 SRE文档
SRE文档1. Pod中断原因
Kubernetes 集群中,业务通常采用 Deployment + LoadBalancer 类型 Service 的方式对外提供服务
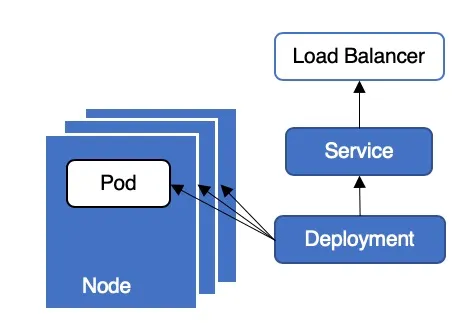
1.1 新建pod
Pod running 后被加入到 Endpoint 后端,容器服务监控到 Endpoint 变更后将 Node 加入到 SLB 后端。此时请求从 SLB 转发到 Pod 中,但是 Pod 业务代码还未初始化完毕,无法处理请求,导致服务中断
1.2 删除pod
在删除旧 pod 过程中需要对多个对象(如 Endpoint、ipvs/iptables、SLB)进行状态同步,并且这些同步操作是异步执行的
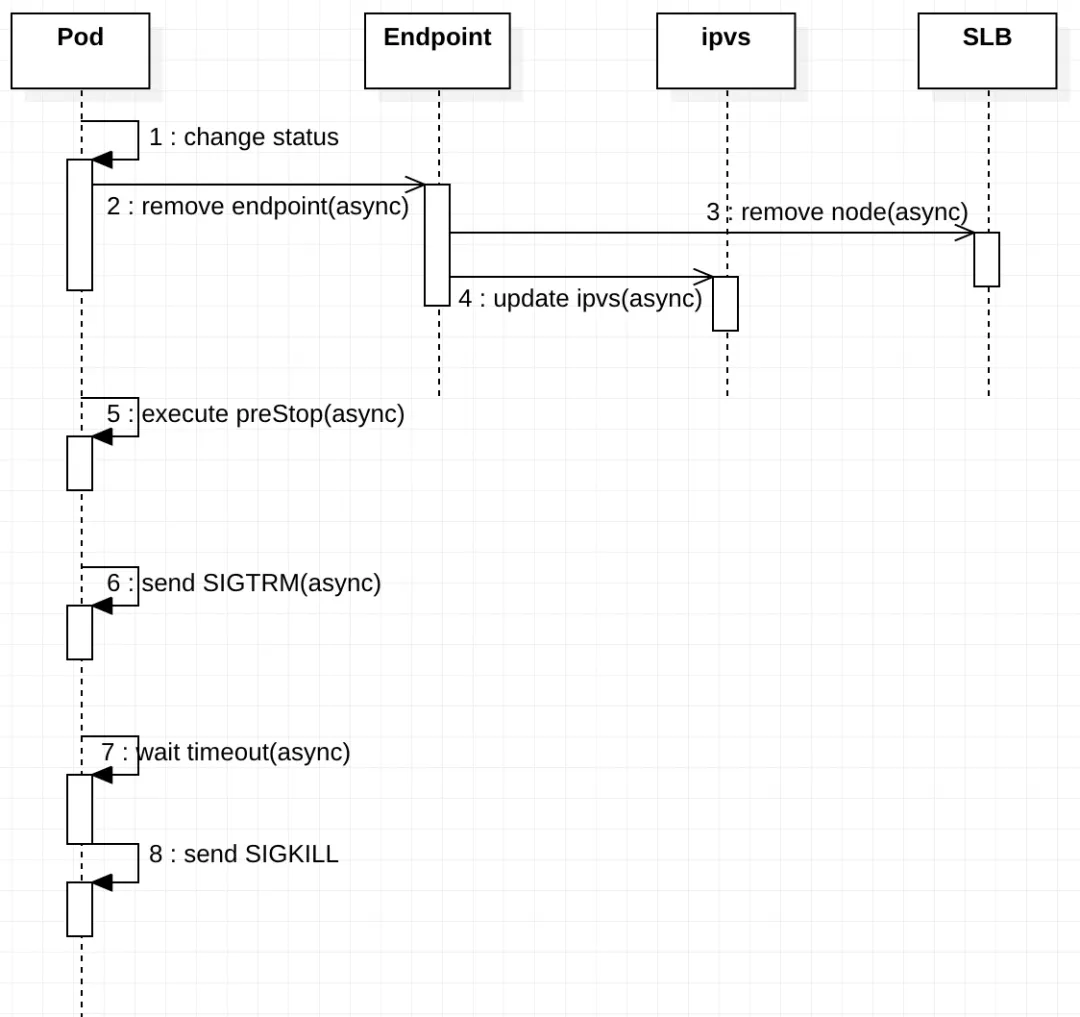
Pod
- pod 状态变更:将 Pod 设置为 Terminating 状态,并从所有 Service 的 Endpoints 列表中删除。此时,Pod 停止获得新的流量,但在 Pod 中运行的容器不会受到影响;
- 执行 preStop Hook:Pod 删除时会触发 preStop Hook,preStop Hook 支持 bash 脚本、TCP 或 HTTP 请求;
- 发送 SIGTERM 信号:向 Pod 中的容器发送 SIGTERM 信号;
- 等待指定的时间:terminationGracePeriodSeconds 字段用于控制等待时间,默认值为 30 秒。该步骤与 preStop Hook 同时执行,因此 terminationGracePeriodSeconds 需要大于 preStop 的时间,否则会出现 preStop 未执行完毕,pod 就被 kill 的情况;
- 发送 SIGKILL 信号:等待指定时间后,向 pod 中的容器发送 SIGKILL 信号,删除 pod。
中断原因:上述 1、2、3、4 步骤同时进行,因此有可能存在 Pod 收到 SIGTERM 信号并且停止工作后,还未从 Endpoints 中移除的情况。此时,请求从 slb 转发到 pod 中,而 Pod 已经停止工作,因此会出现服务中断
1.3 iptables/ipvs
中断原因:当 pod 变为 termintaing 状态时,会从所有 service 的 endpoint 中移除该 pod。kube-proxy 会清理对应的 iptables/ipvs 条目。而容器服务 watch 到 endpoint 变化后,会调用 slb openapi 移除后端,此操作会耗费几秒。由于这两个操作是同时进行,因此有可能存在节点上的 iptables/ipvs 条目已经被清理,但是节点还未从 slb 移除的情况。此时,流量从 slb 流入,而节点上已经没有对应的 iptables/ipvs 规则导致服务中断
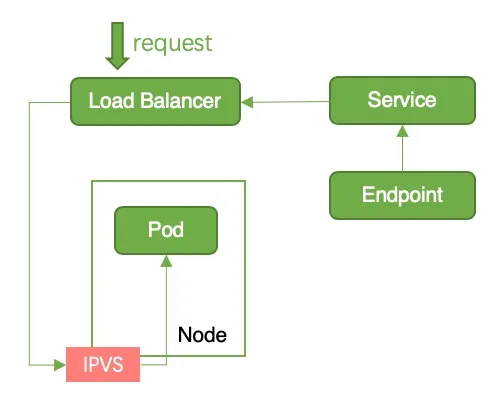
1.4 SLB
中断原因:容器服务监控到 Endpoints 变化后,会将 Node 从 slb 后端移除。当节点从 slb 后端移除后,SLB 对于继续发往该节点的长连接会直接断开,导致服务中断。
2. Pod配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: default
strategy:
rollingUpdate:
maxSurge: 50%
maxUnavailable: 0% #为0,保证有新的Pod启动后才停止之前的pod
type: RollingUpdate
spec:
terminationGracePeriodSeconds: 60 #默认30
containers:
- name: nginx
image: nginx
# 存活检测
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
tcpSocket:
port: 5084
timeoutSeconds: 1
# 就绪检测
readinessProbe:
initialDelaySeconds: 30 # 在开始就绪检查之前等待 30s
periodSeconds: 20 # 每 20 秒检查一次
failureThreshold: 3 # 在连续 3 次失败后将 Pod 标记为未就绪
successThreshold: 1
timeoutSeconds: 10 # 允许响应最多 10 秒
tcpSocket:
port: 5084
# 优雅退出,command这里根据业务进行修改
lifecycle:
preStop:
exec:
command:
- sleep
- 30apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: default
strategy:
rollingUpdate:
maxSurge: 50%
maxUnavailable: 0% #为0,保证有新的Pod启动后才停止之前的pod
type: RollingUpdate
spec:
terminationGracePeriodSeconds: 60 #默认30
containers:
- name: nginx
image: nginx
# 存活检测
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
tcpSocket:
port: 5084
timeoutSeconds: 1
# 就绪检测
readinessProbe:
initialDelaySeconds: 30 # 在开始就绪检查之前等待 30s
periodSeconds: 20 # 每 20 秒检查一次
failureThreshold: 3 # 在连续 3 次失败后将 Pod 标记为未就绪
successThreshold: 1
timeoutSeconds: 10 # 允许响应最多 10 秒
tcpSocket:
port: 5084
# 优雅退出,command这里根据业务进行修改
lifecycle:
preStop:
exec:
command:
- sleep
- 301.springboot案例
简单点就是:
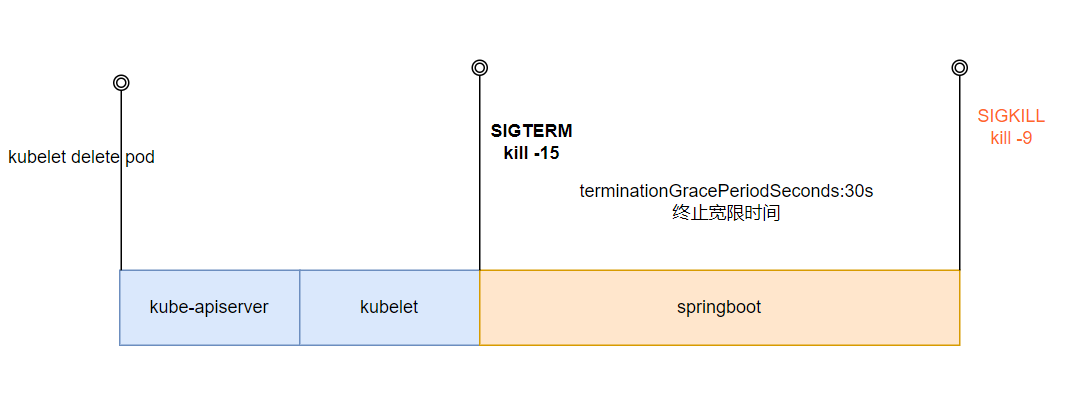
- Kube-apiserver接收到pod的删除请求,在Etcd上更新pod的状态为Terminating;
- Kubelet 清理节点上容器相关的资源,如存储、网络;
- Kubelet向容器发送SIGTERM,如果容器内进程没有任何配置,则容器立即退出。
- 如果容器在默认的 30 秒内没有退出,Kubelet 将发送 SIGKILL 并强制其退出。
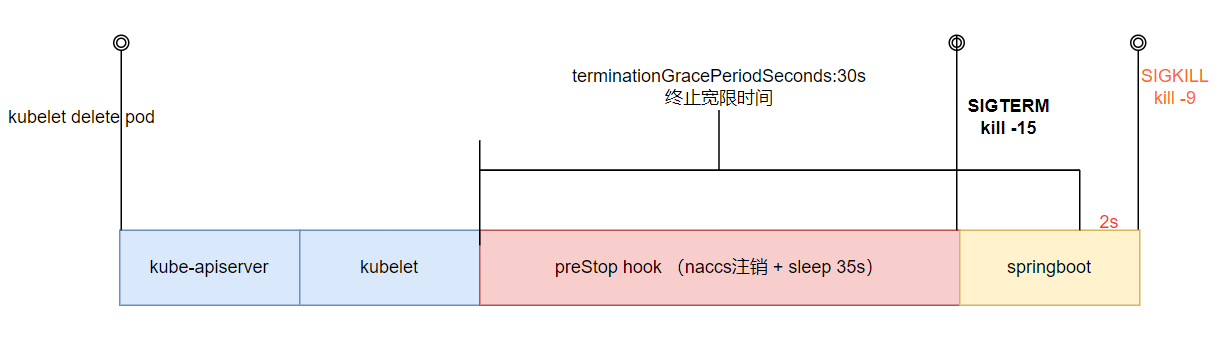
hook,和将终止宽限期延长,具体实现如下:
- preStop hook做了两件事情:
1)nacos反注册(也称 实例注销),确保在实例关闭期间不会再有新的请求被路由到该实例。
- sleep 35s,nacos客户端的实例缓存为30s,30s后会重新拉取实例信息,超时为10s,一般不用10s这么长,所以我们设置为35s。
- springboot开启优雅停机后,最大等待时间为30s。
- terminationGracePeriodSeconds默认为30s,远小于preStop和springboot的时间之和,所以我们需要将其调大,我这里设置的是60s。
- 其实在terminationGracePeriodSeconds耗尽后,k8s还给了一个2s的额外宽限期,最后才执行SIGKILL。
在SpringBoot > 2.3.0的版本后支持应用程序优雅停机,需要在java微服务的配置中设置如下两个属性
server:
# 默认值immediate:即立即关闭,graceful:即优雅停机
shutdown: graceful
spring:
lifecycle:
# 优雅停机最大等待时间,默认30s
timeout-per-shutdown-phase: 30sserver:
# 默认值immediate:即立即关闭,graceful:即优雅停机
shutdown: graceful
spring:
lifecycle:
# 优雅停机最大等待时间,默认30s
timeout-per-shutdown-phase: 30s通过env定义POD_IP获取当前Pod的ip,传递给preStop进行nacos反注册
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: pod1
image: image
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
lifecycle:
preStop:
exec:
command:
- /bin/sh
- '-c'
- >
curl -s --connect-timeout 10 -m 20 -X POST "http://svc:8848/nacos/v1/ns/instance?port=8080&healthy=true&ip=${POD_IP}&weight=1&enabled=false&serviceName=sre-yilingyi&encoding=GBK&namespaceId=production" && sleep 35
terminationGracePeriodSeconds: 60apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: pod1
image: image
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
lifecycle:
preStop:
exec:
command:
- /bin/sh
- '-c'
- >
curl -s --connect-timeout 10 -m 20 -X POST "http://svc:8848/nacos/v1/ns/instance?port=8080&healthy=true&ip=${POD_IP}&weight=1&enabled=false&serviceName=sre-yilingyi&encoding=GBK&namespaceId=production" && sleep 35
terminationGracePeriodSeconds: 60