mixin.libsonnet
groups:
- name: etcd
rules:
- alert: etcd_InsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcd_NoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has
no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcd_HighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fync durations are
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcd_HighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcd_HighNodeRTTDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": node RTT durations'
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5
for: 10m
labels:
severity: warning完整
yaml
# These rules were manually synced from https://github.com/etcd-io/etcd/blob/master/contrib/mixin/mixin.libsonnet
groups:
- name: etcd
rules:
- alert: etcdInsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has
no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighNumberOfLeaderChanges
annotations:
message: 'etcd cluster "{{ $labels.job }}": instance {{ $labels.instance }}
has seen {{ $value }} leader changes within the last hour.'
expr: |
rate(etcd_server_leader_changes_seen_total{job=~".*etcd.*"}[15m]) > 3
for: 15m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.'
expr: |
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
> 1
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.'
expr: |
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
> 5
for: 5m
labels:
severity: critical
- alert: etcdGRPCRequestsSlow
annotations:
message: 'etcd cluster "{{ $labels.job }}": gRPC requests to {{ $labels.grpc_method
}} are taking {{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, sum(rate(grpc_server_handling_seconds_bucket{job=~".*etcd.*", grpc_type="unary"}[5m])) by (job, instance, grpc_service, grpc_method, le))
> 0.15
for: 10m
labels:
severity: critical
- alert: etcdMemberCommunicationSlow
annotations:
message: 'etcd cluster "{{ $labels.job }}": member communication with {{ $labels.To
}} is taking {{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.15
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedProposals
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }} proposal failures within
the last hour on etcd instance {{ $labels.instance }}.'
expr: |
rate(etcd_server_proposals_failed_total{job=~".*etcd.*"}[15m]) > 5
for: 15m
labels:
severity: warning
- alert: etcdHighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fync durations are
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcdHighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedHTTPRequests
annotations:
message: '{{ $value }}% of requests for {{ $labels.method }} failed on etcd
instance {{ $labels.instance }}'
expr: |
sum(rate(etcd_http_failed_total{job=~".*etcd.*", code!="404"}[5m])) BY (method) / sum(rate(etcd_http_received_total{job=~".*etcd.*"}[5m]))
BY (method) > 0.01
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedHTTPRequests
annotations:
message: '{{ $value }}% of requests for {{ $labels.method }} failed on etcd
instance {{ $labels.instance }}.'
expr: |
sum(rate(etcd_http_failed_total{job=~".*etcd.*", code!="404"}[5m])) BY (method) / sum(rate(etcd_http_received_total{job=~".*etcd.*"}[5m]))
BY (method) > 0.05
for: 10m
labels:
severity: critical
- alert: etcdHTTPRequestsSlow
annotations:
message: etcd instance {{ $labels.instance }} HTTP requests to {{ $labels.method
}} are slow.
expr: |
histogram_quantile(0.99, rate(etcd_http_successful_duration_seconds_bucket[5m]))
> 0.15
for: 10m
labels:
severity: warning# These rules were manually synced from https://github.com/etcd-io/etcd/blob/master/contrib/mixin/mixin.libsonnet
groups:
- name: etcd
rules:
- alert: etcdInsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has
no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighNumberOfLeaderChanges
annotations:
message: 'etcd cluster "{{ $labels.job }}": instance {{ $labels.instance }}
has seen {{ $value }} leader changes within the last hour.'
expr: |
rate(etcd_server_leader_changes_seen_total{job=~".*etcd.*"}[15m]) > 3
for: 15m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.'
expr: |
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
> 1
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.'
expr: |
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
> 5
for: 5m
labels:
severity: critical
- alert: etcdGRPCRequestsSlow
annotations:
message: 'etcd cluster "{{ $labels.job }}": gRPC requests to {{ $labels.grpc_method
}} are taking {{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, sum(rate(grpc_server_handling_seconds_bucket{job=~".*etcd.*", grpc_type="unary"}[5m])) by (job, instance, grpc_service, grpc_method, le))
> 0.15
for: 10m
labels:
severity: critical
- alert: etcdMemberCommunicationSlow
annotations:
message: 'etcd cluster "{{ $labels.job }}": member communication with {{ $labels.To
}} is taking {{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.15
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedProposals
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }} proposal failures within
the last hour on etcd instance {{ $labels.instance }}.'
expr: |
rate(etcd_server_proposals_failed_total{job=~".*etcd.*"}[15m]) > 5
for: 15m
labels:
severity: warning
- alert: etcdHighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fync durations are
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcdHighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedHTTPRequests
annotations:
message: '{{ $value }}% of requests for {{ $labels.method }} failed on etcd
instance {{ $labels.instance }}'
expr: |
sum(rate(etcd_http_failed_total{job=~".*etcd.*", code!="404"}[5m])) BY (method) / sum(rate(etcd_http_received_total{job=~".*etcd.*"}[5m]))
BY (method) > 0.01
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedHTTPRequests
annotations:
message: '{{ $value }}% of requests for {{ $labels.method }} failed on etcd
instance {{ $labels.instance }}.'
expr: |
sum(rate(etcd_http_failed_total{job=~".*etcd.*", code!="404"}[5m])) BY (method) / sum(rate(etcd_http_received_total{job=~".*etcd.*"}[5m]))
BY (method) > 0.05
for: 10m
labels:
severity: critical
- alert: etcdHTTPRequestsSlow
annotations:
message: etcd instance {{ $labels.instance }} HTTP requests to {{ $labels.method
}} are slow.
expr: |
histogram_quantile(0.99, rate(etcd_http_successful_duration_seconds_bucket[5m]))
> 0.15
for: 10m
labels:
severity: warning1.4 grafana
默认搜索,https://grafana.com/grafana/dashboards/
导入模板9733